 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHarnessing Geometric Constraints from Auxiliary Labels to Improve Embedding Functions for One-Shot Learning
Paper and Code
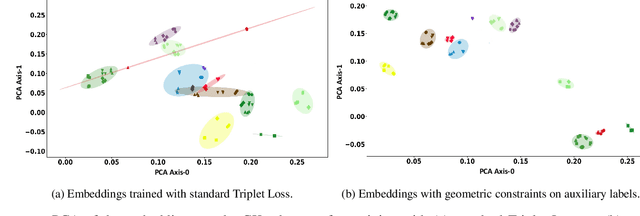
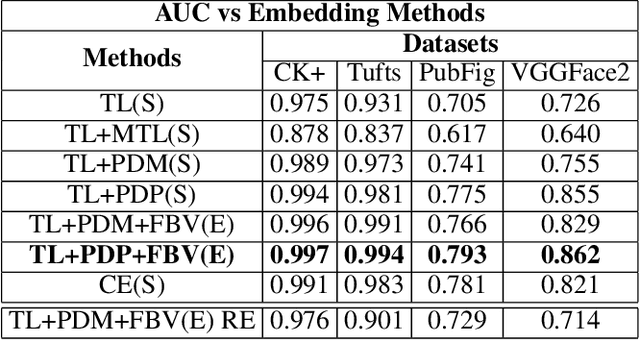

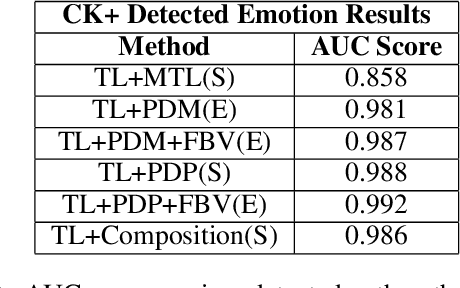
We explore the utility of harnessing auxiliary labels (e.g., facial expression) to impose geometric structure when training embedding models for one-shot learning (e.g., for face verification). We introduce novel geometric constraints on the embedding space learned by a deep model using either manually annotated or automatically detected auxiliary labels. We contrast their performances (AUC) on four different face datasets(CK+, VGGFace-2, Tufts Face, and PubFig). Due to the additional structure encoded in the embedding space, our methods provide a higher verification accuracy (99.7, 86.2, 99.4, and 79.3% with our proposed TL+PDP+FBV loss, versus 97.5, 72.6, 93.1, and 70.5% using a standard Triplet Loss on the four datasets, respectively). Our method is implemented purely in terms of the loss function. It does not require any changes to the backbone of the embedding functions.