 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCOLMAP-Free 3D Gaussian Splatting
Dec 12, 2023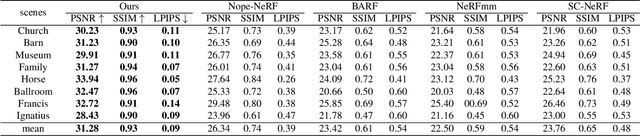
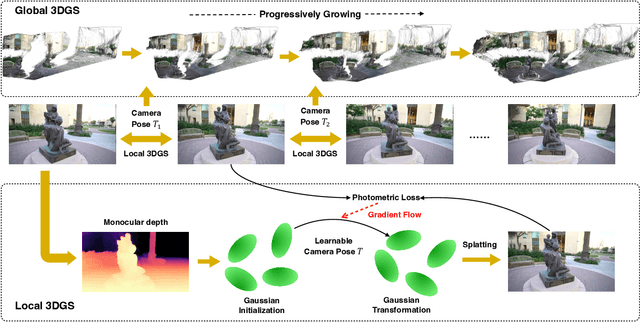
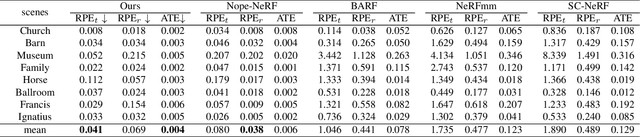

While neural rendering has led to impressive advances in scene reconstruction and novel view synthesis, it relies heavily on accurately pre-computed camera poses. To relax this constraint, multiple efforts have been made to train Neural Radiance Fields (NeRFs) without pre-processed camera poses. However, the implicit representations of NeRFs provide extra challenges to optimize the 3D structure and camera poses at the same time. On the other hand, the recently proposed 3D Gaussian Splatting provides new opportunities given its explicit point cloud representations. This paper leverages both the explicit geometric representation and the continuity of the input video stream to perform novel view synthesis without any SfM preprocessing. We process the input frames in a sequential manner and progressively grow the 3D Gaussians set by taking one input frame at a time, without the need to pre-compute the camera poses. Our method significantly improves over previous approaches in view synthesis and camera pose estimation under large motion changes. Our project page is https://oasisyang.github.io/colmap-free-3dgs
3D Reconstruction with Generalizable Neural Fields using Scene Priors
Sep 29, 2023



High-fidelity 3D scene reconstruction has been substantially advanced by recent progress in neural fields. However, most existing methods train a separate network from scratch for each individual scene. This is not scalable, inefficient, and unable to yield good results given limited views. While learning-based multi-view stereo methods alleviate this issue to some extent, their multi-view setting makes it less flexible to scale up and to broad applications. Instead, we introduce training generalizable Neural Fields incorporating scene Priors (NFPs). The NFP network maps any single-view RGB-D image into signed distance and radiance values. A complete scene can be reconstructed by merging individual frames in the volumetric space WITHOUT a fusion module, which provides better flexibility. The scene priors can be trained on large-scale datasets, allowing for fast adaptation to the reconstruction of a new scene with fewer views. NFP not only demonstrates SOTA scene reconstruction performance and efficiency, but it also supports single-image novel-view synthesis, which is underexplored in neural fields. More qualitative results are available at: https://oasisyang.github.io/neural-prior
Image Inpainting using Partial Convolution
Aug 19, 2021



Image Inpainting is one of the very popular tasks in the field of image processing with broad applications in computer vision. In various practical applications, images are often deteriorated by noise due to the presence of corrupted, lost, or undesirable information. There have been various restoration techniques used in the past with both classical and deep learning approaches for handling such issues. Some traditional methods include image restoration by filling gap pixels using the nearby known pixels or using the moving average over the same. The aim of this paper is to perform image inpainting using robust deep learning methods that use partial convolution layers.