 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Machine Learning in Big Data Streams
Paper and Code
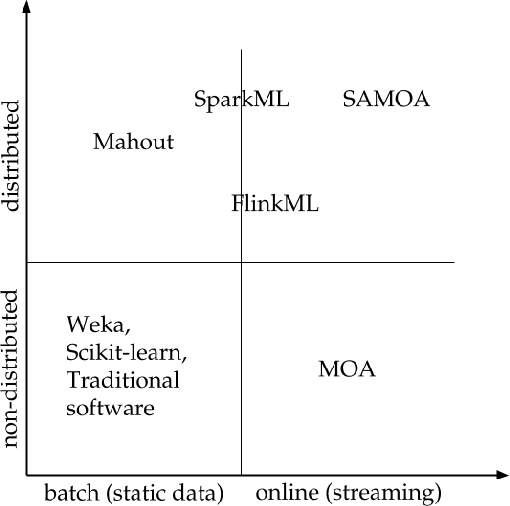
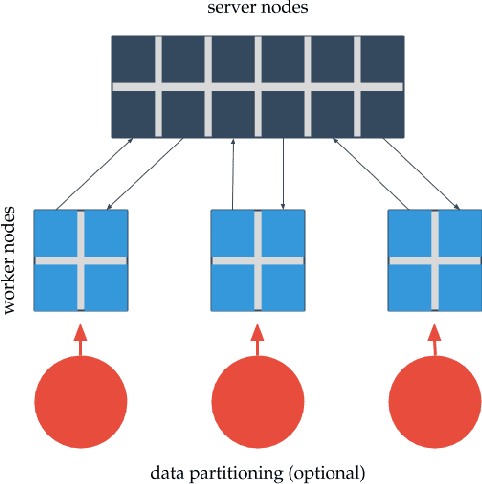
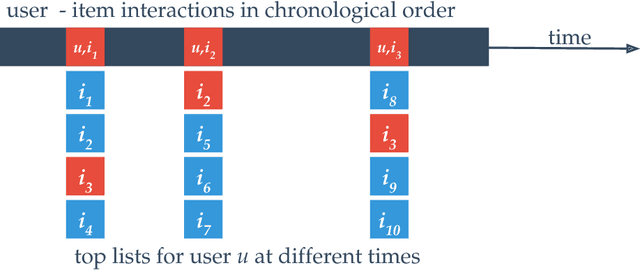
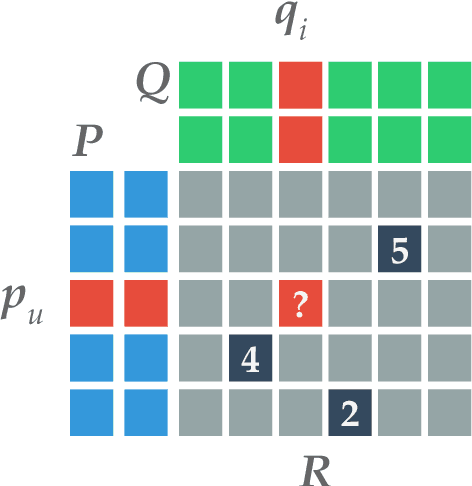
The area of online machine learning in big data streams covers algorithms that are (1) distributed and (2) work from data streams with only a limited possibility to store past data. The first requirement mostly concerns software architectures and efficient algorithms. The second one also imposes nontrivial theoretical restrictions on the modeling methods: In the data stream model, older data is no longer available to revise earlier suboptimal modeling decisions as the fresh data arrives. In this article, we provide an overview of distributed software architectures and libraries as well as machine learning models for online learning. We highlight the most important ideas for classification, regression, recommendation, and unsupervised modeling from streaming data, and we show how they are implemented in various distributed data stream processing systems. This article is a reference material and not a survey. We do not attempt to be comprehensive in describing all existing methods and solutions; rather, we give pointers to the most important resources in the field. All related sub-fields, online algorithms, online learning, and distributed data processing are hugely dominant in current research and development with conceptually new research results and software components emerging at the time of writing. In this article, we refer to several survey results, both for distributed data processing and for online machine learning. Compared to past surveys, our article is different because we discuss recommender systems in extended detail.