 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing exploration algorithms for navigation with visual SLAM
Oct 18, 2021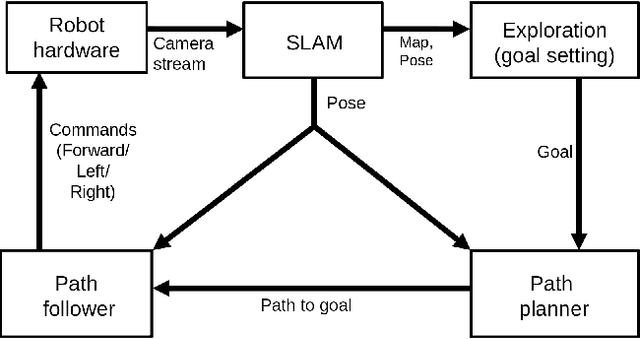
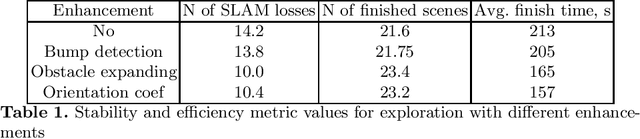
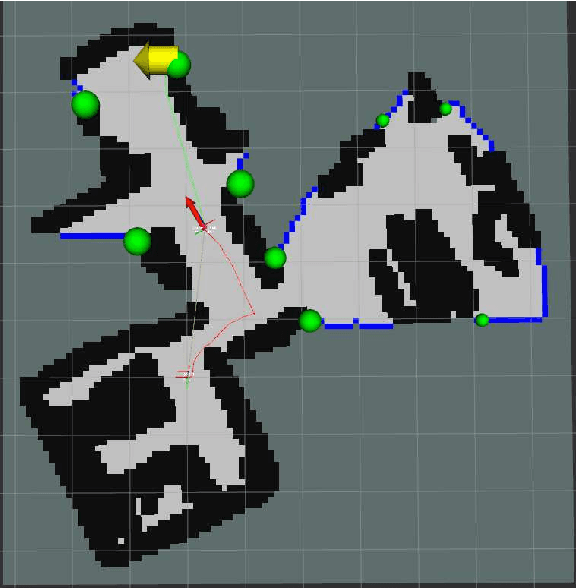
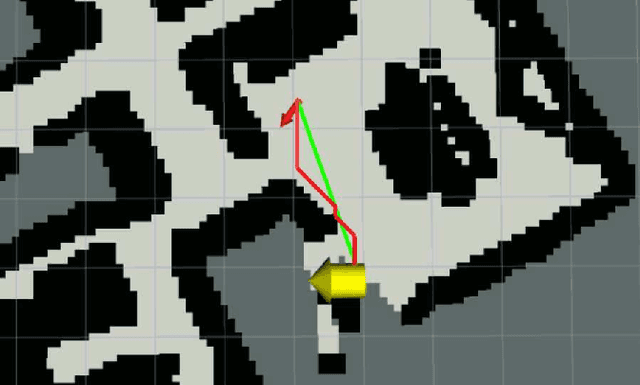
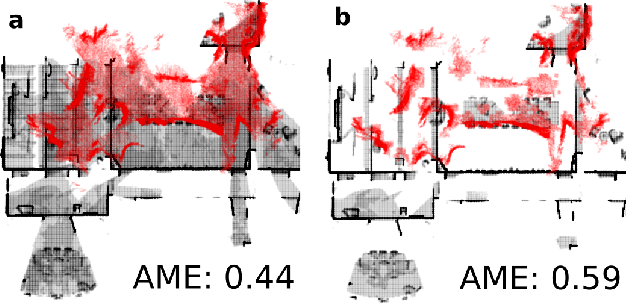
Exploration is an important step in autonomous navigation of robotic systems. In this paper we introduce a series of enhancements for exploration algorithms in order to use them with vision-based simultaneous localization and mapping (vSLAM) methods. We evaluate developed approaches in photo-realistic simulator in two modes: with ground-truth depths and neural network reconstructed depth maps as vSLAM input. We evaluate standard metrics in order to estimate exploration coverage.
MAOMaps: A Photo-Realistic Benchmark For vSLAM and Map Merging Quality Assessment
May 31, 2021
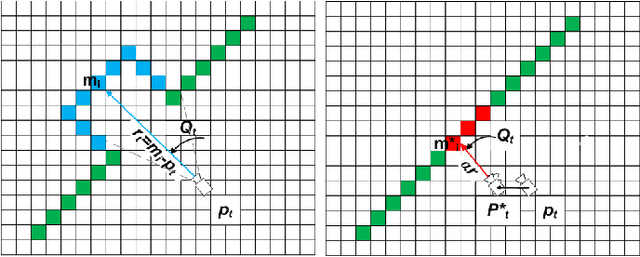
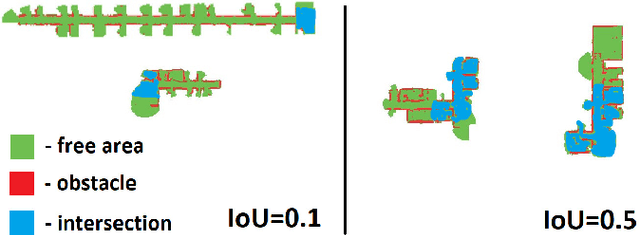
Running numerous experiments in simulation is a necessary step before deploying a control system on a real robot. In this paper we introduce a novel benchmark that is aimed at quantitatively evaluating the quality of vision-based simultaneous localization and mapping (vSLAM) and map merging algorithms. The benchmark consists of both a dataset and a set of tools for automatic evaluation. The dataset is photo-realistic and provides both the localization and the map ground truth data. This makes it possible to evaluate not only the localization part of the SLAM pipeline but the mapping part as well. To compare the vSLAM-built maps and the ground-truth ones we introduce a novel way to find correspondences between them that takes the SLAM context into account (as opposed to other approaches like nearest neighbors). The benchmark is ROS-compatable and is open-sourced to the community. The data and the code are available at: \texttt{github.com/CnnDepth/MAOMaps}.
Map-merging Algorithms for Visual SLAM: Feasibility Study and Empirical Evaluation
Sep 12, 2020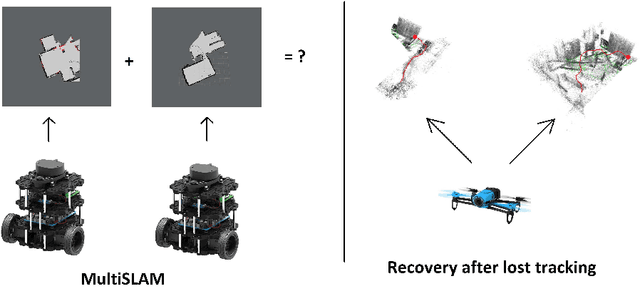
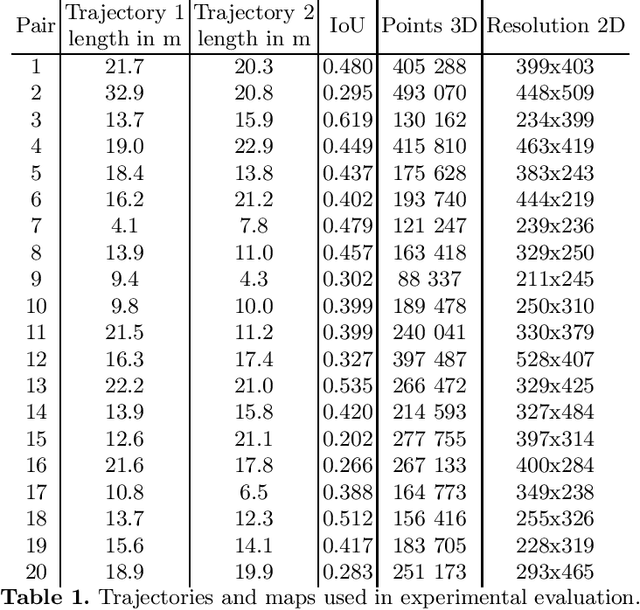
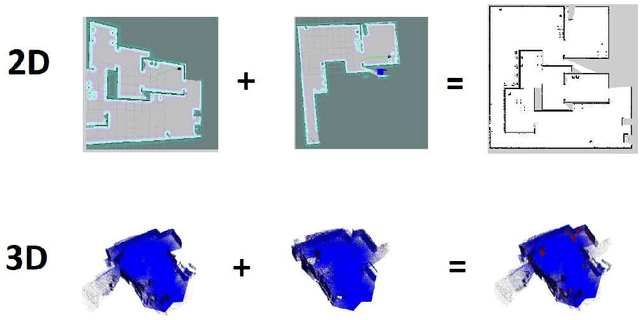
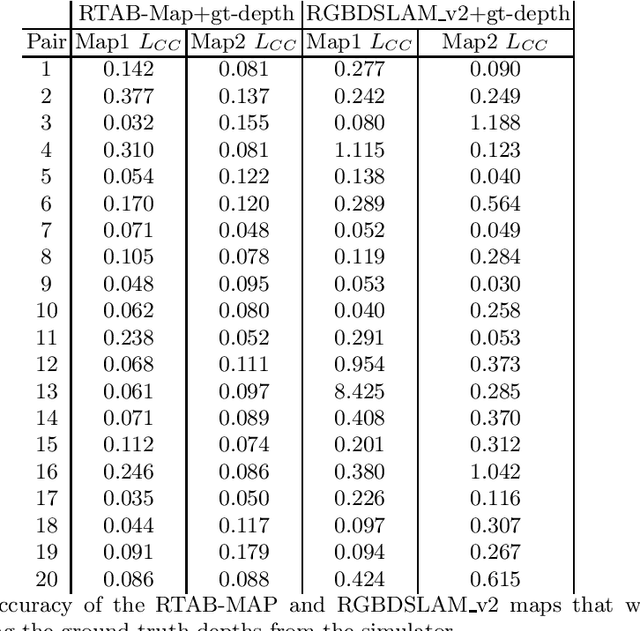
Simultaneous localization and mapping, especially the one relying solely on video data (vSLAM), is a challenging problem that has been extensively studied in robotics and computer vision. State-of-the-art vSLAM algorithms are capable of constructing accurate-enough maps that enable a mobile robot to autonomously navigate an unknown environment. In this work, we are interested in an important problem related to vSLAM, i.e. map merging, that might appear in various practically important scenarios, e.g. in a multi-robot coverage scenario. This problem asks whether different vSLAM maps can be merged into a consistent single representation. We examine the existing 2D and 3D map-merging algorithms and conduct an extensive empirical evaluation in realistic simulated environment (Habitat). Both qualitative and quantitative comparison is carried out and the obtained results are reported and analyzed.
Real-time Vision-based Depth Reconstruction with NVidia Jetson
Jul 16, 2019
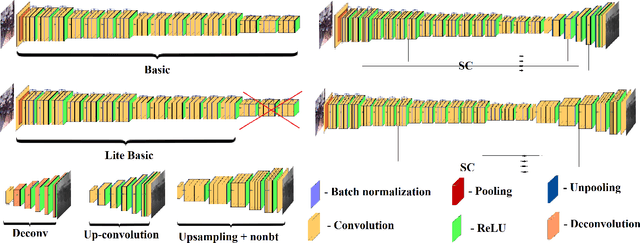
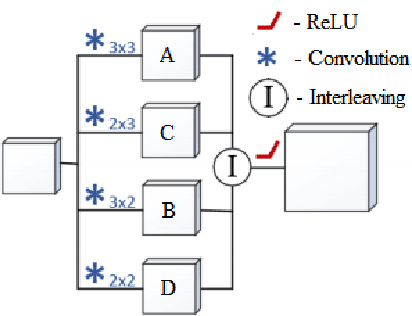
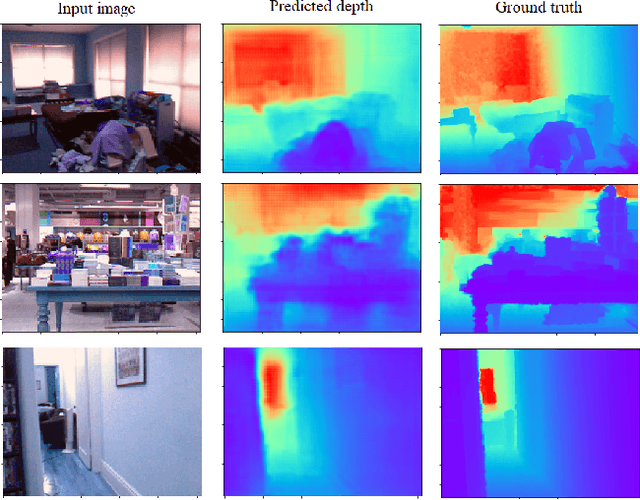
Vision-based depth reconstruction is a challenging problem extensively studied in computer vision but still lacking universal solution. Reconstructing depth from single image is particularly valuable to mobile robotics as it can be embedded to the modern vision-based simultaneous localization and mapping (vSLAM) methods providing them with the metric information needed to construct accurate maps in real scale. Typically, depth reconstruction is done nowadays via fully-convolutional neural networks (FCNNs). In this work we experiment with several FCNN architectures and introduce a few enhancements aimed at increasing both the effectiveness and the efficiency of the inference. We experimentally determine the solution that provides the best performance/accuracy tradeoff and is able to run on NVidia Jetson with the framerates exceeding 16FPS for 320 x 240 input. We also evaluate the suggested models by conducting monocular vSLAM of unknown indoor environment on NVidia Jetson TX2 in real-time. Open-source implementation of the models and the inference node for Robot Operating System (ROS) are available at https://github.com/CnnDepth/tx2_fcnn_node.
Sparse 3D Point-cloud Map Upsampling and Noise Removal as a vSLAM Post-processing Step: Experimental Evaluation
Jun 25, 2018
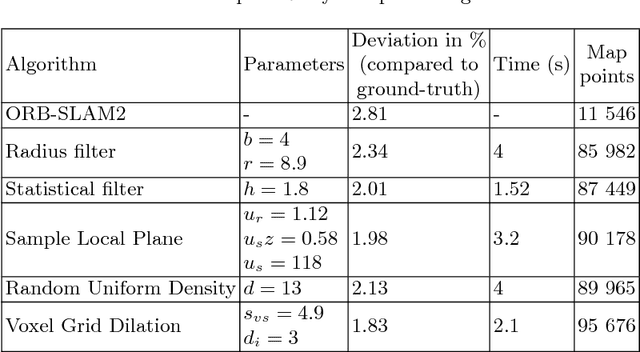

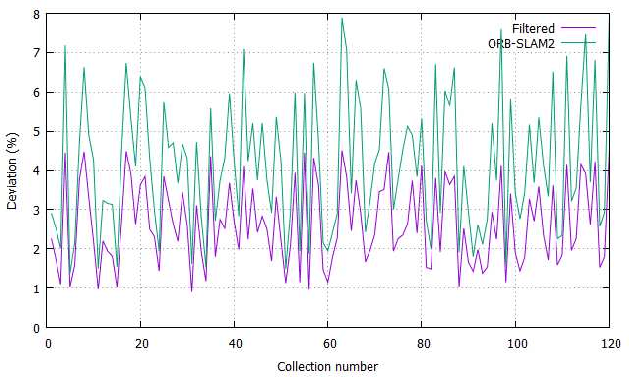
The monocular vision-based simultaneous localization and mapping (vSLAM) is one of the most challenging problem in mobile robotics and computer vision. In this work we study the post-processing techniques applied to sparse 3D point-cloud maps, obtained by feature-based vSLAM algorithms. Map post-processing is split into 2 major steps: 1) noise and outlier removal and 2) upsampling. We evaluate different combinations of known algorithms for outlier removing and upsampling on datasets of real indoor and outdoor environments and identify the most promising combination. We further use it to convert a point-cloud map, obtained by the real UAV performing indoor flight to 3D voxel grid (octo-map) potentially suitable for path planning.
Original Loop-closure Detection Algorithm for Monocular vSLAM
Jul 15, 2017
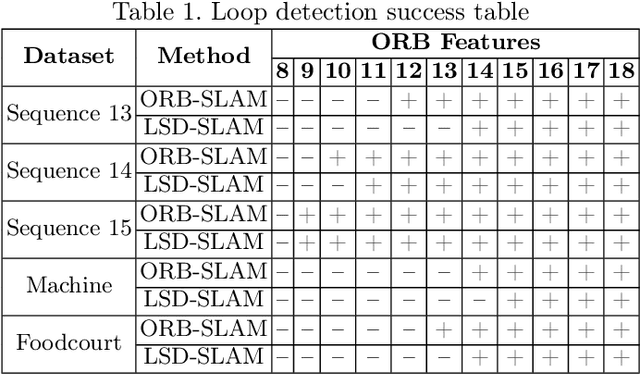
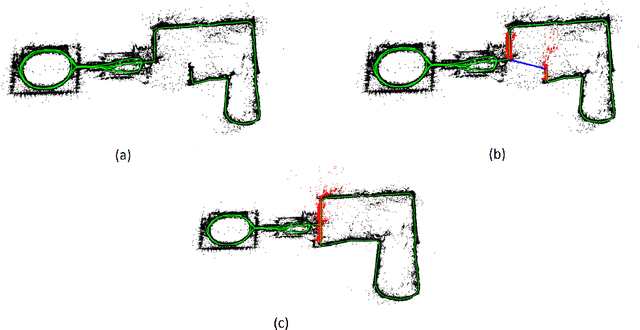
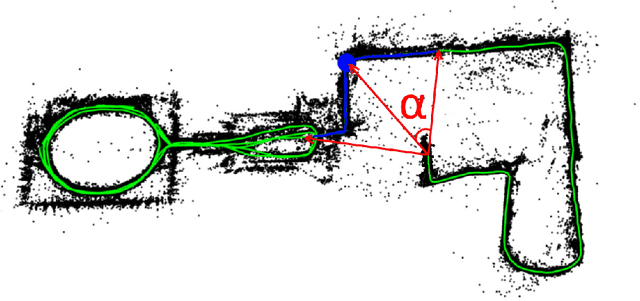
Vision-based simultaneous localization and mapping (vSLAM) is a well-established problem in mobile robotics and monocular vSLAM is one of the most challenging variations of that problem nowadays. In this work we study one of the core post-processing optimization mechanisms in vSLAM, e.g. loop-closure detection. We analyze the existing methods and propose original algorithm for loop-closure detection, which is suitable for dense, semi-dense and feature-based vSLAM methods. We evaluate the algorithm experimentally and show that it contribute to more accurate mapping while speeding up the monocular vSLAM pipeline to the extent the latter can be used in real-time for controlling small multi-rotor vehicle (drone).