 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHarnessing Geometric Constraints from Auxiliary Labels to Improve Embedding Functions for One-Shot Learning
Mar 05, 2021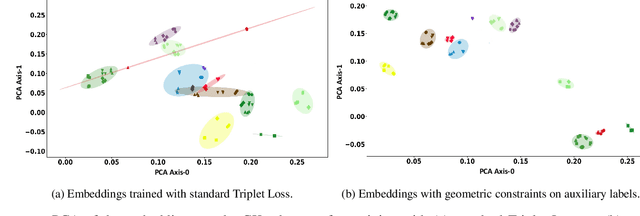
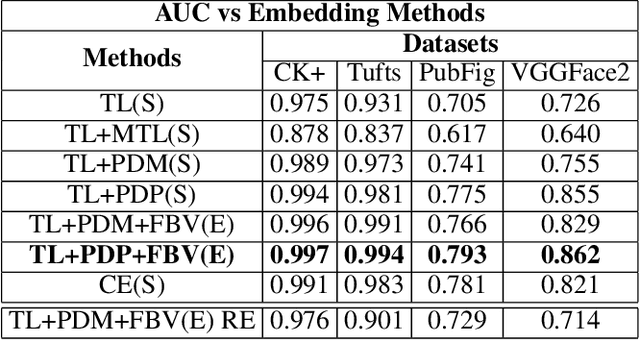

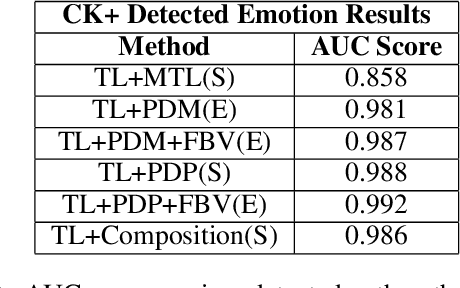
We explore the utility of harnessing auxiliary labels (e.g., facial expression) to impose geometric structure when training embedding models for one-shot learning (e.g., for face verification). We introduce novel geometric constraints on the embedding space learned by a deep model using either manually annotated or automatically detected auxiliary labels. We contrast their performances (AUC) on four different face datasets(CK+, VGGFace-2, Tufts Face, and PubFig). Due to the additional structure encoded in the embedding space, our methods provide a higher verification accuracy (99.7, 86.2, 99.4, and 79.3% with our proposed TL+PDP+FBV loss, versus 97.5, 72.6, 93.1, and 70.5% using a standard Triplet Loss on the four datasets, respectively). Our method is implemented purely in terms of the loss function. It does not require any changes to the backbone of the embedding functions.
A novel residual whitening based training to avoid overfitting
Aug 08, 2020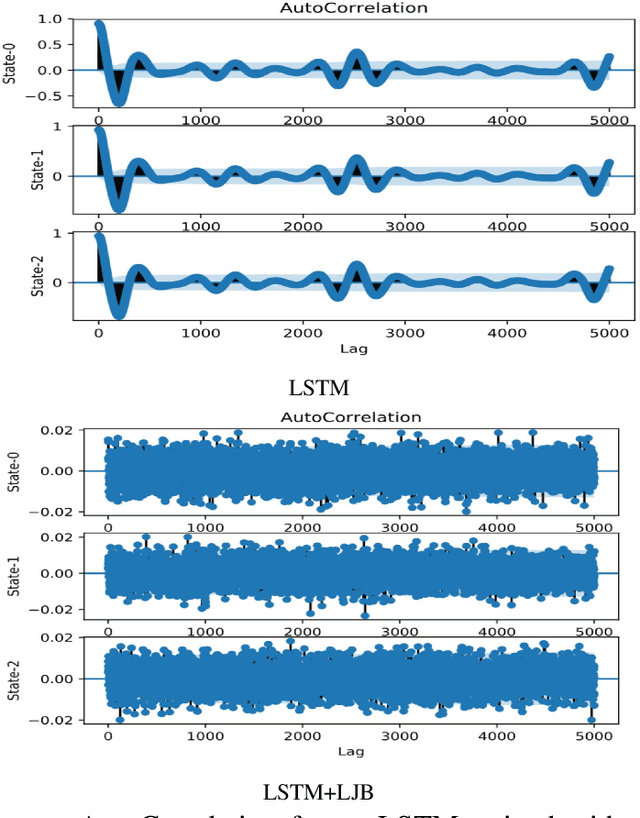
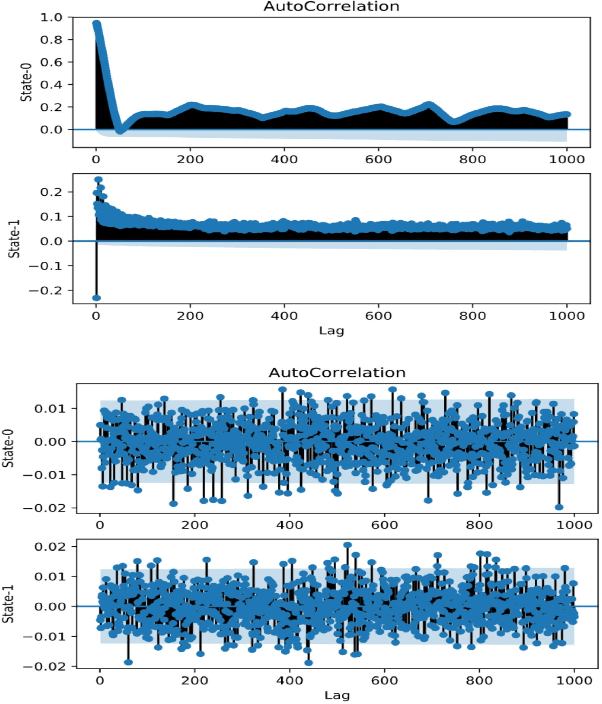

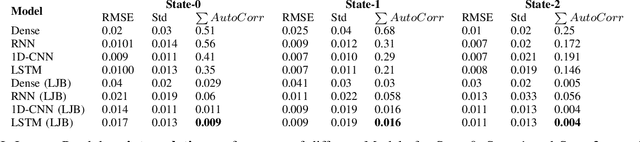
In this paper we demonstrate that training models to minimize the autocorrelation of the residuals as an additional penalty prevents overfitting of the machine learning models. We use different problem extrapolative testing sets, and invoking decorrelation objective functions, we create models that can predict more complex systems. The models are interpretable, extrapolative, data-efficient, and capture predictable but complex non-stochastic behavior such as unmodeled degrees of freedom and systemic measurement noise. We apply this improved modeling paradigm to several simulated systems and an actual physical system in the context of system identification. Several ways of composing domain models with neural models are examined for time series, boosting, bagging, and auto-encoding on various systems of varying complexity and non-linearity. Although this work is preliminary, we show that the ability to combine models is a very promising direction for neural modeling.
Toward Automated Classroom Observation: Multimodal Machine Learning to Estimate CLASS Positive Climate and Negative Climate
May 19, 2020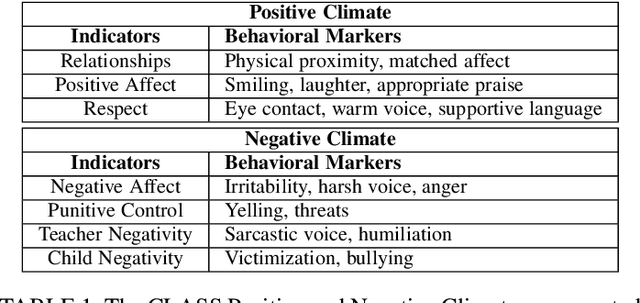
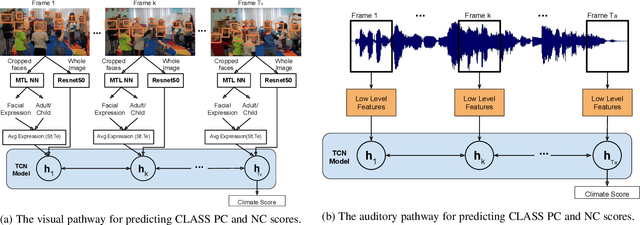
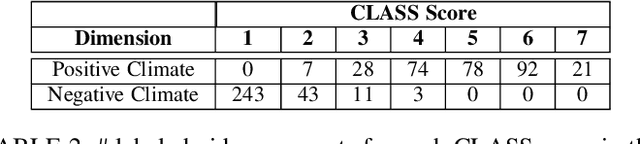

In this work we present a multi-modal machine learning-based system, which we call ACORN, to analyze videos of school classrooms for the Positive Climate (PC) and Negative Climate (NC) dimensions of the CLASS observation protocol that is widely used in educational research. ACORN uses convolutional neural networks to analyze spectral audio features, the faces of teachers and students, and the pixels of each image frame, and then integrates this information over time using Temporal Convolutional Networks. The audiovisual ACORN's PC and NC predictions have Pearson correlations of $0.55$ and $0.63$ with ground-truth scores provided by expert CLASS coders on the UVA Toddler dataset (cross-validation on $n=300$ 15-min video segments), and a purely auditory ACORN predicts PC and NC with correlations of $0.36$ and $0.41$ on the MET dataset (test set of $n=2000$ videos segments). These numbers are similar to inter-coder reliability of human coders. Finally, using Graph Convolutional Networks we make early strides (AUC=$0.70$) toward predicting the specific moments (45-90sec clips) when the PC is particularly weak/strong. Our findings inform the design of automatic classroom observation and also more general video activity recognition and summary recognition systems.