 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCritical biblical studies via word frequency analysis: unveiling text authorship
Oct 24, 2024

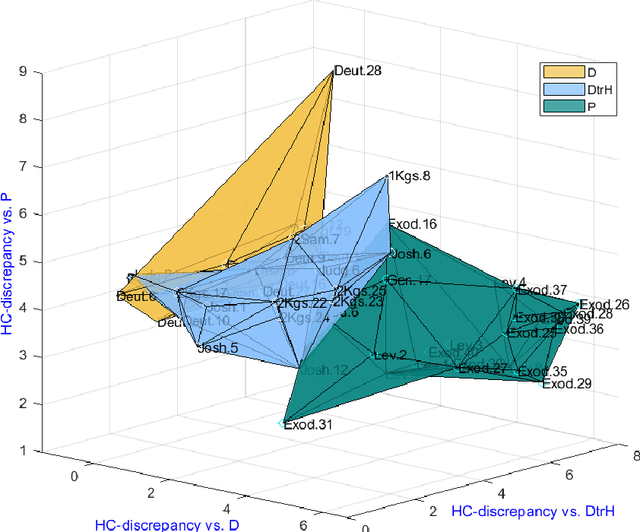
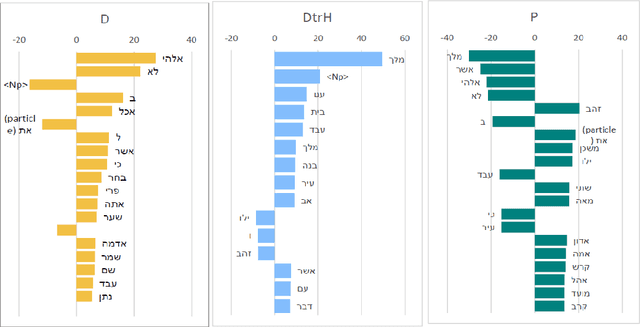
The Bible, a product of an extensive and intricate process of oral-written transmission spanning centuries, obscures the contours of its earlier recensions. Debate rages over determining the existing layers and identifying the date of composition and historical background of the biblical texts. Traditional manual methodologies have grappled with authorship challenges through scrupulous textual criticism, employing linguistic, stylistic, inner-biblical, and historical criteria. Despite recent progress in computer-assisted analysis, many patterns still need to be uncovered in Biblical Texts. In this study, we address the question of authorship of biblical texts by employing statistical analysis to the frequency of words using a method that is particularly sensitive to deviations in frequencies associated with a few words out of potentially many. We aim to differentiate between three distinct authors across numerous chapters spanning the first nine books of the Bible. In particular, we examine 50 chapters labeled according to biblical exegesis considerations into three corpora (D, DtrH, and P). Without prior assumptions about author identity, our approach leverages subtle differences in word frequencies to distinguish among the three corpora and identify author-dependent linguistic properties. Our analysis indicates that the first two authors (D and DtrH) are much more closely related compared to P, a fact that aligns with expert assessments. Additionally, we attain high accuracy in attributing authorship by evaluating the similarity of each chapter with the reference corpora. This study sheds new light on the authorship of biblical texts by providing interpretable, statistically significant evidence that there are different linguistic characteristics of biblical authors and that these differences can be identified.
EntropyRank: Unsupervised Keyphrase Extraction via Side-Information Optimization for Language Model-based Text Compression
Aug 29, 2023

We propose an unsupervised method to extract keywords and keyphrases from texts based on a pre-trained language model (LM) and Shannon's information maximization. Specifically, our method extracts phrases having the highest conditional entropy under the LM. The resulting set of keyphrases turns out to solve a relevant information-theoretic problem: if provided as side information, it leads to the expected minimal binary code length in compressing the text using the LM and an entropy encoder. Alternately, the resulting set is an approximation via a causal LM to the set of phrases that minimize the entropy of the text when conditioned upon it. Empirically, the method provides results comparable to the most commonly used methods in various keyphrase extraction benchmark challenges.
Separating the Human Touch from AI-Generated Text using Higher Criticism: An Information-Theoretic Approach
Aug 24, 2023We propose a method to determine whether a given article was entirely written by a generative language model versus an alternative situation in which the article includes some significant edits by a different author, possibly a human. Our process involves many perplexity tests for the origin of individual sentences or other text atoms, combining these multiple tests using Higher Criticism (HC). As a by-product, the method identifies parts suspected to be edited. The method is motivated by the convergence of the log-perplexity to the cross-entropy rate and by a statistical model for edited text saying that sentences are mostly generated by the language model, except perhaps for a few sentences that might have originated via a different mechanism. We demonstrate the effectiveness of our method using real data and analyze the factors affecting its success. This analysis raises several interesting open challenges whose resolution may improve the method's effectiveness.
The minimax risk in testing the histogram of discrete distributions for uniformity under missing ball alternatives
Jun 13, 2023



We consider the problem of testing the fit of a discrete sample of items from many categories to the uniform distribution over the categories. As a class of alternative hypotheses, we consider the removal of an $\ell_p$ ball of radius $\epsilon$ around the uniform rate sequence for $p \leq 2$. We deliver a sharp characterization of the asymptotic minimax risk when $\epsilon \to 0$ as the number of samples and number of dimensions go to infinity, for testing based on the occurrences' histogram (number of absent categories, singletons, collisions, ...). For example, for $p=1$ and in the limit of a small expected number of samples $n$ compared to the number of categories $N$ (aka "sub-linear" regime), the minimax risk $R^*_\epsilon$ asymptotes to $2 \bar{\Phi}\left(n \epsilon^2/\sqrt{8N}\right) $, with $\bar{\Phi}(x)$ the normal survival function. Empirical studies over a range of problem parameters show that this estimate is accurate in finite samples, and that our test is significantly better than the chisquared test or a test that only uses collisions. Our analysis is based on the asymptotic normality of histogram ordinates, the equivalence between the minimax setting to a Bayesian one, and the reduction of a multi-dimensional optimization problem to a one-dimensional problem.
Gaussian Approximation of Quantization Error for Estimation from Compressed Data
Jan 09, 2020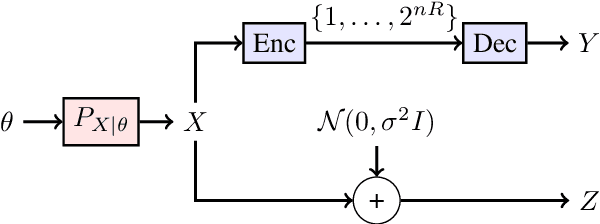


We consider the distributional connection between the lossy compressed representation of a high-dimensional signal $X$ using a random spherical code and the observation of $X$ under an additive white Gaussian noise (AWGN). We show that the Wasserstein distance between a bitrate-$R$ compressed version of $X$ and its observation under an AWGN-channel of signal-to-noise ratio $2^{2R}-1$ is sub-linear in the problem dimension. We utilize this fact to connect the risk of an estimator based on an AWGN-corrupted version of $X$ to the risk attained by the same estimator when fed with its bitrate-$R$ quantized version. We demonstrate the usefulness of this connection by deriving various novel results for inference problems under compression constraints, including noisy source coding and limited-bitrate parameter estimation.
Higher Criticism for Discriminating Word-Frequency Tables and Testing Authorship
Oct 30, 2019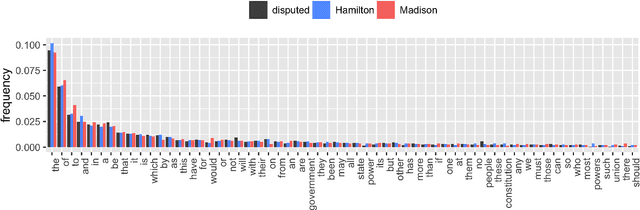
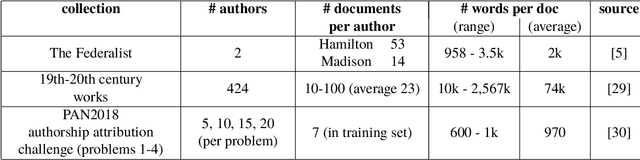


We adapt the Higher Criticism (HC) goodness-of-fit test to detect changes between word frequency tables. We apply the test to authorship attribution, where the goal is to identify the author of a document using other documents whose authorship is known. The method is simple yet performs well without handcrafting and tuning. As an inherent side effect, the HC calculation identifies a subset of discriminating words. In practice, the identified words have low variance across documents belonging to a corpus of homogeneous authorship. We conclude that in testing a new document against the corpus of an author, HC is mostly affected by words characteristic of that author and is relatively unaffected by topic structure.
Mean Estimation from One-Bit Measurements
Jan 10, 2019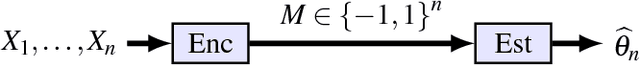
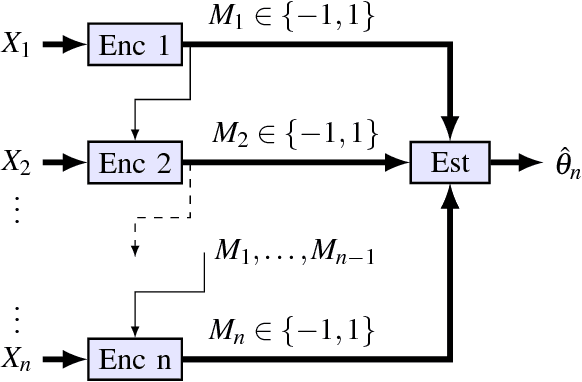

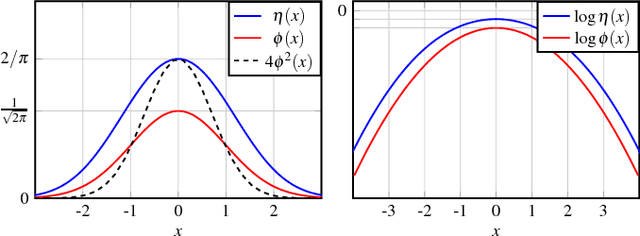
We consider the problem of estimating the mean of a symmetric log-concave distribution under the following constraint: only a single bit per sample from this distribution is available to the estimator. We study the mean squared error (MSE) risk in this estimation as a function of the number of samples, and hence the number of bits, from this distribution. Under an adaptive setting in which each bit is a function of the current sample and the previously observed bits, we show that the optimal relative efficiency compared to the sample mean is the efficiency of the median. For example, in estimating the mean of a normal distribution, a constraint of one bit per sample incurs a penalty of $\pi/2$ in sample size compared to the unconstrained case. We also consider a distributed setting where each one-bit message is only a function of a single sample. We derive lower bounds on the MSE in this setting, and show that the optimal efficiency can only be attained at a finite number of points in the parameter space. Finally, we analyze a distributed setting where the bits are obtained by comparing each sample against a prescribed threshold. Consequently, we consider the threshold density that minimizes the maximal MSE. Our results indicate that estimating the mean from one-bit measurements is equivalent to estimating the sample median from these measurements. In the adaptive case, this estimate can be done with vanishing error for any point in the parameter space. In the distributed case, this estimate can be done with vanishing error only for a finite number of possible values for the unknown mean.