 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentic Business Process Management: A Research Manifesto
Mar 19, 2026This paper presents a manifesto that articulates the conceptual foundations of Agentic Business Process Management (APM), an extension of Business Process Management (BPM) for governing autonomous agents executing processes in organizations. From a management perspective, APM represents a paradigm shift from the traditional process view of the business process, driven by the realization of process awareness and an agent-oriented abstraction, where software and human agents act as primary functional entities that perceive, reason, and act within explicit process frames. This perspective marks a shift from traditional, automation-oriented BPM toward systems in which autonomy is constrained, aligned, and made operational through process awareness. We introduce the core abstractions and architectural elements required to realize APM systems and elaborate on four key capabilities that such APM agents must support: framed autonomy, explainability, conversational actionability, and self-modification. These capabilities jointly ensure that agents' goals are aligned with organizational goals and that agents behave in a framed yet proactive manner in pursuing those goals. We discuss the extent to which the capabilities can be realized and identify research challenges whose resolution requires further advances in BPM, AI, and multi-agent systems. The manifesto thus serves as a roadmap for bridging these communities and for guiding the development of APM systems in practice.
A Research Roadmap for Augmenting Software Engineering Processes and Software Products with Generative AI
Oct 30, 2025Generative AI (GenAI) is rapidly transforming software engineering (SE) practices, influencing how SE processes are executed, as well as how software systems are developed, operated, and evolved. This paper applies design science research to build a roadmap for GenAI-augmented SE. The process consists of three cycles that incrementally integrate multiple sources of evidence, including collaborative discussions from the FSE 2025 "Software Engineering 2030" workshop, rapid literature reviews, and external feedback sessions involving peers. McLuhan's tetrads were used as a conceptual instrument to systematically capture the transforming effects of GenAI on SE processes and software products.The resulting roadmap identifies four fundamental forms of GenAI augmentation in SE and systematically characterizes their related research challenges and opportunities. These insights are then consolidated into a set of future research directions. By grounding the roadmap in a rigorous multi-cycle process and cross-validating it among independent author teams and peers, the study provides a transparent and reproducible foundation for analyzing how GenAI affects SE processes, methods and tools, and for framing future research within this rapidly evolving area. Based on these findings, the article finally makes ten predictions for SE in the year 2030.
Variance of ML-based software fault predictors: are we really improving fault prediction?
Oct 26, 2023Software quality assurance activities become increasingly difficult as software systems become more and more complex and continuously grow in size. Moreover, testing becomes even more expensive when dealing with large-scale systems. Thus, to effectively allocate quality assurance resources, researchers have proposed fault prediction (FP) which utilizes machine learning (ML) to predict fault-prone code areas. However, ML algorithms typically make use of stochastic elements to increase the prediction models' generalizability and efficiency of the training process. These stochastic elements, also known as nondeterminism-introducing (NI) factors, lead to variance in the training process and as a result, lead to variance in prediction accuracy and training time. This variance poses a challenge for reproducibility in research. More importantly, while fault prediction models may have shown good performance in the lab (e.g., often-times involving multiple runs and averaging outcomes), high variance of results can pose the risk that these models show low performance when applied in practice. In this work, we experimentally analyze the variance of a state-of-the-art fault prediction approach. Our experimental results indicate that NI factors can indeed cause considerable variance in the fault prediction models' accuracy. We observed a maximum variance of 10.10% in terms of the per-class accuracy metric. We thus, also discuss how to deal with such variance.
An AI Chatbot for Explaining Deep Reinforcement Learning Decisions of Service-oriented Systems
Sep 25, 2023Deep Reinforcement Learning (Deep RL) is increasingly used to cope with the open-world assumption in service-oriented systems. Deep RL was successfully applied to problems such as dynamic service composition, job scheduling, and offloading, as well as service adaptation. While Deep RL offers many benefits, understanding the decision-making of Deep RL is challenging because its learned decision-making policy essentially appears as a black box. Yet, understanding the decision-making of Deep RL is key to help service developers perform debugging, support service providers to comply with relevant legal frameworks, and facilitate service users to build trust. We introduce Chat4XAI to facilitate the understanding of the decision-making of Deep RL by providing natural-language explanations. Compared with visual explanations, the reported benefits of natural-language explanations include better understandability for non-technical users, increased user acceptance and trust, as well as more efficient explanations. Chat4XAI leverages modern AI chatbot technology and dedicated prompt engineering. Compared to earlier work on natural-language explanations using classical software-based dialogue systems, using an AI chatbot eliminates the need for eliciting and defining potential questions and answers up-front. We prototypically realize Chat4XAI using OpenAI's ChatGPT API and evaluate the fidelity and stability of its explanations using an adaptive service exemplar.
Automatically Reconciling the Trade-off between Prediction Accuracy and Earliness in Prescriptive Business Process Monitoring
Jul 12, 2023



Prescriptive business process monitoring provides decision support to process managers on when and how to adapt an ongoing business process to prevent or mitigate an undesired process outcome. We focus on the problem of automatically reconciling the trade-off between prediction accuracy and prediction earliness in determining when to adapt. Adaptations should happen sufficiently early to provide enough lead time for the adaptation to become effective. However, earlier predictions are typically less accurate than later predictions. This means that acting on less accurate predictions may lead to unnecessary adaptations or missed adaptations. Different approaches were presented in the literature to reconcile the trade-off between prediction accuracy and earliness. So far, these approaches were compared with different baselines, and evaluated using different data sets or even confidential data sets. This limits the comparability and replicability of the approaches and makes it difficult to choose a concrete approach in practice. We perform a comparative evaluation of the main alternative approaches for reconciling the trade-off between prediction accuracy and earliness. Using four public real-world event log data sets and two types of prediction models, we assess and compare the cost savings of these approaches. The experimental results indicate which criteria affect the effectiveness of an approach and help us state initial recommendations for the selection of a concrete approach in practice.
A User Study on Explainable Online Reinforcement Learning for Adaptive Systems
Jul 09, 2023Online reinforcement learning (RL) is increasingly used for realizing adaptive systems in the presence of design time uncertainty. Online RL facilitates learning from actual operational data and thereby leverages feedback only available at runtime. However, Online RL requires the definition of an effective and correct reward function, which quantifies the feedback to the RL algorithm and thereby guides learning. With Deep RL gaining interest, the learned knowledge is no longer explicitly represented, but is represented as a neural network. For a human, it becomes practically impossible to relate the parametrization of the neural network to concrete RL decisions. Deep RL thus essentially appears as a black box, which severely limits the debugging of adaptive systems. We previously introduced the explainable RL technique XRL-DINE, which provides visual insights into why certain decisions were made at important time points. Here, we introduce an empirical user study involving 54 software engineers from academia and industry to assess (1) the performance of software engineers when performing different tasks using XRL-DINE and (2) the perceived usefulness and ease of use of XRL-DINE.
Explaining Online Reinforcement Learning Decisions of Self-Adaptive Systems
Oct 12, 2022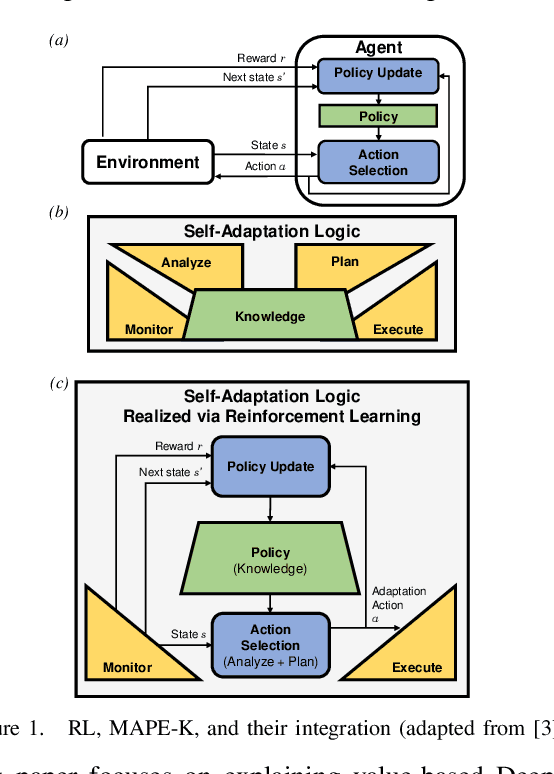
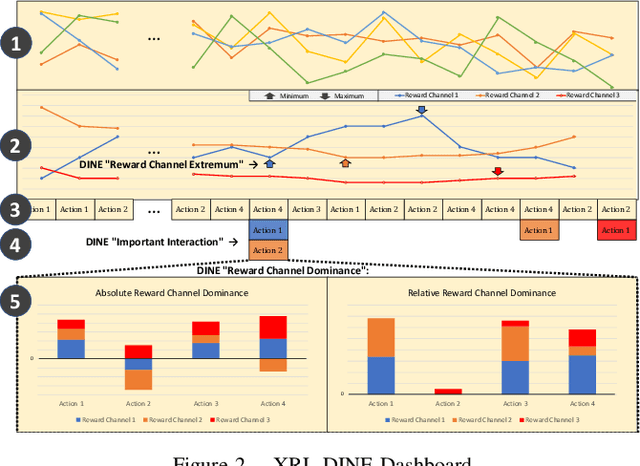
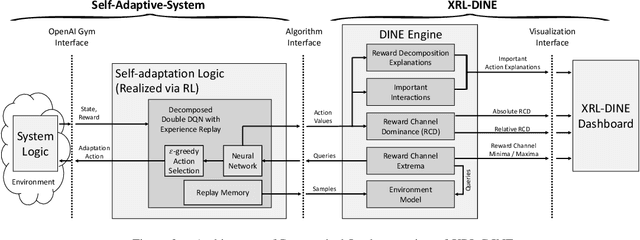
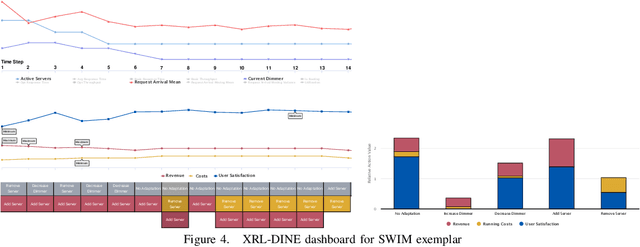
Design time uncertainty poses an important challenge when developing a self-adaptive system. As an example, defining how the system should adapt when facing a new environment state, requires understanding the precise effect of an adaptation, which may not be known at design time. Online reinforcement learning, i.e., employing reinforcement learning (RL) at runtime, is an emerging approach to realizing self-adaptive systems in the presence of design time uncertainty. By using Online RL, the self-adaptive system can learn from actual operational data and leverage feedback only available at runtime. Recently, Deep RL is gaining interest. Deep RL represents learned knowledge as a neural network whereby it can generalize over unseen inputs, as well as handle continuous environment states and adaptation actions. A fundamental problem of Deep RL is that learned knowledge is not explicitly represented. For a human, it is practically impossible to relate the parametrization of the neural network to concrete RL decisions and thus Deep RL essentially appears as a black box. Yet, understanding the decisions made by Deep RL is key to (1) increasing trust, and (2) facilitating debugging. Such debugging is especially relevant for self-adaptive systems, because the reward function, which quantifies the feedback to the RL algorithm, must be defined by developers. The reward function must be explicitly defined by developers, thus introducing a potential for human error. To explain Deep RL for self-adaptive systems, we enhance and combine two existing explainable RL techniques from the machine learning literature. The combined technique, XRL-DINE, overcomes the respective limitations of the individual techniques. We present a proof-of-concept implementation of XRL-DINE, as well as qualitative and quantitative results of applying XRL-DINE to a self-adaptive system exemplar.
Counterfactual Explanations for Predictive Business Process Monitoring
Feb 24, 2022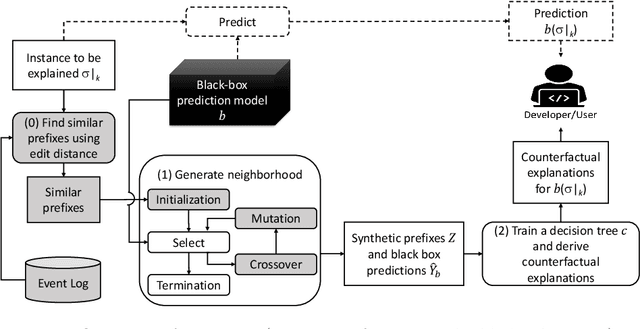
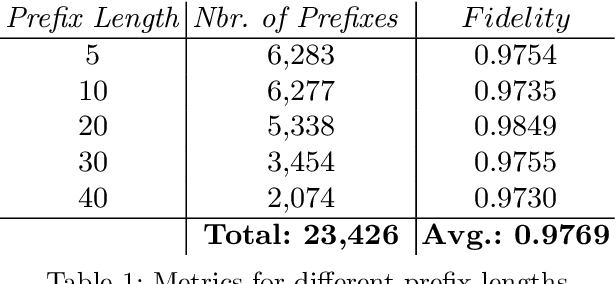
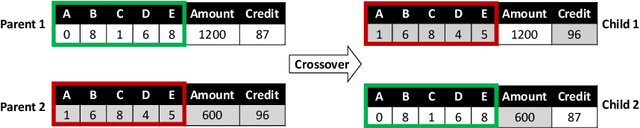
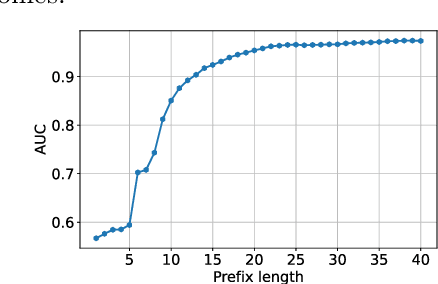
Predictive business process monitoring increasingly leverages sophisticated prediction models. Although sophisticated models achieve consistently higher prediction accuracy than simple models, one major drawback is their lack of interpretability, which limits their adoption in practice. We thus see growing interest in explainable predictive business process monitoring, which aims to increase the interpretability of prediction models. Existing solutions focus on giving factual explanations.While factual explanations can be helpful, humans typically do not ask why a particular prediction was made, but rather why it was made instead of another prediction, i.e., humans are interested in counterfactual explanations. While research in explainable AI produced several promising techniques to generate counterfactual explanations, directly applying them to predictive process monitoring may deliver unrealistic explanations, because they ignore the underlying process constraints. We propose LORELEY, a counterfactual explanation technique for predictive process monitoring, which extends LORE, a recent explainable AI technique. We impose control flow constraints to the explanation generation process to ensure realistic counterfactual explanations. Moreover, we extend LORE to enable explaining multi-class classification models. Experimental results using a real, public dataset indicate that LORELEY can approximate the prediction models with an average fidelity of 97.69\% and generate realistic counterfactual explanations.
Feature-Model-Guided Online Learning for Self-Adaptive Systems
Jul 22, 2019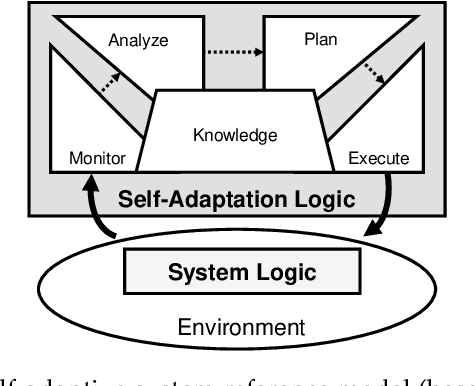
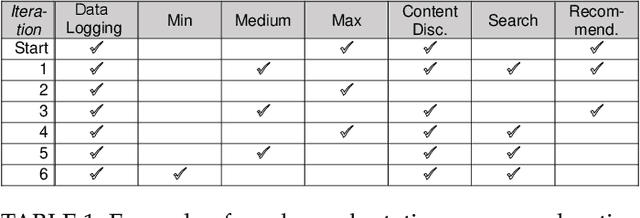
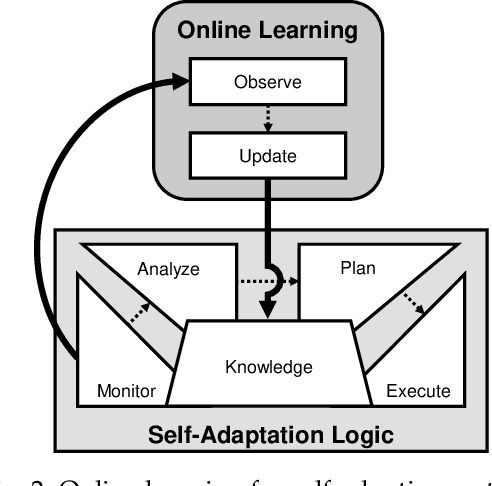
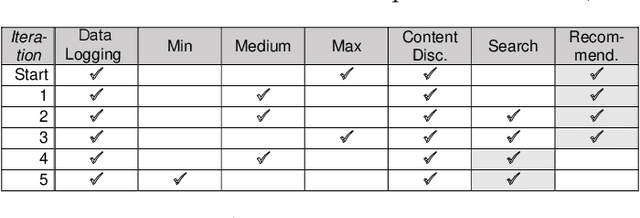
A self-adaptive system can modify its own structure and behavior at runtime based on its perception of the environment, of itself and of its requirements. To develop a self-adaptive system, software developers codify knowledge about the system and its environment, as well as how adaptation actions impact on the system. However, the codified knowledge may be insufficient due to design time uncertainty, and thus a self-adaptive system may execute adaptation actions that do not have the desired effect. Online learning is an emerging approach to address design time uncertainty by employing machine learning at runtime. Online learning accumulates knowledge at runtime by, for instance, exploring not-yet executed adaptation actions. We address two specific problems with respect to online learning for self-adaptive systems. First, the number of possible adaptation actions can be very large. Existing online learning techniques randomly explore the possible adaptation actions, but this can lead to slow convergence of the learning process. Second, the possible adaptation actions can change as a result of system evolution. Existing online learning techniques are unaware of these changes and thus do not explore new adaptation actions, but explore adaptation actions that are no longer valid. We propose using feature models to give structure to the set of adaptation actions and thereby guide the exploration process during online learning. Experimental results involving four real-world systems suggest that considering the hierarchical structure of feature models may speed up convergence by 7.2% on average. Considering the differences between feature models before and after an evolution step may speed up convergence by 64.6% on average. [...]
Self-Learning Cloud Controllers: Fuzzy Q-Learning for Knowledge Evolution
Jul 02, 2015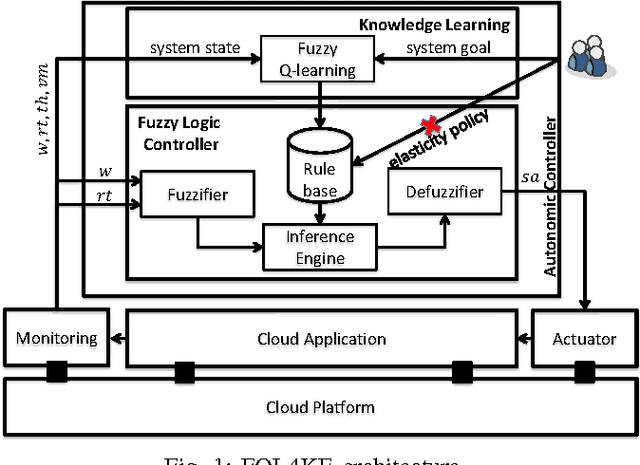
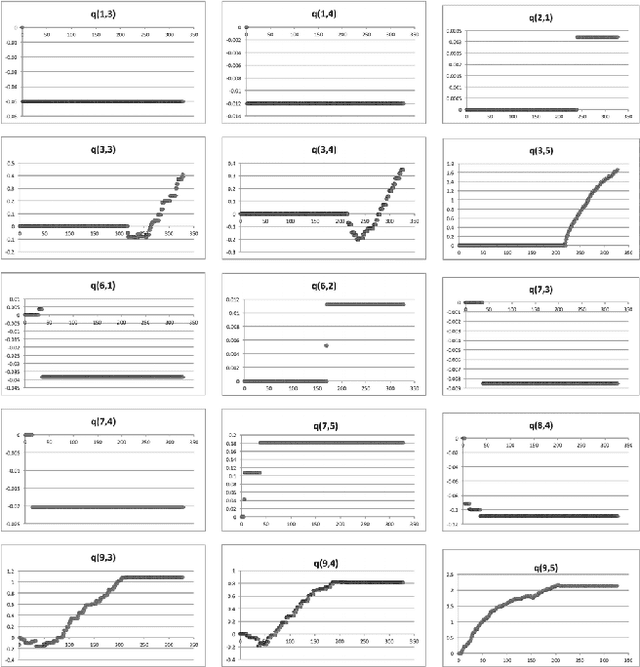
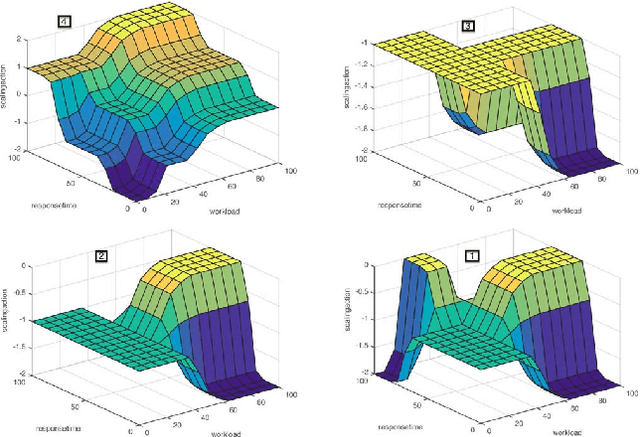
Cloud controllers aim at responding to application demands by automatically scaling the compute resources at runtime to meet performance guarantees and minimize resource costs. Existing cloud controllers often resort to scaling strategies that are codified as a set of adaptation rules. However, for a cloud provider, applications running on top of the cloud infrastructure are more or less black-boxes, making it difficult at design time to define optimal or pre-emptive adaptation rules. Thus, the burden of taking adaptation decisions often is delegated to the cloud application. Yet, in most cases, application developers in turn have limited knowledge of the cloud infrastructure. In this paper, we propose learning adaptation rules during runtime. To this end, we introduce FQL4KE, a self-learning fuzzy cloud controller. In particular, FQL4KE learns and modifies fuzzy rules at runtime. The benefit is that for designing cloud controllers, we do not have to rely solely on precise design-time knowledge, which may be difficult to acquire. FQL4KE empowers users to specify cloud controllers by simply adjusting weights representing priorities in system goals instead of specifying complex adaptation rules. The applicability of FQL4KE has been experimentally assessed as part of the cloud application framework ElasticBench. The experimental results indicate that FQL4KE outperforms our previously developed fuzzy controller without learning mechanisms and the native Azure auto-scaling.