 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSolving Data Quality Problems with Desbordante: a Demo
Jul 28, 2023Data profiling is an essential process in modern data-driven industries. One of its critical components is the discovery and validation of complex statistics, including functional dependencies, data constraints, association rules, and others. However, most existing data profiling systems that focus on complex statistics do not provide proper integration with the tools used by contemporary data scientists. This creates a significant barrier to the adoption of these tools in the industry. Moreover, existing systems were not created with industrial-grade workloads in mind. Finally, they do not aim to provide descriptive explanations, i.e. why a given pattern is not found. It is a significant issue as it is essential to understand the underlying reasons for a specific pattern's absence to make informed decisions based on the data. Because of that, these patterns are effectively rest in thin air: their application scope is rather limited, they are rarely used by the broader public. At the same time, as we are going to demonstrate in this presentation, complex statistics can be efficiently used to solve many classic data quality problems. Desbordante is an open-source data profiler that aims to close this gap. It is built with emphasis on industrial application: it is efficient, scalable, resilient to crashes, and provides explanations. Furthermore, it provides seamless Python integration by offloading various costly operations to the C++ core, not only mining. In this demonstration, we show several scenarios that allow end users to solve different data quality problems. Namely, we showcase typo detection, data deduplication, and data anomaly detection scenarios.
Desbordante: from benchmarking suite to high-performance science-intensive data profiler (preprint)
Jan 14, 2023Pioneering data profiling systems such as Metanome and OpenClean brought public attention to science-intensive data profiling. This type of profiling aims to extract complex patterns (primitives) such as functional dependencies, data constraints, association rules, and others. However, these tools are research prototypes rather than production-ready systems. The following work presents Desbordante - a high-performance science-intensive data profiler with open source code. Unlike similar systems, it is built with emphasis on industrial application in a multi-user environment. It is efficient, resilient to crashes, and scalable. Its efficiency is ensured by implementing discovery algorithms in C++, resilience is achieved by extensive use of containerization, and scalability is based on replication of containers. Desbordante aims to open industrial-grade primitive discovery to a broader public, focusing on domain experts who are not IT professionals. Aside from the discovery of various primitives, Desbordante offers primitive validation, which not only reports whether a given instance of primitive holds or not, but also points out what prevents it from holding via the use of special screens. Next, Desbordante supports pipelines - ready-to-use functionality implemented using the discovered primitives, for example, typo detection. We provide built-in pipelines, and the users can construct their own via provided Python bindings. Unlike other profilers, Desbordante works not only with tabular data, but with graph and transactional data as well. In this paper, we present Desbordante, the vision behind it and its use-cases. To provide a more in-depth perspective, we discuss its current state, architecture, and design decisions it is built on. Additionally, we outline our future plans.
Map-merging Algorithms for Visual SLAM: Feasibility Study and Empirical Evaluation
Sep 12, 2020
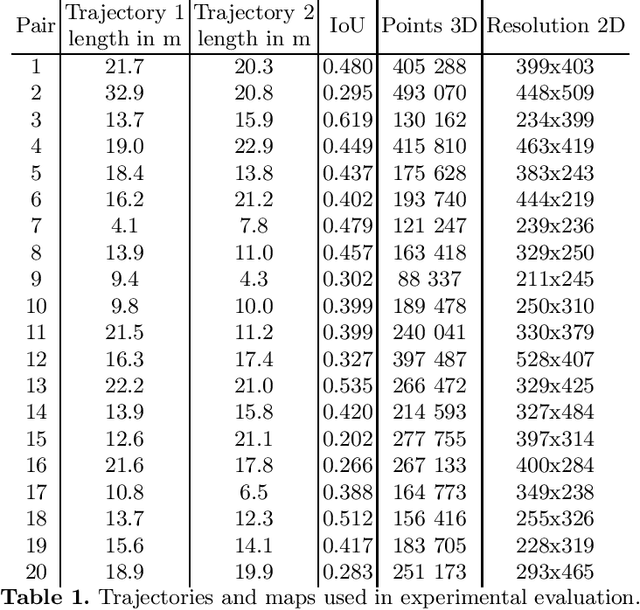
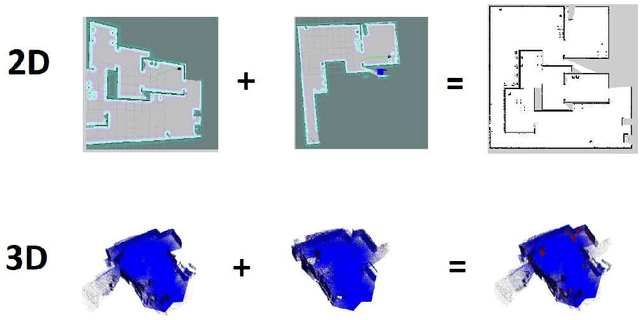
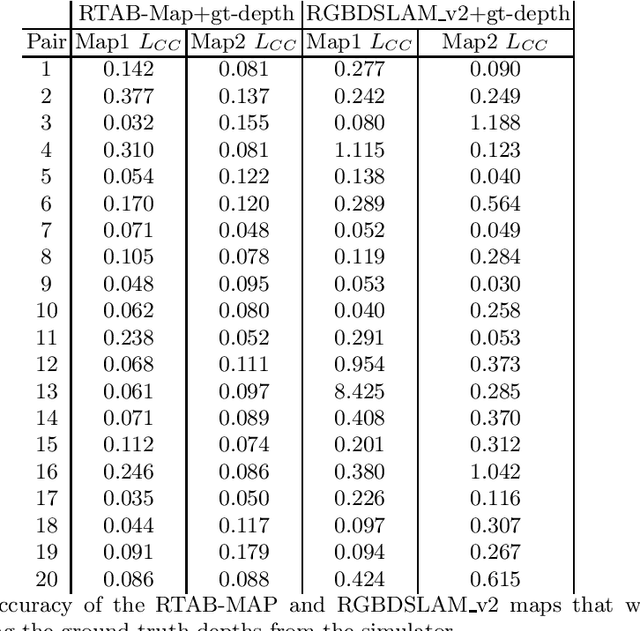
Simultaneous localization and mapping, especially the one relying solely on video data (vSLAM), is a challenging problem that has been extensively studied in robotics and computer vision. State-of-the-art vSLAM algorithms are capable of constructing accurate-enough maps that enable a mobile robot to autonomously navigate an unknown environment. In this work, we are interested in an important problem related to vSLAM, i.e. map merging, that might appear in various practically important scenarios, e.g. in a multi-robot coverage scenario. This problem asks whether different vSLAM maps can be merged into a consistent single representation. We examine the existing 2D and 3D map-merging algorithms and conduct an extensive empirical evaluation in realistic simulated environment (Habitat). Both qualitative and quantitative comparison is carried out and the obtained results are reported and analyzed.