 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSolving Data Quality Problems with Desbordante: a Demo
Jul 28, 2023Data profiling is an essential process in modern data-driven industries. One of its critical components is the discovery and validation of complex statistics, including functional dependencies, data constraints, association rules, and others. However, most existing data profiling systems that focus on complex statistics do not provide proper integration with the tools used by contemporary data scientists. This creates a significant barrier to the adoption of these tools in the industry. Moreover, existing systems were not created with industrial-grade workloads in mind. Finally, they do not aim to provide descriptive explanations, i.e. why a given pattern is not found. It is a significant issue as it is essential to understand the underlying reasons for a specific pattern's absence to make informed decisions based on the data. Because of that, these patterns are effectively rest in thin air: their application scope is rather limited, they are rarely used by the broader public. At the same time, as we are going to demonstrate in this presentation, complex statistics can be efficiently used to solve many classic data quality problems. Desbordante is an open-source data profiler that aims to close this gap. It is built with emphasis on industrial application: it is efficient, scalable, resilient to crashes, and provides explanations. Furthermore, it provides seamless Python integration by offloading various costly operations to the C++ core, not only mining. In this demonstration, we show several scenarios that allow end users to solve different data quality problems. Namely, we showcase typo detection, data deduplication, and data anomaly detection scenarios.
Desbordante: from benchmarking suite to high-performance science-intensive data profiler (preprint)
Jan 14, 2023Pioneering data profiling systems such as Metanome and OpenClean brought public attention to science-intensive data profiling. This type of profiling aims to extract complex patterns (primitives) such as functional dependencies, data constraints, association rules, and others. However, these tools are research prototypes rather than production-ready systems. The following work presents Desbordante - a high-performance science-intensive data profiler with open source code. Unlike similar systems, it is built with emphasis on industrial application in a multi-user environment. It is efficient, resilient to crashes, and scalable. Its efficiency is ensured by implementing discovery algorithms in C++, resilience is achieved by extensive use of containerization, and scalability is based on replication of containers. Desbordante aims to open industrial-grade primitive discovery to a broader public, focusing on domain experts who are not IT professionals. Aside from the discovery of various primitives, Desbordante offers primitive validation, which not only reports whether a given instance of primitive holds or not, but also points out what prevents it from holding via the use of special screens. Next, Desbordante supports pipelines - ready-to-use functionality implemented using the discovered primitives, for example, typo detection. We provide built-in pipelines, and the users can construct their own via provided Python bindings. Unlike other profilers, Desbordante works not only with tabular data, but with graph and transactional data as well. In this paper, we present Desbordante, the vision behind it and its use-cases. To provide a more in-depth perspective, we discuss its current state, architecture, and design decisions it is built on. Additionally, we outline our future plans.
Russian Web Tables: A Public Corpus of Web Tables for Russian Language Based on Wikipedia
Oct 03, 2022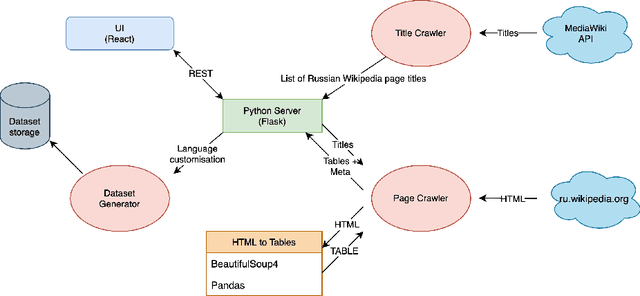
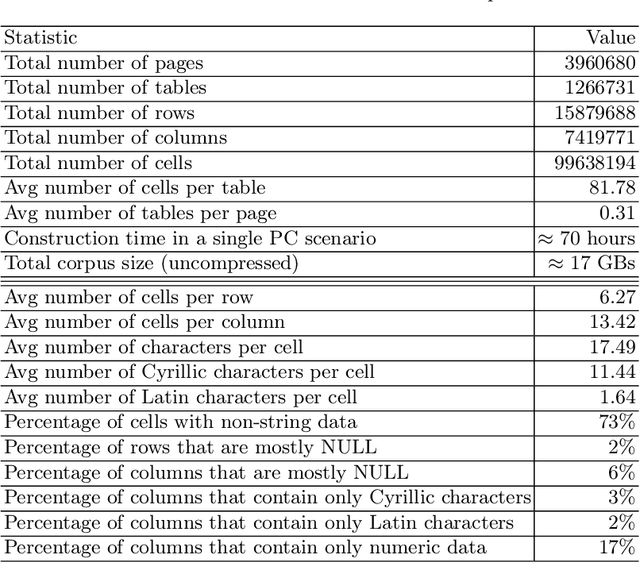
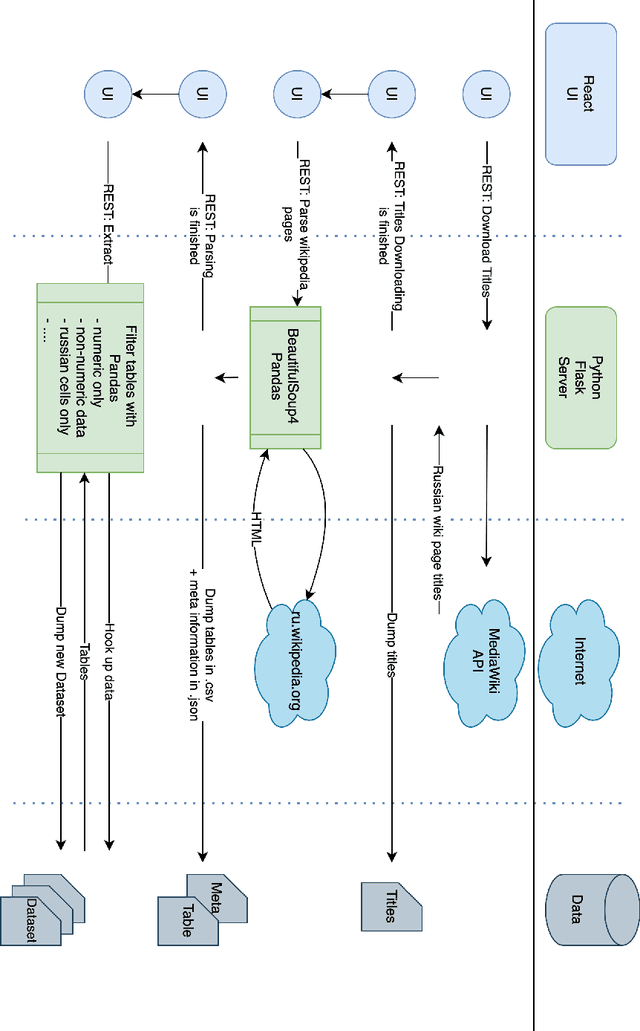
Corpora that contain tabular data such as WebTables are a vital resource for the academic community. Essentially, they are the backbone of any modern research in information management. They are used for various tasks of data extraction, knowledge base construction, question answering, column semantic type detection and many other. Such corpora are useful not only as a source of data, but also as a base for building test datasets. So far, there were no such corpora for the Russian language and this seriously hindered research in the aforementioned areas. In this paper, we present the first corpus of Web tables created specifically out of Russian language material. It was built via a special toolkit we have developed to crawl the Russian Wikipedia. Both the corpus and the toolkit are open-source and publicly available. Finally, we present a short study that describes Russian Wikipedia tables and their statistics.
S3M: Siamese Stack (Trace) Similarity Measure
Mar 18, 2021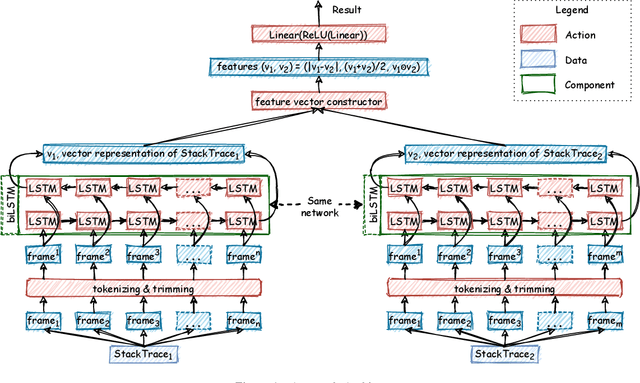
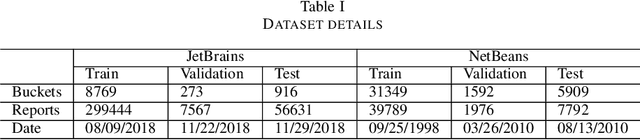
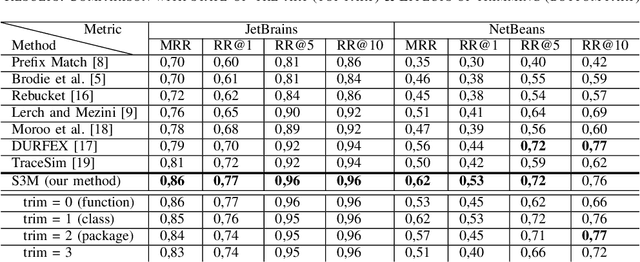
Automatic crash reporting systems have become a de-facto standard in software development. These systems monitor target software, and if a crash occurs they send details to a backend application. Later on, these reports are aggregated and used in the development process to 1) understand whether it is a new or an existing issue, 2) assign these bugs to appropriate developers, and 3) gain a general overview of the application's bug landscape. The efficiency of report aggregation and subsequent operations heavily depends on the quality of the report similarity metric. However, a distinctive feature of this kind of report is that no textual input from the user (i.e., bug description) is available: it contains only stack trace information. In this paper, we present S3M ("extreme") -- the first approach to computing stack trace similarity based on deep learning. It is based on a siamese architecture that uses a biLSTM encoder and a fully-connected classifier to compute similarity. Our experiments demonstrate the superiority of our approach over the state-of-the-art on both open-sourced data and a private JetBrains dataset. Additionally, we review the impact of stack trace trimming on the quality of the results.