 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Reinforcement Learning Approach to Parameter Selection for Distributed Optimization in Power Systems
Oct 22, 2021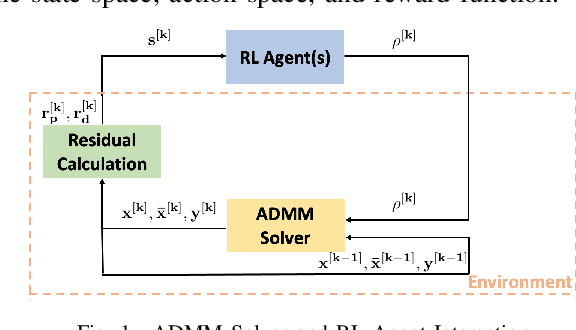
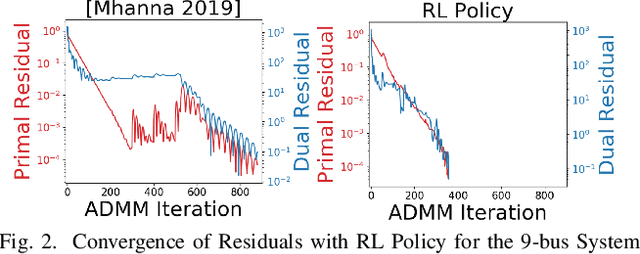
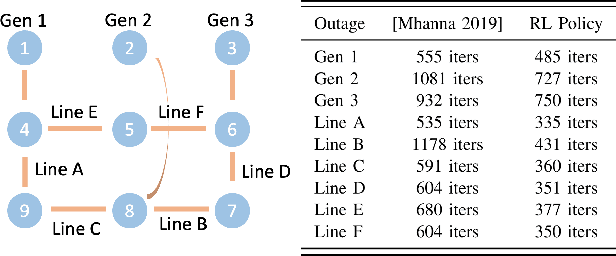
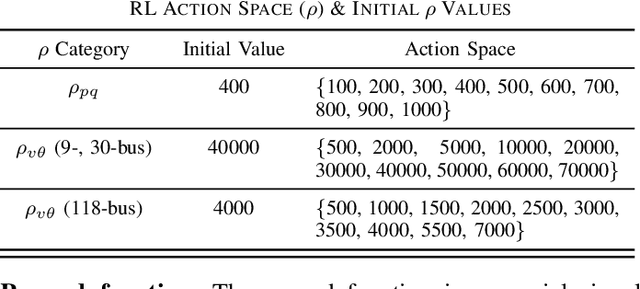
With the increasing penetration of distributed energy resources, distributed optimization algorithms have attracted significant attention for power systems applications due to their potential for superior scalability, privacy, and robustness to a single point-of-failure. The Alternating Direction Method of Multipliers (ADMM) is a popular distributed optimization algorithm; however, its convergence performance is highly dependent on the selection of penalty parameters, which are usually chosen heuristically. In this work, we use reinforcement learning (RL) to develop an adaptive penalty parameter selection policy for the AC optimal power flow (ACOPF) problem solved via ADMM with the goal of minimizing the number of iterations until convergence. We train our RL policy using deep Q-learning, and show that this policy can result in significantly accelerated convergence (up to a 59% reduction in the number of iterations compared to existing, curvature-informed penalty parameter selection methods). Furthermore, we show that our RL policy demonstrates promise for generalizability, performing well under unseen loading schemes as well as under unseen losses of lines and generators (up to a 50% reduction in iterations). This work thus provides a proof-of-concept for using RL for parameter selection in ADMM for power systems applications.