 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrans4Trans: Efficient Transformer for Transparent Object and Semantic Scene Segmentation in Real-World Navigation Assistance
Aug 20, 2021

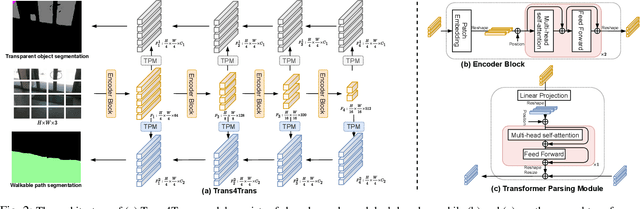
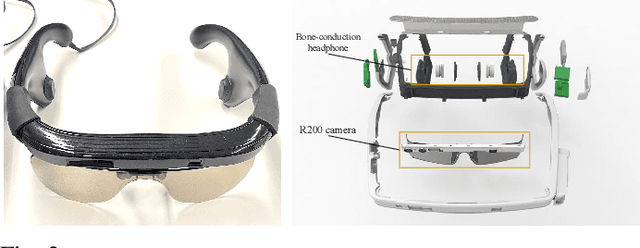
Transparent objects, such as glass walls and doors, constitute architectural obstacles hindering the mobility of people with low vision or blindness. For instance, the open space behind glass doors is inaccessible, unless it is correctly perceived and interacted with. However, traditional assistive technologies rarely cover the segmentation of these safety-critical transparent objects. In this paper, we build a wearable system with a novel dual-head Transformer for Transparency (Trans4Trans) perception model, which can segment general- and transparent objects. The two dense segmentation results are further combined with depth information in the system to help users navigate safely and assist them to negotiate transparent obstacles. We propose a lightweight Transformer Parsing Module (TPM) to perform multi-scale feature interpretation in the transformer-based decoder. Benefiting from TPM, the double decoders can perform joint learning from corresponding datasets to pursue robustness, meanwhile maintain efficiency on a portable GPU, with negligible calculation increase. The entire Trans4Trans model is constructed in a symmetrical encoder-decoder architecture, which outperforms state-of-the-art methods on the test sets of Stanford2D3D and Trans10K-v2 datasets, obtaining mIoU of 45.13% and 75.14%, respectively. Through a user study and various pre-tests conducted in indoor and outdoor scenes, the usability and reliability of our assistive system have been extensively verified. Meanwhile, the Tran4Trans model has outstanding performances on driving scene datasets. On Cityscapes, ACDC, and DADA-seg datasets corresponding to common environments, adverse weather, and traffic accident scenarios, mIoU scores of 81.5%, 76.3%, and 39.2% are obtained, demonstrating its high efficiency and robustness for real-world transportation applications.
Trans4Trans: Efficient Transformer for Transparent Object Segmentation to Help Visually Impaired People Navigate in the Real World
Jul 07, 2021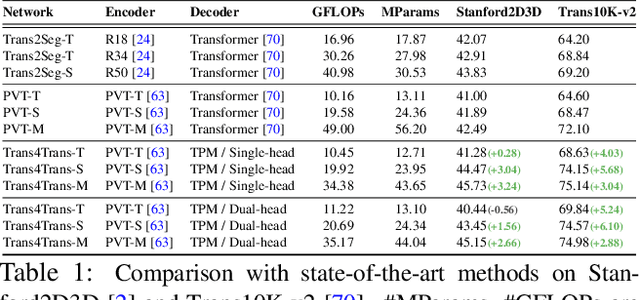
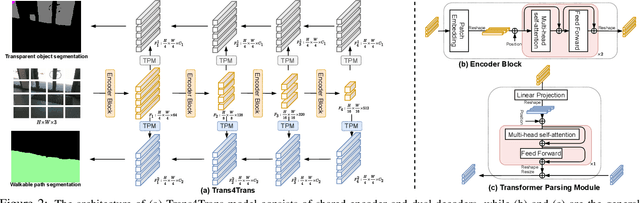

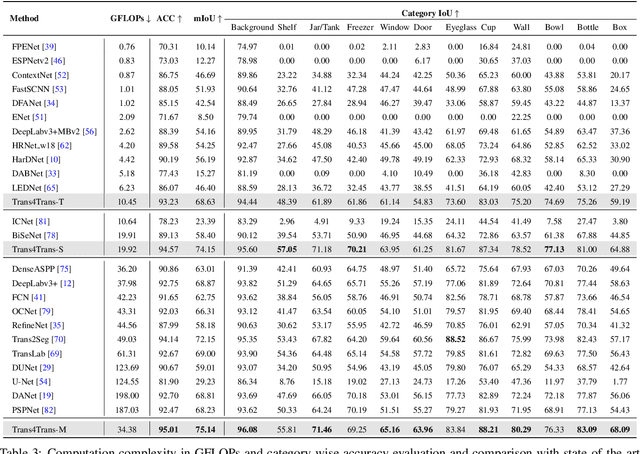
Common fully glazed facades and transparent objects present architectural barriers and impede the mobility of people with low vision or blindness, for instance, a path detected behind a glass door is inaccessible unless it is correctly perceived and reacted. However, segmenting these safety-critical objects is rarely covered by conventional assistive technologies. To tackle this issue, we construct a wearable system with a novel dual-head Transformer for Transparency (Trans4Trans) model, which is capable of segmenting general and transparent objects and performing real-time wayfinding to assist people walking alone more safely. Especially, both decoders created by our proposed Transformer Parsing Module (TPM) enable effective joint learning from different datasets. Besides, the efficient Trans4Trans model composed of symmetric transformer-based encoder and decoder, requires little computational expenses and is readily deployed on portable GPUs. Our Trans4Trans model outperforms state-of-the-art methods on the test sets of Stanford2D3D and Trans10K-v2 datasets and obtains mIoU of 45.13% and 75.14%, respectively. Through various pre-tests and a user study conducted in indoor and outdoor scenarios, the usability and reliability of our assistive system have been extensively verified.