 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAB/BA analysis: A framework for estimating keyword spotting recall improvement while maintaining audio privacy
Apr 18, 2022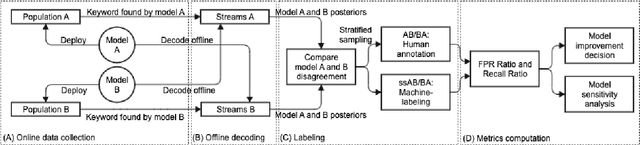

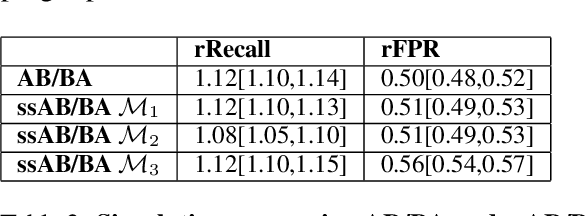
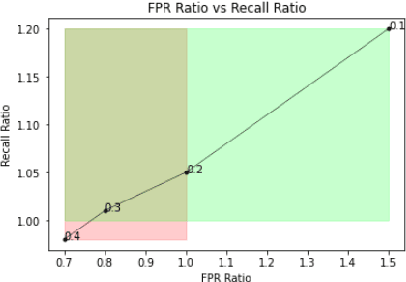
Evaluation of keyword spotting (KWS) systems that detect keywords in speech is a challenging task under realistic privacy constraints. The KWS is designed to only collect data when the keyword is present, limiting the availability of hard samples that may contain false negatives, and preventing direct estimation of model recall from production data. Alternatively, complementary data collected from other sources may not be fully representative of the real application. In this work, we propose an evaluation technique which we call AB/BA analysis. Our framework evaluates a candidate KWS model B against a baseline model A, using cross-dataset offline decoding for relative recall estimation, without requiring negative examples. Moreover, we propose a formulation with assumptions that allow estimation of relative false positive rate between models with low variance even when the number of false positives is small. Finally, we propose to leverage machine-generated soft labels, in a technique we call Semi-Supervised AB/BA analysis, that improves the analysis time, privacy, and cost. Experiments with both simulation and real data show that AB/BA analysis is successful at measuring recall improvement in conjunction with the trade-off in relative false positive rate.
Predicting Exploitation of Disclosed Software Vulnerabilities Using Open-source Data
Jul 25, 2017
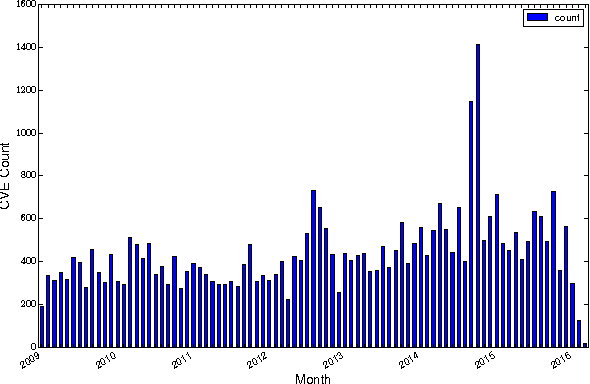
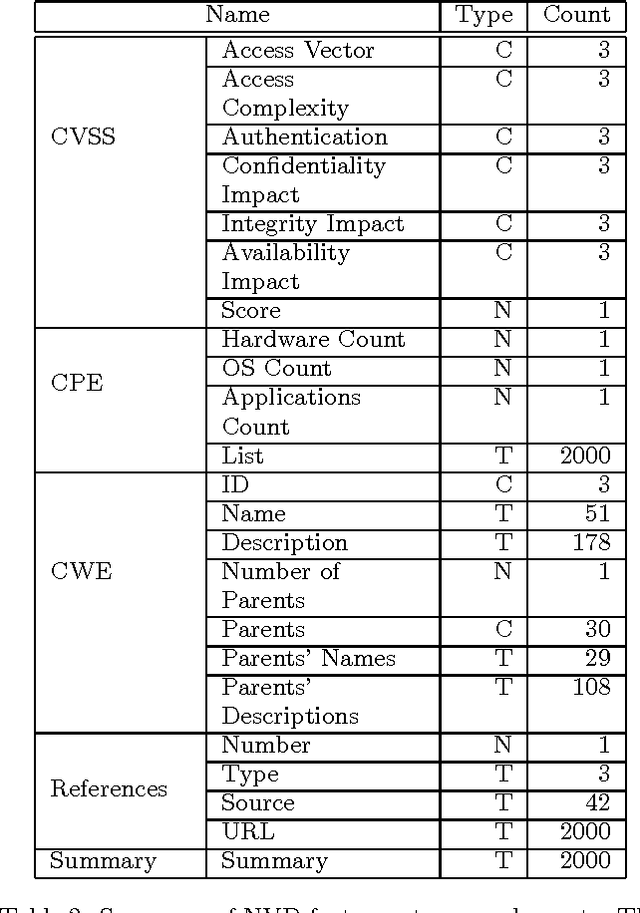
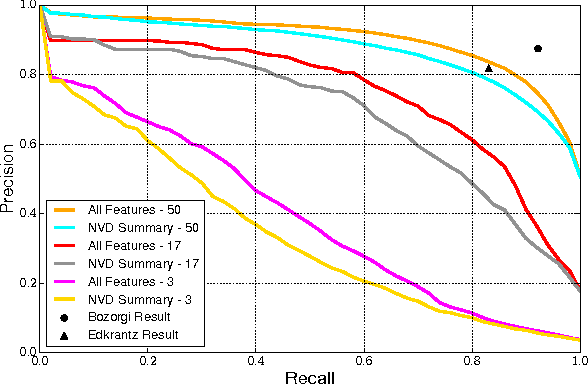
Each year, thousands of software vulnerabilities are discovered and reported to the public. Unpatched known vulnerabilities are a significant security risk. It is imperative that software vendors quickly provide patches once vulnerabilities are known and users quickly install those patches as soon as they are available. However, most vulnerabilities are never actually exploited. Since writing, testing, and installing software patches can involve considerable resources, it would be desirable to prioritize the remediation of vulnerabilities that are likely to be exploited. Several published research studies have reported moderate success in applying machine learning techniques to the task of predicting whether a vulnerability will be exploited. These approaches typically use features derived from vulnerability databases (such as the summary text describing the vulnerability) or social media posts that mention the vulnerability by name. However, these prior studies share multiple methodological shortcomings that inflate predictive power of these approaches. We replicate key portions of the prior work, compare their approaches, and show how selection of training and test data critically affect the estimated performance of predictive models. The results of this study point to important methodological considerations that should be taken into account so that results reflect real-world utility.