 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimization of Oblivious Decision Tree Ensembles Evaluation for CPU
Nov 01, 2022CatBoost is a popular machine learning library. CatBoost models are based on oblivious decision trees, making training and evaluation rapid. CatBoost has many applications, and some require low latency and high throughput evaluation. This paper investigates the possibilities for improving CatBoost's performance in single-core CPU computations. We explore the new features provided by the AVX instruction sets to optimize evaluation. We increase performance by 20-40% using AVX2 instructions without quality impact. We also introduce a new trade-off between speed and quality. Using float16 for leaf values and AVX-512 instructions, we achieve 50-70% speed-up.
Russian Web Tables: A Public Corpus of Web Tables for Russian Language Based on Wikipedia
Oct 03, 2022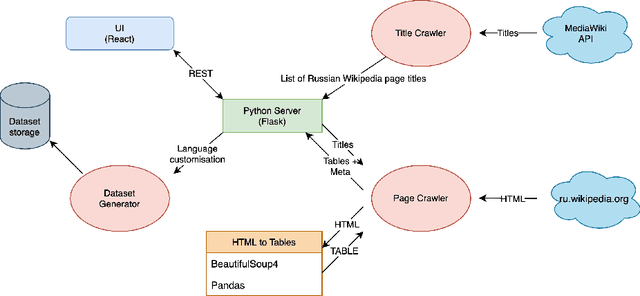
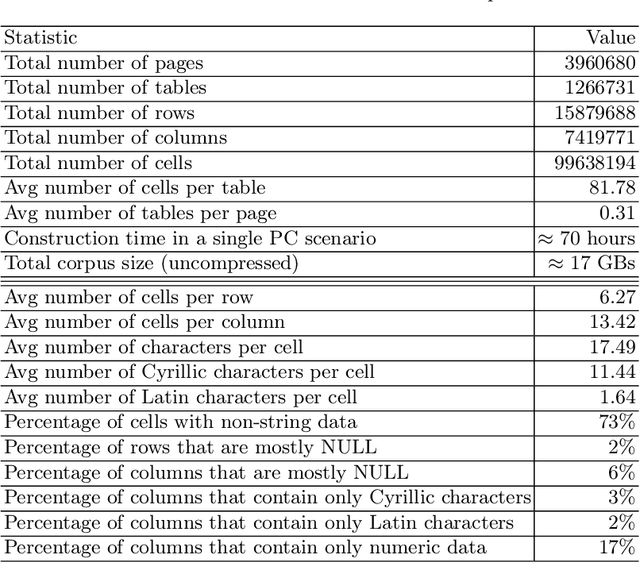
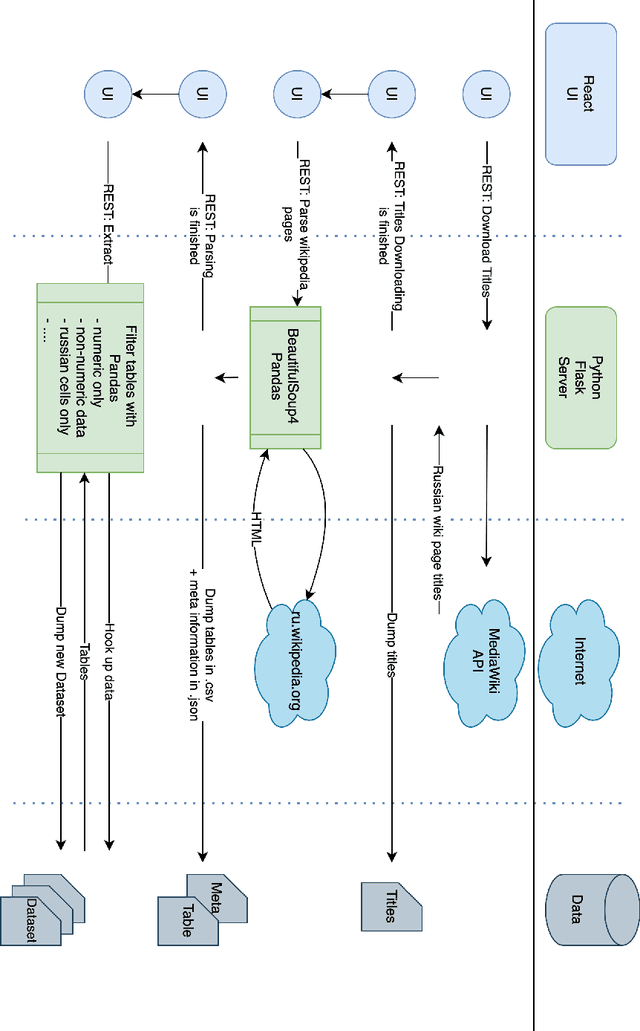
Corpora that contain tabular data such as WebTables are a vital resource for the academic community. Essentially, they are the backbone of any modern research in information management. They are used for various tasks of data extraction, knowledge base construction, question answering, column semantic type detection and many other. Such corpora are useful not only as a source of data, but also as a base for building test datasets. So far, there were no such corpora for the Russian language and this seriously hindered research in the aforementioned areas. In this paper, we present the first corpus of Web tables created specifically out of Russian language material. It was built via a special toolkit we have developed to crawl the Russian Wikipedia. Both the corpus and the toolkit are open-source and publicly available. Finally, we present a short study that describes Russian Wikipedia tables and their statistics.
Optimization of Decision Tree Evaluation Using SIMD Instructions
May 15, 2022Decision forest (decision tree ensemble) is one of the most popular machine learning algorithms. To use large models on big data, like document scoring with learning-to-rank models, we need to evaluate these models efficiently. In this paper, we explore MatrixNet, the ancestor of the popular CatBoost library. Both libraries use the SSE instruction set for scoring on CPU. This paper investigates the opportunities given by the AVX instruction set to evaluate models more efficiently. We achieved 35% speedup on the binarization stage (nodes conditions comparison), and 20% speedup on the trees apply stage on the ranking model.