 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePersistent Weak Interferer Detection in WiFi Networks: A Deep Learning Based Approach
May 23, 2022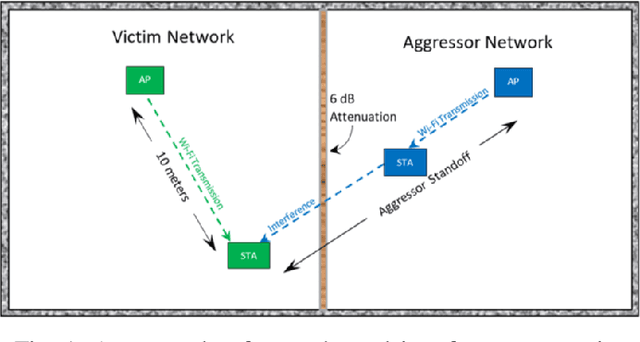
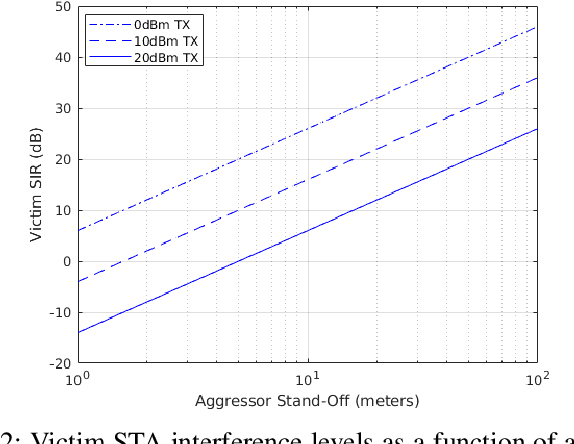
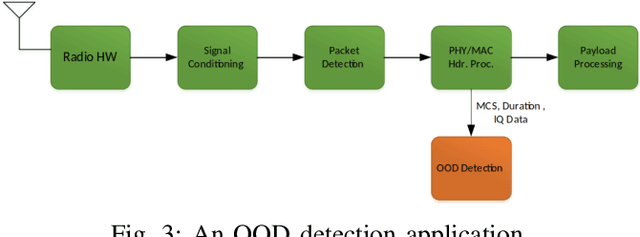
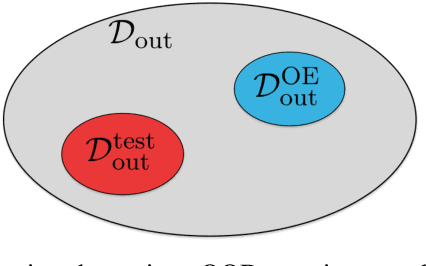
In this paper, we explore the use of multiple deep learning techniques to detect weak interference in WiFi networks. Given the low interference signal levels involved, this scenario tends to be difficult to detect. However, even signal-to-interference ratios exceeding 20 dB can cause significant throughput degradation and latency. Furthermore, the resultant packet error rate may not be enough to force the WiFi network to fallback to a more robust physical layer configuration. Deep learning applied directly to sampled radio frequency data has the potential to perform detection much cheaper than successive interference cancellation, which is important for real-time persistent network monitoring. The techniques explored in this work include maximum softmax probability, distance metric learning, variational autoencoder, and autoreggressive log-likelihood. We also introduce the notion of generalized outlier exposure for these techniques, and show its importance in detecting weak interference. Our results indicate that with outlier exposure, maximum softmax probability, distance metric learning, and autoreggresive log-likelihood are capable of reliably detecting interference more than 20 dB below the 802.11 specified minimum sensitivity levels. We believe this presents a unique software solution to real-time, persistent network monitoring.
Tensor Comprehensions: Framework-Agnostic High-Performance Machine Learning Abstractions
Jun 29, 2018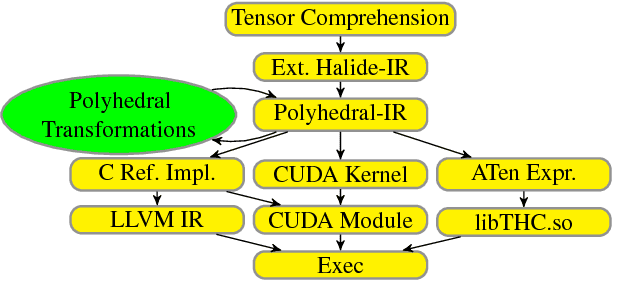

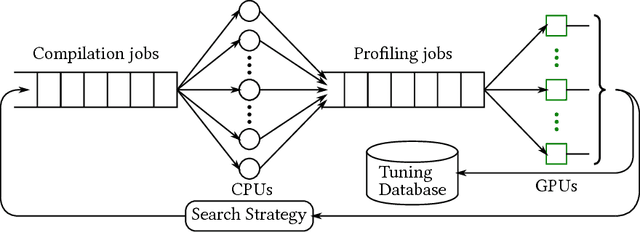
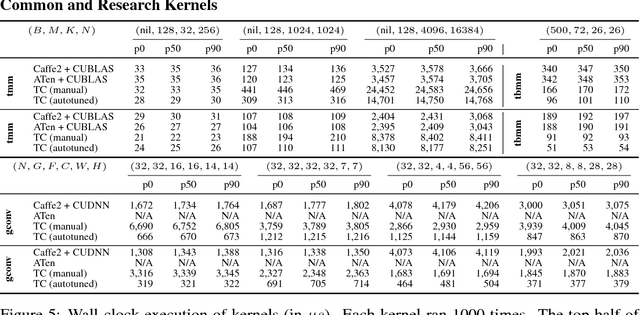
Deep learning models with convolutional and recurrent networks are now ubiquitous and analyze massive amounts of audio, image, video, text and graph data, with applications in automatic translation, speech-to-text, scene understanding, ranking user preferences, ad placement, etc. Competing frameworks for building these networks such as TensorFlow, Chainer, CNTK, Torch/PyTorch, Caffe1/2, MXNet and Theano, explore different tradeoffs between usability and expressiveness, research or production orientation and supported hardware. They operate on a DAG of computational operators, wrapping high-performance libraries such as CUDNN (for NVIDIA GPUs) or NNPACK (for various CPUs), and automate memory allocation, synchronization, distribution. Custom operators are needed where the computation does not fit existing high-performance library calls, usually at a high engineering cost. This is frequently required when new operators are invented by researchers: such operators suffer a severe performance penalty, which limits the pace of innovation. Furthermore, even if there is an existing runtime call these frameworks can use, it often doesn't offer optimal performance for a user's particular network architecture and dataset, missing optimizations between operators as well as optimizations that can be done knowing the size and shape of data. Our contributions include (1) a language close to the mathematics of deep learning called Tensor Comprehensions, (2) a polyhedral Just-In-Time compiler to convert a mathematical description of a deep learning DAG into a CUDA kernel with delegated memory management and synchronization, also providing optimizations such as operator fusion and specialization for specific sizes, (3) a compilation cache populated by an autotuner. [Abstract cutoff]