 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModeling the AC Power Flow Equations with Optimally Compact Neural Networks: Application to Unit Commitment
Oct 28, 2021



Nonlinear power flow constraints render a variety of power system optimization problems computationally intractable. Emerging research shows, however, that the nonlinear AC power flow equations can be successfully modeled using Neural Networks (NNs). These NNs can be exactly transformed into Mixed Integer Linear Programs (MILPs) and embedded inside challenging optimization problems, thus replacing nonlinearities that are intractable for many applications with tractable piecewise linear approximations. Such approaches, though, suffer from an explosion of the number of binary variables needed to represent the NN. Accordingly, this paper develops a technique for training an "optimally compact" NN, i.e., one that can represent the power flow equations with a sufficiently high degree of accuracy while still maintaining a tractable number of binary variables. We show that the resulting NN model is more expressive than both the DC and linearized power flow approximations when embedded inside of a challenging optimization problem (i.e., the AC unit commitment problem).
A Reinforcement Learning Approach to Parameter Selection for Distributed Optimization in Power Systems
Oct 22, 2021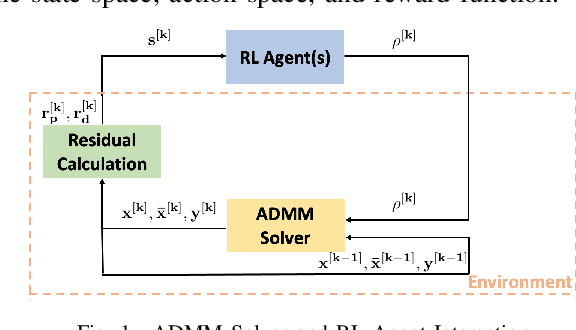
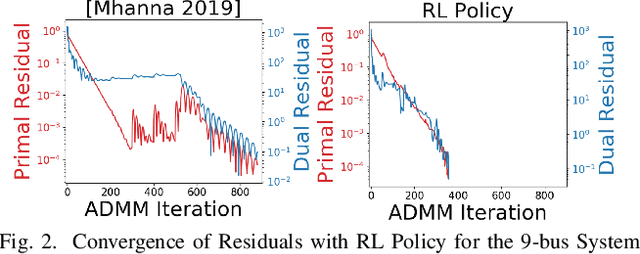
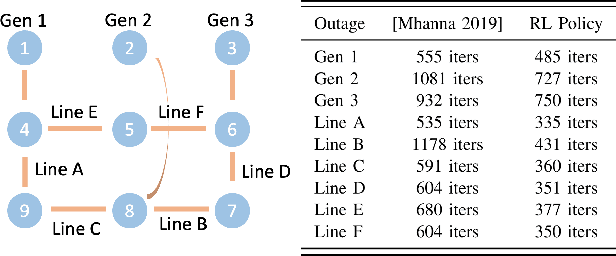
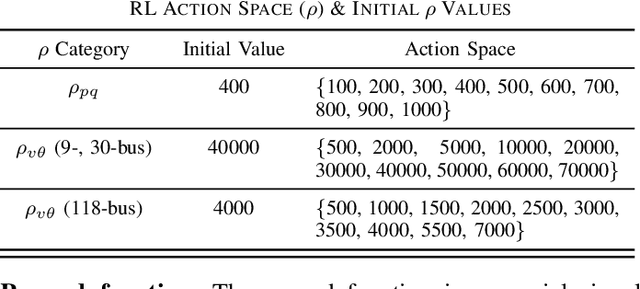
With the increasing penetration of distributed energy resources, distributed optimization algorithms have attracted significant attention for power systems applications due to their potential for superior scalability, privacy, and robustness to a single point-of-failure. The Alternating Direction Method of Multipliers (ADMM) is a popular distributed optimization algorithm; however, its convergence performance is highly dependent on the selection of penalty parameters, which are usually chosen heuristically. In this work, we use reinforcement learning (RL) to develop an adaptive penalty parameter selection policy for the AC optimal power flow (ACOPF) problem solved via ADMM with the goal of minimizing the number of iterations until convergence. We train our RL policy using deep Q-learning, and show that this policy can result in significantly accelerated convergence (up to a 59% reduction in the number of iterations compared to existing, curvature-informed penalty parameter selection methods). Furthermore, we show that our RL policy demonstrates promise for generalizability, performing well under unseen loading schemes as well as under unseen losses of lines and generators (up to a 50% reduction in iterations). This work thus provides a proof-of-concept for using RL for parameter selection in ADMM for power systems applications.