 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparing Ordering Strategies For Process Discovery Using Synthesis Rules
Jan 04, 2023Process discovery aims to learn process models from observed behaviors, i.e., event logs, in the information systems.The discovered models serve as the starting point for process mining techniques that are used to address performance and compliance problems. Compared to the state-of-the-art Inductive Miner, the algorithm applying synthesis rules from the free-choice net theory discovers process models with more flexible (non-block) structures while ensuring the same desirable soundness and free-choiceness properties. Moreover, recent development in this line of work shows that the discovered models have compatible quality. Following the synthesis rules, the algorithm incrementally modifies an existing process model by adding the activities in the event log one at a time. As the applications of rules are highly dependent on the existing model structure, the model quality and computation time are significantly influenced by the order of adding activities. In this paper, we investigate the effect of different ordering strategies on the discovered models (w.r.t. fitness and precision) and the computation time using real-life event data. The results show that the proposed ordering strategy can improve the quality of the resulting process models while requiring less time compared to the ordering strategy solely based on the frequency of activities.
Counterfactual Explanations for Predictive Business Process Monitoring
Feb 24, 2022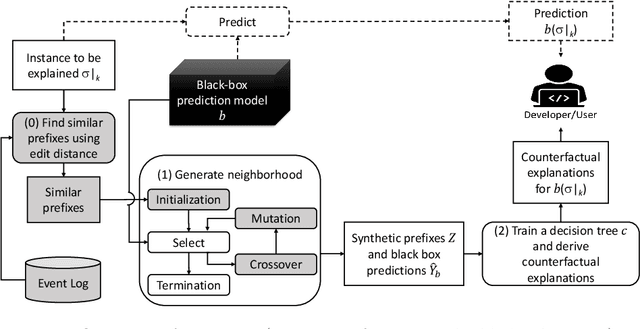
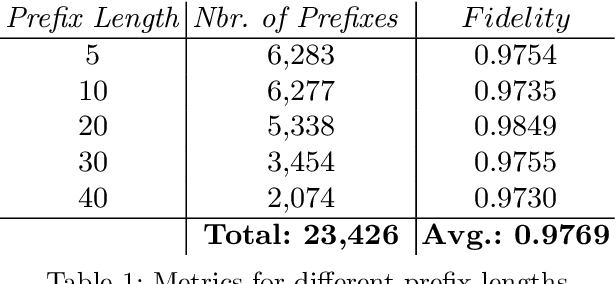
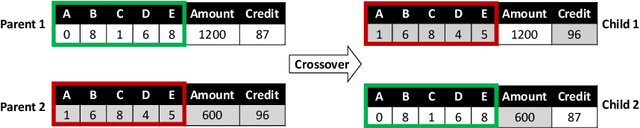
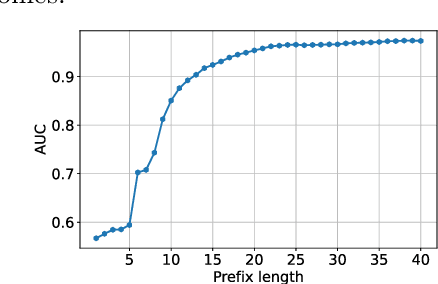
Predictive business process monitoring increasingly leverages sophisticated prediction models. Although sophisticated models achieve consistently higher prediction accuracy than simple models, one major drawback is their lack of interpretability, which limits their adoption in practice. We thus see growing interest in explainable predictive business process monitoring, which aims to increase the interpretability of prediction models. Existing solutions focus on giving factual explanations.While factual explanations can be helpful, humans typically do not ask why a particular prediction was made, but rather why it was made instead of another prediction, i.e., humans are interested in counterfactual explanations. While research in explainable AI produced several promising techniques to generate counterfactual explanations, directly applying them to predictive process monitoring may deliver unrealistic explanations, because they ignore the underlying process constraints. We propose LORELEY, a counterfactual explanation technique for predictive process monitoring, which extends LORE, a recent explainable AI technique. We impose control flow constraints to the explanation generation process to ensure realistic counterfactual explanations. Moreover, we extend LORE to enable explaining multi-class classification models. Experimental results using a real, public dataset indicate that LORELEY can approximate the prediction models with an average fidelity of 97.69\% and generate realistic counterfactual explanations.