 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-time Vision-based Depth Reconstruction with NVidia Jetson
Paper and Code

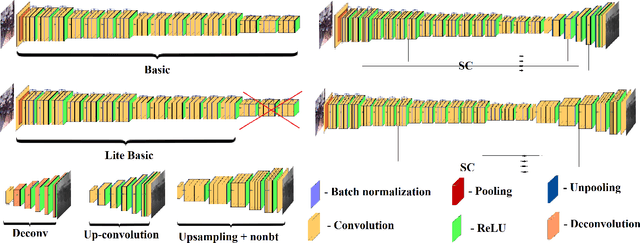
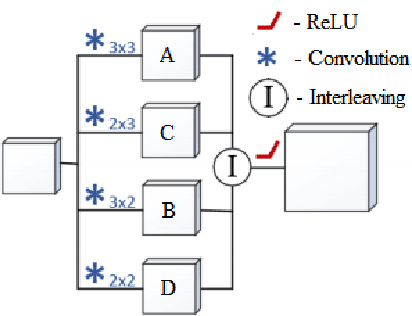
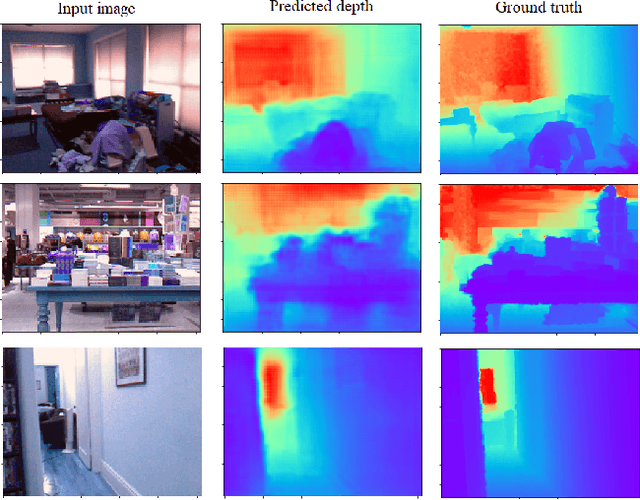
Vision-based depth reconstruction is a challenging problem extensively studied in computer vision but still lacking universal solution. Reconstructing depth from single image is particularly valuable to mobile robotics as it can be embedded to the modern vision-based simultaneous localization and mapping (vSLAM) methods providing them with the metric information needed to construct accurate maps in real scale. Typically, depth reconstruction is done nowadays via fully-convolutional neural networks (FCNNs). In this work we experiment with several FCNN architectures and introduce a few enhancements aimed at increasing both the effectiveness and the efficiency of the inference. We experimentally determine the solution that provides the best performance/accuracy tradeoff and is able to run on NVidia Jetson with the framerates exceeding 16FPS for 320 x 240 input. We also evaluate the suggested models by conducting monocular vSLAM of unknown indoor environment on NVidia Jetson TX2 in real-time. Open-source implementation of the models and the inference node for Robot Operating System (ROS) are available at https://github.com/CnnDepth/tx2_fcnn_node.