 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClinical Validation of Medical-based Large Language Model Chatbots on Ophthalmic Patient Queries with LLM-based Evaluation
Feb 05, 2026Domain specific large language models are increasingly used to support patient education, triage, and clinical decision making in ophthalmology, making rigorous evaluation essential to ensure safety and accuracy. This study evaluated four small medical LLMs Meerkat-7B, BioMistral-7B, OpenBioLLM-8B, and MedLLaMA3-v20 in answering ophthalmology related patient queries and assessed the feasibility of LLM based evaluation against clinician grading. In this cross sectional study, 180 ophthalmology patient queries were answered by each model, generating 2160 responses. Models were selected for parameter sizes under 10 billion to enable resource efficient deployment. Responses were evaluated by three ophthalmologists of differing seniority and by GPT-4-Turbo using the S.C.O.R.E. framework assessing safety, consensus and context, objectivity, reproducibility, and explainability, with ratings assigned on a five point Likert scale. Agreement between LLM and clinician grading was assessed using Spearman rank correlation, Kendall tau statistics, and kernel density estimate analyses. Meerkat-7B achieved the highest performance with mean scores of 3.44 from Senior Consultants, 4.08 from Consultants, and 4.18 from Residents. MedLLaMA3-v20 performed poorest, with 25.5 percent of responses containing hallucinations or clinically misleading content, including fabricated terminology. GPT-4-Turbo grading showed strong alignment with clinician assessments overall, with Spearman rho of 0.80 and Kendall tau of 0.67, though Senior Consultants graded more conservatively. Overall, medical LLMs demonstrated potential for safe ophthalmic question answering, but gaps remained in clinical depth and consensus, supporting the feasibility of LLM based evaluation for large scale benchmarking and the need for hybrid automated and clinician review frameworks to guide safe clinical deployment.
Data-centric AI approach to improve optic nerve head segmentation and localization in OCT en face images
Aug 08, 2022
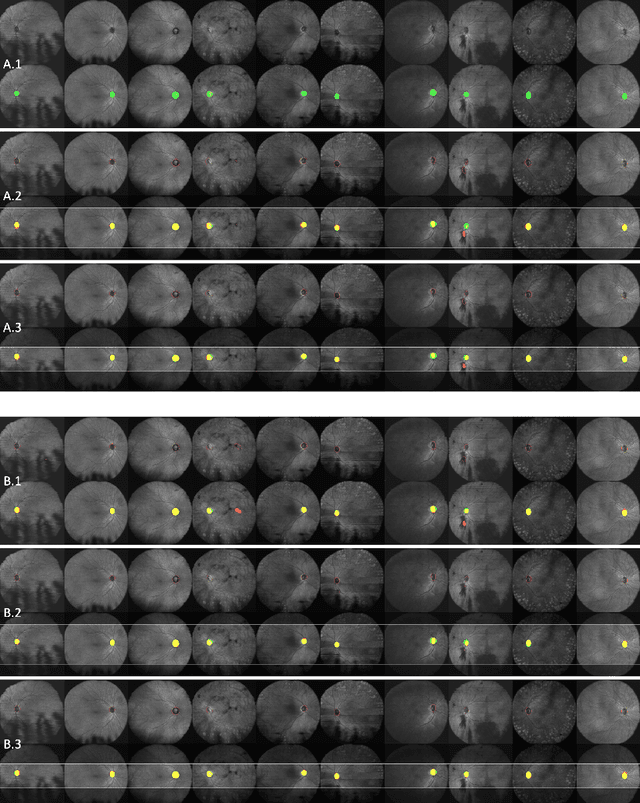
The automatic detection and localization of anatomical features in retinal imaging data are relevant for many aspects. In this work, we follow a data-centric approach to optimize classifier training for optic nerve head detection and localization in optical coherence tomography en face images of the retina. We examine the effect of domain knowledge driven spatial complexity reduction on the resulting optic nerve head segmentation and localization performance. We present a machine learning approach for segmenting optic nerve head in 2D en face projections of 3D widefield swept source optical coherence tomography scans that enables the automated assessment of large amounts of data. Evaluation on manually annotated 2D en face images of the retina demonstrates that training of a standard U-Net can yield improved optic nerve head segmentation and localization performance when the underlying pixel-level binary classification task is spatially relaxed through domain knowledge.