 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated Detection of Non-Relevant Posts on the Russian Imageboard "2ch": Importance of the Choice of Word Representations
Paper and Code
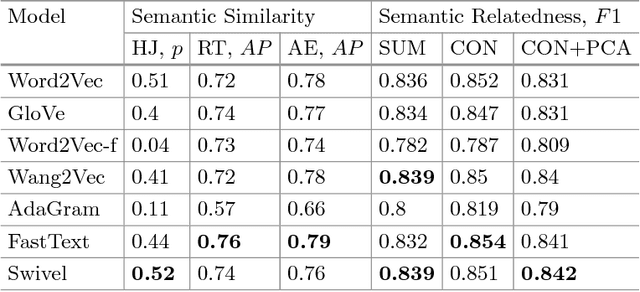

This study considers the problem of automated detection of non-relevant posts on Web forums and discusses the approach of resolving this problem by approximation it with the task of detection of semantic relatedness between the given post and the opening post of the forum discussion thread. The approximated task could be resolved through learning the supervised classifier with a composed word embeddings of two posts. Considering that the success in this task could be quite sensitive to the choice of word representations, we propose a comparison of the performance of different word embedding models. We train 7 models (Word2Vec, Glove, Word2Vec-f, Wang2Vec, AdaGram, FastText, Swivel), evaluate embeddings produced by them on dataset of human judgements and compare their performance on the task of non-relevant posts detection. To make the comparison, we propose a dataset of semantic relatedness with posts from one of the most popular Russian Web forums, imageboard "2ch", which has challenging lexical and grammatical features.