 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData-driven models and computational tools for neurolinguistics: a language technology perspective
Mar 23, 2020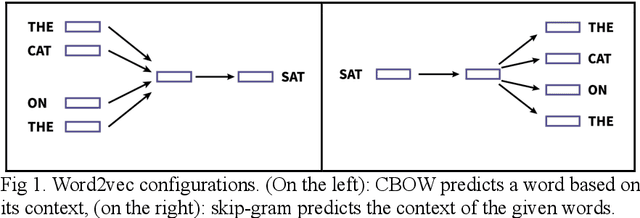
In this paper, our focus is the connection and influence of language technologies on the research in neurolinguistics. We present a review of brain imaging-based neurolinguistic studies with a focus on the natural language representations, such as word embeddings and pre-trained language models. Mutual enrichment of neurolinguistics and language technologies leads to development of brain-aware natural language representations. The importance of this research area is emphasized by medical applications.
* 37 pages, 1 figure
The Limitations of Cross-language Word Embeddings Evaluation
Jun 06, 2018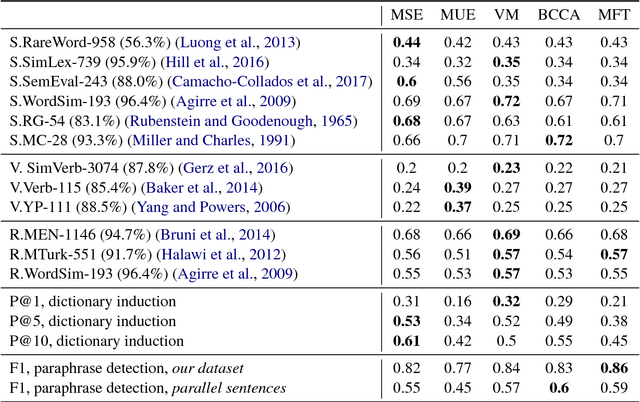

The aim of this work is to explore the possible limitations of existing methods of cross-language word embeddings evaluation, addressing the lack of correlation between intrinsic and extrinsic cross-language evaluation methods. To prove this hypothesis, we construct English-Russian datasets for extrinsic and intrinsic evaluation tasks and compare performances of 5 different cross-language models on them. The results say that the scores even on different intrinsic benchmarks do not correlate to each other. We can conclude that the use of human references as ground truth for cross-language word embeddings is not proper unless one does not understand how do native speakers process semantics in their cognition.
Can Eye Movement Data Be Used As Ground Truth For Word Embeddings Evaluation?
Apr 23, 2018
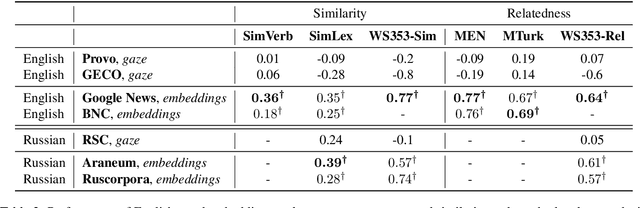

In recent years a certain success in the task of modeling lexical semantics was obtained with distributional semantic models. Nevertheless, the scientific community is still unaware what is the most reliable evaluation method for these models. Some researchers argue that the only possible gold standard could be obtained from neuro-cognitive resources that store information about human cognition. One of such resources is eye movement data on silent reading. The goal of this work is to test the hypothesis of whether such data could be used to evaluate distributional semantic models on different languages. We propose experiments with English and Russian eye movement datasets (Provo Corpus, GECO and Russian Sentence Corpus), word vectors (Skip-Gram models trained on national corpora and Web corpora) and word similarity datasets of Russian and English assessed by humans in order to find the existence of correlation between embeddings and eye movement data and test the hypothesis that this correlation is language independent. As a result, we found that the validity of the hypothesis being tested could be questioned.
A Survey of Word Embeddings Evaluation Methods
Jan 21, 2018Word embeddings are real-valued word representations able to capture lexical semantics and trained on natural language corpora. Models proposing these representations have gained popularity in the recent years, but the issue of the most adequate evaluation method still remains open. This paper presents an extensive overview of the field of word embeddings evaluation, highlighting main problems and proposing a typology of approaches to evaluation, summarizing 16 intrinsic methods and 12 extrinsic methods. I describe both widely-used and experimental methods, systematize information about evaluation datasets and discuss some key challenges.
Automated Detection of Non-Relevant Posts on the Russian Imageboard "2ch": Importance of the Choice of Word Representations
Jul 16, 2017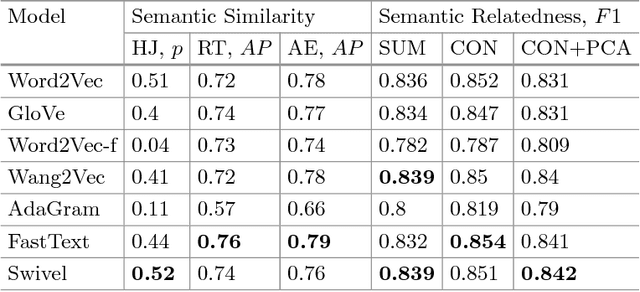

This study considers the problem of automated detection of non-relevant posts on Web forums and discusses the approach of resolving this problem by approximation it with the task of detection of semantic relatedness between the given post and the opening post of the forum discussion thread. The approximated task could be resolved through learning the supervised classifier with a composed word embeddings of two posts. Considering that the success in this task could be quite sensitive to the choice of word representations, we propose a comparison of the performance of different word embedding models. We train 7 models (Word2Vec, Glove, Word2Vec-f, Wang2Vec, AdaGram, FastText, Swivel), evaluate embeddings produced by them on dataset of human judgements and compare their performance on the task of non-relevant posts detection. To make the comparison, we propose a dataset of semantic relatedness with posts from one of the most popular Russian Web forums, imageboard "2ch", which has challenging lexical and grammatical features.