 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeThR-Net: A Generalized Temporally Hybrid Recurrent Neural Network for Multimodal Information Fusion
Sep 17, 2016

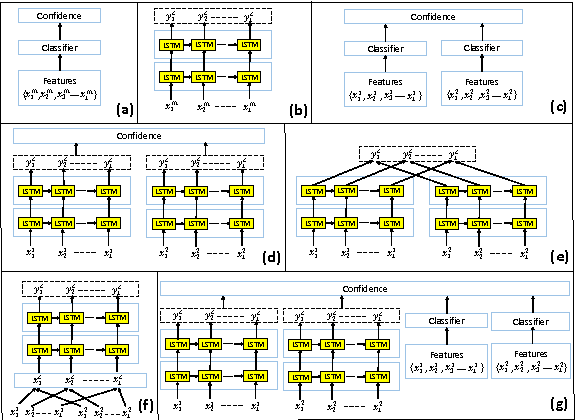

Data generated from real world events are usually temporal and contain multimodal information such as audio, visual, depth, sensor etc. which are required to be intelligently combined for classification tasks. In this paper, we propose a novel generalized deep neural network architecture where temporal streams from multiple modalities are combined. There are total M+1 (M is the number of modalities) components in the proposed network. The first component is a novel temporally hybrid Recurrent Neural Network (RNN) that exploits the complimentary nature of the multimodal temporal information by allowing the network to learn both modality specific temporal dynamics as well as the dynamics in a multimodal feature space. M additional components are added to the network which extract discriminative but non-temporal cues from each modality. Finally, the predictions from all of these components are linearly combined using a set of automatically learned weights. We perform exhaustive experiments on three different datasets spanning four modalities. The proposed network is relatively 3.5%, 5.7% and 2% better than the best performing temporal multimodal baseline for UCF-101, CCV and Multimodal Gesture datasets respectively.
Weakly Supervised Learning of Heterogeneous Concepts in Videos
Jul 12, 2016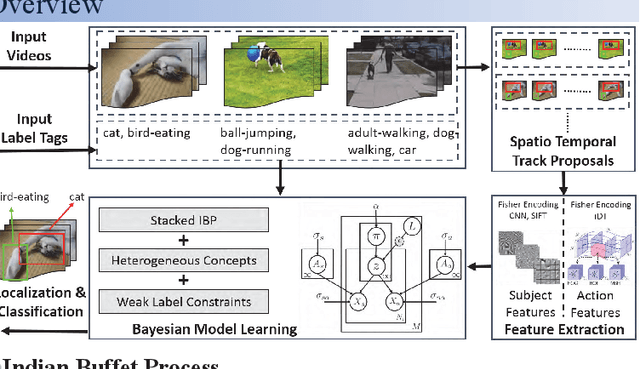
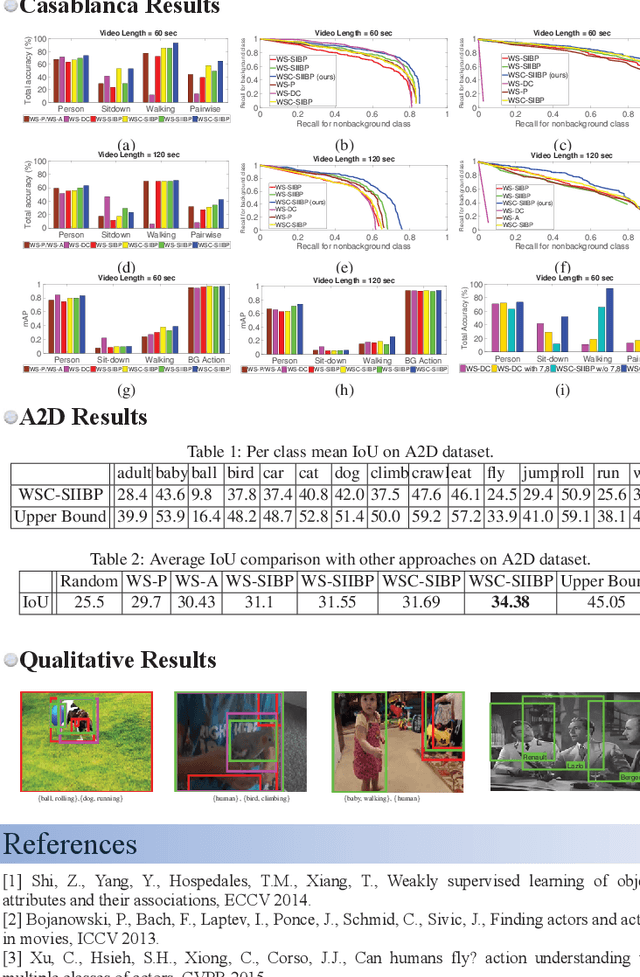
Typical textual descriptions that accompany online videos are 'weak': i.e., they mention the main concepts in the video but not their corresponding spatio-temporal locations. The concepts in the description are typically heterogeneous (e.g., objects, persons, actions). Certain location constraints on these concepts can also be inferred from the description. The goal of this paper is to present a generalization of the Indian Buffet Process (IBP) that can (a) systematically incorporate heterogeneous concepts in an integrated framework, and (b) enforce location constraints, for efficient classification and localization of the concepts in the videos. Finally, we develop posterior inference for the proposed formulation using mean-field variational approximation. Comparative evaluations on the Casablanca and the A2D datasets show that the proposed approach significantly outperforms other state-of-the-art techniques: 24% relative improvement for pairwise concept classification in the Casablanca dataset and 9% relative improvement for localization in the A2D dataset as compared to the most competitive baseline.