 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeS3M: Siamese Stack (Trace) Similarity Measure
Paper and Code
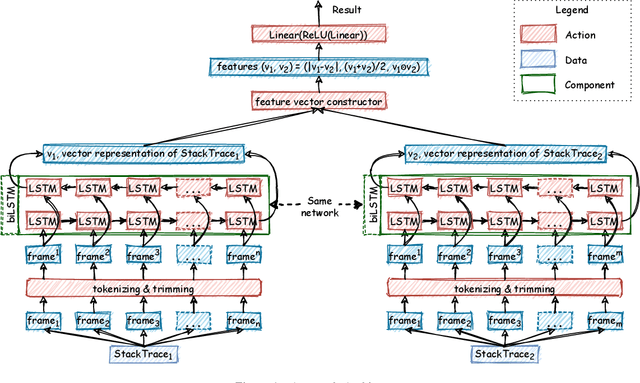
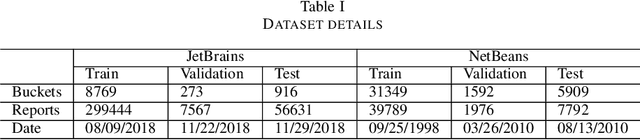
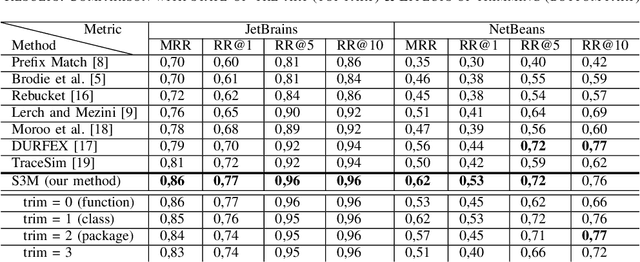
Automatic crash reporting systems have become a de-facto standard in software development. These systems monitor target software, and if a crash occurs they send details to a backend application. Later on, these reports are aggregated and used in the development process to 1) understand whether it is a new or an existing issue, 2) assign these bugs to appropriate developers, and 3) gain a general overview of the application's bug landscape. The efficiency of report aggregation and subsequent operations heavily depends on the quality of the report similarity metric. However, a distinctive feature of this kind of report is that no textual input from the user (i.e., bug description) is available: it contains only stack trace information. In this paper, we present S3M ("extreme") -- the first approach to computing stack trace similarity based on deep learning. It is based on a siamese architecture that uses a biLSTM encoder and a fully-connected classifier to compute similarity. Our experiments demonstrate the superiority of our approach over the state-of-the-art on both open-sourced data and a private JetBrains dataset. Additionally, we review the impact of stack trace trimming on the quality of the results.