 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNonparametric Distribution Regression Re-calibration
Feb 13, 2026A key challenge in probabilistic regression is ensuring that predictive distributions accurately reflect true empirical uncertainty. Minimizing overall prediction error often encourages models to prioritize informativeness over calibration, producing narrow but overconfident predictions. However, in safety-critical settings, trustworthy uncertainty estimates are often more valuable than narrow intervals. Realizing the problem, several recent works have focused on post-hoc corrections; however, existing methods either rely on weak notions of calibration (such as PIT uniformity) or impose restrictive parametric assumptions on the nature of the error. To address these limitations, we propose a novel nonparametric re-calibration algorithm based on conditional kernel mean embeddings, capable of correcting calibration error without restrictive modeling assumptions. For efficient inference with real-valued targets, we introduce a novel characteristic kernel over distributions that can be evaluated in $\mathcal{O}(n \log n)$ time for empirical distributions of size $n$. We demonstrate that our method consistently outperforms prior re-calibration approaches across a diverse set of regression benchmarks and model classes.
Theoretical Evaluation of Asymmetric Shapley Values for Root-Cause Analysis
Oct 15, 2023In this work, we examine Asymmetric Shapley Values (ASV), a variant of the popular SHAP additive local explanation method. ASV proposes a way to improve model explanations incorporating known causal relations between variables, and is also considered as a way to test for unfair discrimination in model predictions. Unexplored in previous literature, relaxing symmetry in Shapley values can have counter-intuitive consequences for model explanation. To better understand the method, we first show how local contributions correspond to global contributions of variance reduction. Using variance, we demonstrate multiple cases where ASV yields counter-intuitive attributions, arguably producing incorrect results for root-cause analysis. Second, we identify generalized additive models (GAM) as a restricted class for which ASV exhibits desirable properties. We support our arguments by proving multiple theoretical results about the method. Finally, we demonstrate the use of asymmetric attributions on multiple real-world datasets, comparing the results with and without restricted model families using gradient boosting and deep learning models.
Vaccine skepticism detection by network embedding
Oct 20, 2021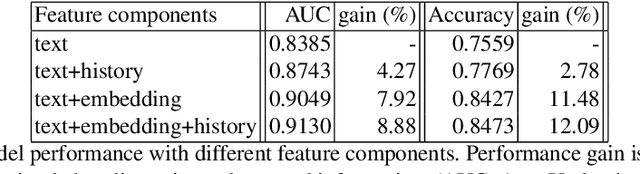
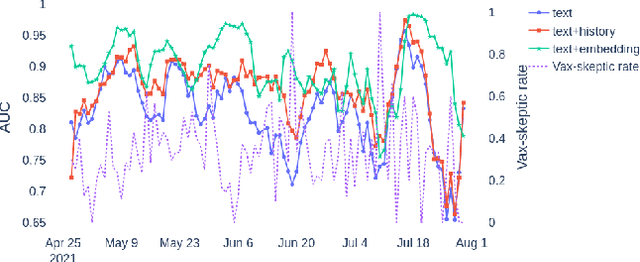
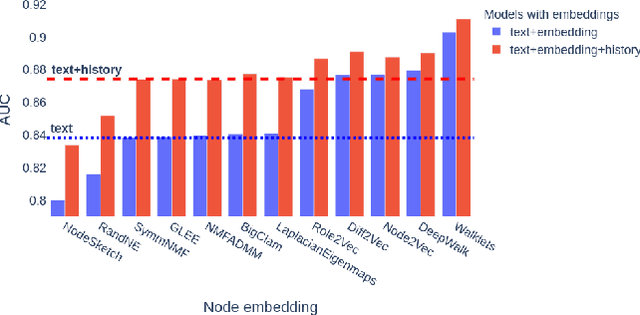
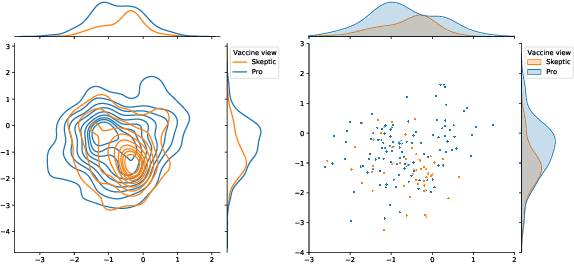
We demonstrate the applicability of network embedding to vaccine skepticism, a controversial topic of long-past history. With the Covid-19 pandemic outbreak at the end of 2019, the topic is more important than ever. Only a year after the first international cases were registered, multiple vaccines were developed and passed clinical testing. Besides the challenges of development, testing, and logistics, another factor that might play a significant role in the fight against the pandemic are people who are hesitant to get vaccinated, or even state that they will refuse any vaccine offered to them. Two groups of people commonly referred to as a) pro-vaxxer, those who support vaccinating people b) vax-skeptic, those who question vaccine efficacy or the need for general vaccination against Covid-19. It is very difficult to tell exactly how many people share each of these views. It is even more difficult to understand all the reasoning why vax-skeptic opinions are getting more popular. In this work, our intention was to develop techniques that are able to efficiently differentiate between pro-vaxxer and vax-skeptic content. After multiple data preprocessing steps, we analyzed the tweet text as well as the structure of user interactions on Twitter. We deployed several node embedding and community detection models that scale well for graphs with millions of edges.
* The data and the source code are available on GitHub: https://github.com/ferencberes/covid-vaccine-network
Online Machine Learning in Big Data Streams
Feb 16, 2018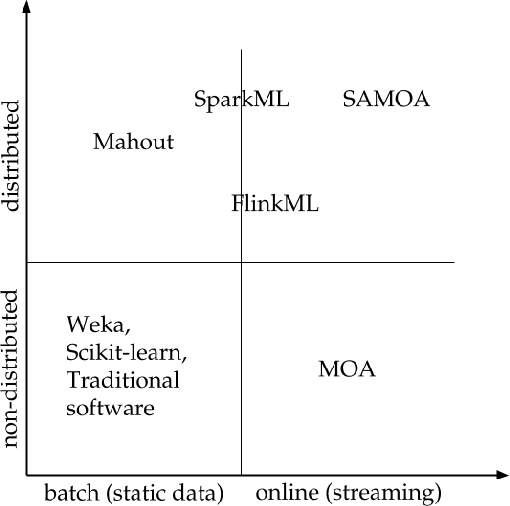
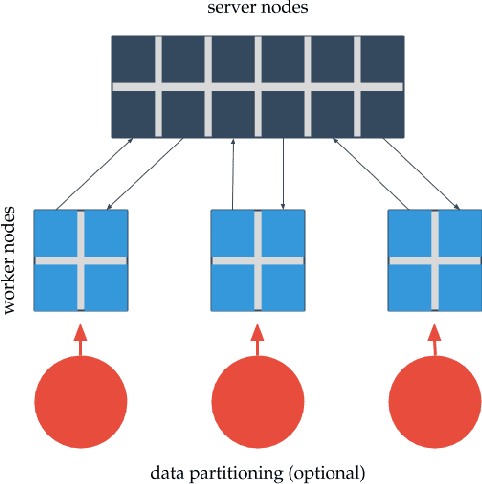
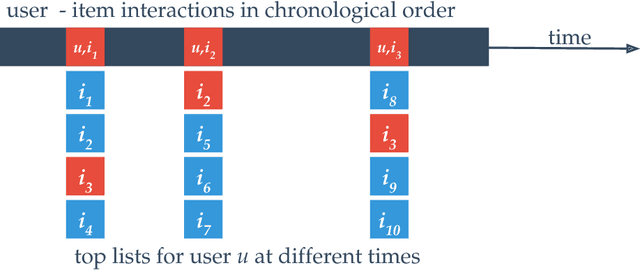
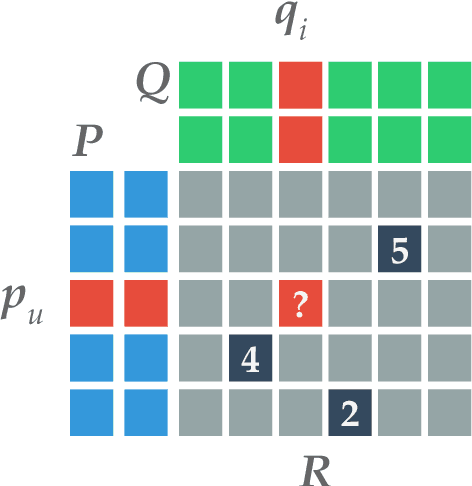
The area of online machine learning in big data streams covers algorithms that are (1) distributed and (2) work from data streams with only a limited possibility to store past data. The first requirement mostly concerns software architectures and efficient algorithms. The second one also imposes nontrivial theoretical restrictions on the modeling methods: In the data stream model, older data is no longer available to revise earlier suboptimal modeling decisions as the fresh data arrives. In this article, we provide an overview of distributed software architectures and libraries as well as machine learning models for online learning. We highlight the most important ideas for classification, regression, recommendation, and unsupervised modeling from streaming data, and we show how they are implemented in various distributed data stream processing systems. This article is a reference material and not a survey. We do not attempt to be comprehensive in describing all existing methods and solutions; rather, we give pointers to the most important resources in the field. All related sub-fields, online algorithms, online learning, and distributed data processing are hugely dominant in current research and development with conceptually new research results and software components emerging at the time of writing. In this article, we refer to several survey results, both for distributed data processing and for online machine learning. Compared to past surveys, our article is different because we discuss recommender systems in extended detail.
Métodos para la Selección y el Ajuste de Características en el Problema de la Detección de Spam
Oct 14, 2010The email is used daily by millions of people to communicate around the globe and it is a mission-critical application for many businesses. Over the last decade, unsolicited bulk email has become a major problem for email users. An overwhelming amount of spam is flowing into users' mailboxes daily. In 2004, an estimated 62% of all email was attributed to spam. Spam is not only frustrating for most email users, it strains the IT infrastructure of organizations and costs businesses billions of dollars in lost productivity. In recent years, spam has evolved from an annoyance into a serious security threat, and is now a prime medium for phishing of sensitive information, as well the spread of malicious software. This work presents a first approach to attack the spam problem. We propose an algorithm that will improve a classifier's results by adjusting its training set data. It improves the document's vocabulary representation by detecting good topic descriptors and discriminators.
* 5 pages, 1 figure, Workshop de Investigadores en Ciencias de la Computaci\'{o}n, WICC 2010, pp 48-52