 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLil: Less is Less When Applying Post-Training Sparse-Attention Algorithms in Long-Decode Stage
Jan 06, 2026Large language models (LLMs) demonstrate strong capabilities across a wide range of complex tasks and are increasingly deployed at scale, placing significant demands on inference efficiency. Prior work typically decomposes inference into prefill and decode stages, with the decode stage dominating total latency. To reduce time and memory complexity in the decode stage, a line of work introduces sparse-attention algorithms. In this paper, we show, both empirically and theoretically, that sparse attention can paradoxically increase end-to-end complexity: information loss often induces significantly longer sequences, a phenomenon we term ``Less is Less'' (Lil). To mitigate the Lil problem, we propose an early-stopping algorithm that detects the threshold where information loss exceeds information gain during sparse decoding. Our early-stopping algorithm reduces token consumption by up to 90% with a marginal accuracy degradation of less than 2% across reasoning-intensive benchmarks.
Safety and Performance, Why Not Both? Bi-Objective Optimized Model Compression against Heterogeneous Attacks Toward AI Software Deployment
Jan 02, 2024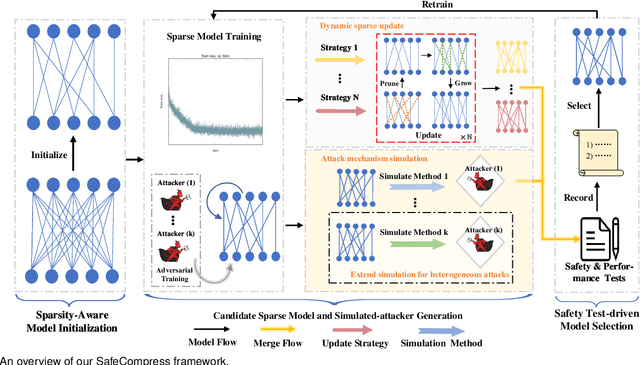
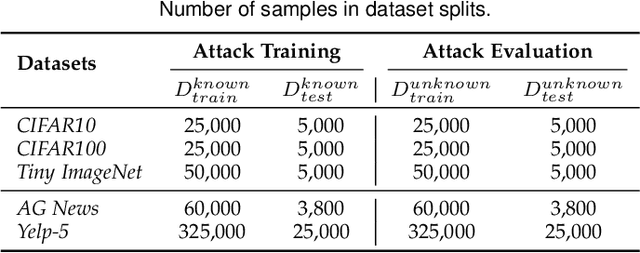
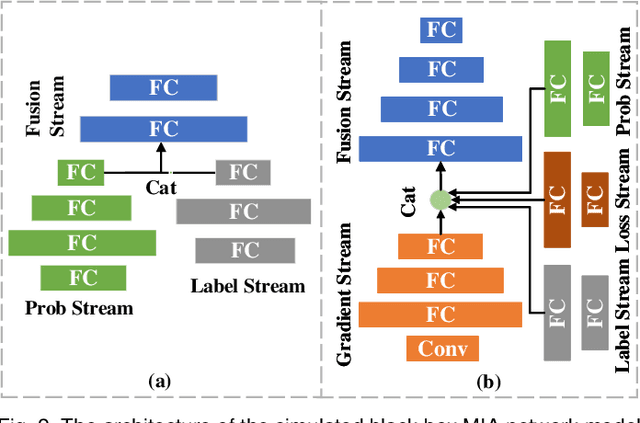
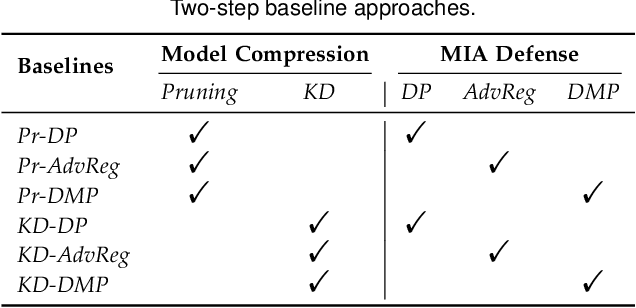
The size of deep learning models in artificial intelligence (AI) software is increasing rapidly, hindering the large-scale deployment on resource-restricted devices (e.g., smartphones). To mitigate this issue, AI software compression plays a crucial role, which aims to compress model size while keeping high performance. However, the intrinsic defects in a big model may be inherited by the compressed one. Such defects may be easily leveraged by adversaries, since a compressed model is usually deployed in a large number of devices without adequate protection. In this article, we aim to address the safe model compression problem from the perspective of safety-performance co-optimization. Specifically, inspired by the test-driven development (TDD) paradigm in software engineering, we propose a test-driven sparse training framework called SafeCompress. By simulating the attack mechanism as safety testing, SafeCompress can automatically compress a big model to a small one following the dynamic sparse training paradigm. Then, considering two kinds of representative and heterogeneous attack mechanisms, i.e., black-box membership inference attack and white-box membership inference attack, we develop two concrete instances called BMIA-SafeCompress and WMIA-SafeCompress. Further, we implement another instance called MMIA-SafeCompress by extending SafeCompress to defend against the occasion when adversaries conduct black-box and white-box membership inference attacks simultaneously. We conduct extensive experiments on five datasets for both computer vision and natural language processing tasks. The results show the effectiveness and generalizability of our framework. We also discuss how to adapt SafeCompress to other attacks besides membership inference attack, demonstrating the flexibility of SafeCompress.
Sampling-based Fast Gradient Rescaling Method for Highly Transferable Adversarial Attacks
Jul 06, 2023



Deep neural networks are known to be vulnerable to adversarial examples crafted by adding human-imperceptible perturbations to the benign input. After achieving nearly 100% attack success rates in white-box setting, more focus is shifted to black-box attacks, of which the transferability of adversarial examples has gained significant attention. In either case, the common gradient-based methods generally use the sign function to generate perturbations on the gradient update, that offers a roughly correct direction and has gained great success. But little work pays attention to its possible limitation. In this work, we observe that the deviation between the original gradient and the generated noise may lead to inaccurate gradient update estimation and suboptimal solutions for adversarial transferability. To this end, we propose a Sampling-based Fast Gradient Rescaling Method (S-FGRM). Specifically, we use data rescaling to substitute the sign function without extra computational cost. We further propose a Depth First Sampling method to eliminate the fluctuation of rescaling and stabilize the gradient update. Our method could be used in any gradient-based attacks and is extensible to be integrated with various input transformation or ensemble methods to further improve the adversarial transferability. Extensive experiments on the standard ImageNet dataset show that our method could significantly boost the transferability of gradient-based attacks and outperform the state-of-the-art baselines.