 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRussian Web Tables: A Public Corpus of Web Tables for Russian Language Based on Wikipedia
Paper and Code
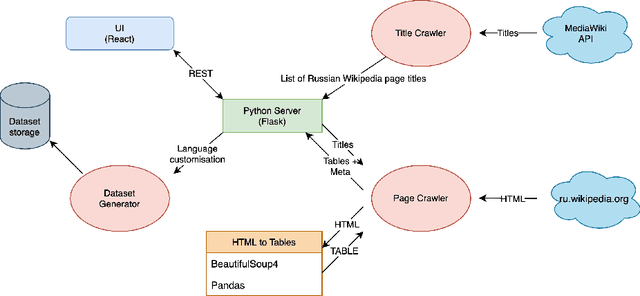
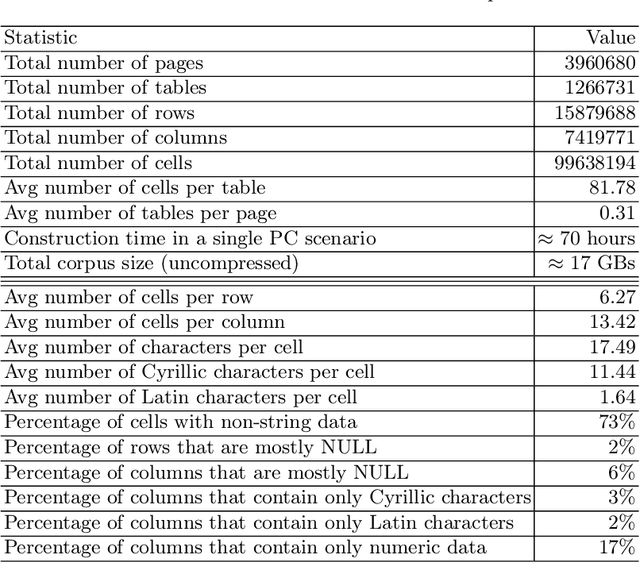
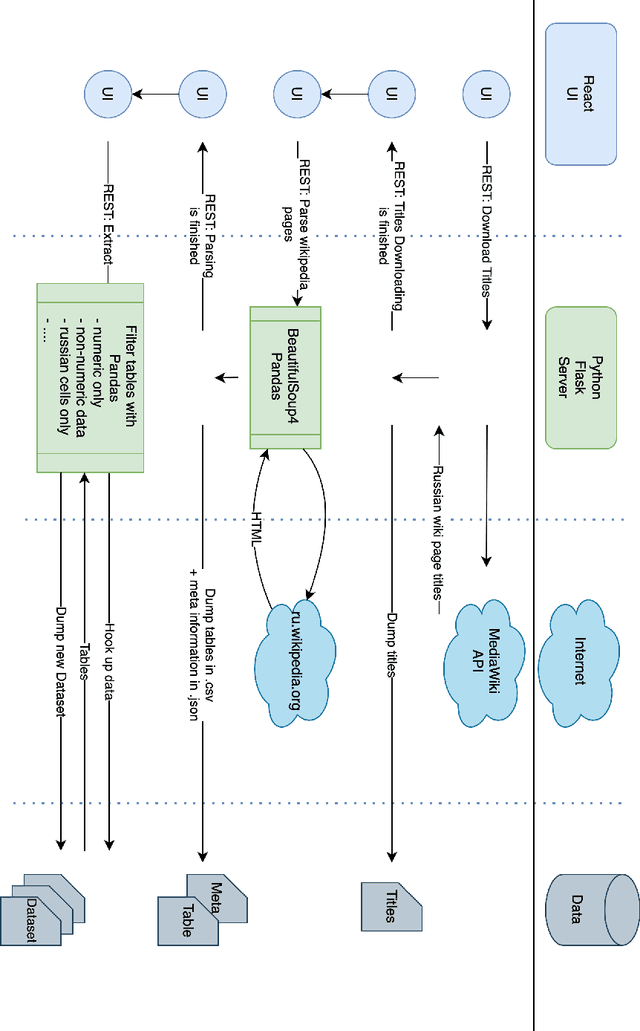
Corpora that contain tabular data such as WebTables are a vital resource for the academic community. Essentially, they are the backbone of any modern research in information management. They are used for various tasks of data extraction, knowledge base construction, question answering, column semantic type detection and many other. Such corpora are useful not only as a source of data, but also as a base for building test datasets. So far, there were no such corpora for the Russian language and this seriously hindered research in the aforementioned areas. In this paper, we present the first corpus of Web tables created specifically out of Russian language material. It was built via a special toolkit we have developed to crawl the Russian Wikipedia. Both the corpus and the toolkit are open-source and publicly available. Finally, we present a short study that describes Russian Wikipedia tables and their statistics.