 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCritical biblical studies via word frequency analysis: unveiling text authorship
Oct 24, 2024

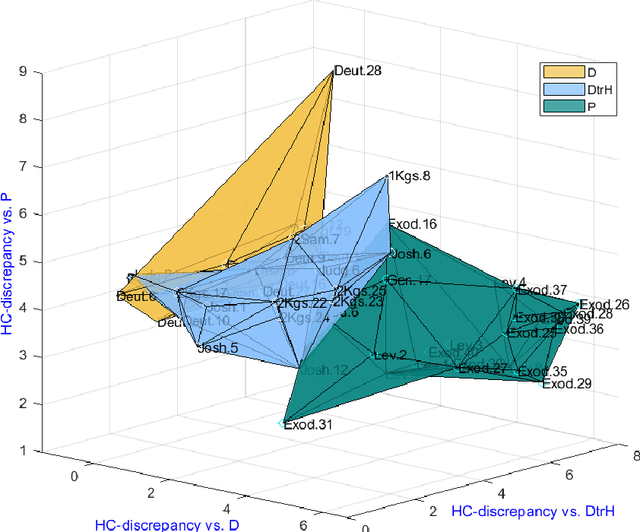
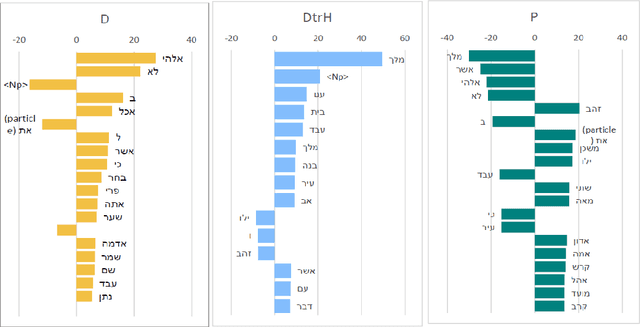
The Bible, a product of an extensive and intricate process of oral-written transmission spanning centuries, obscures the contours of its earlier recensions. Debate rages over determining the existing layers and identifying the date of composition and historical background of the biblical texts. Traditional manual methodologies have grappled with authorship challenges through scrupulous textual criticism, employing linguistic, stylistic, inner-biblical, and historical criteria. Despite recent progress in computer-assisted analysis, many patterns still need to be uncovered in Biblical Texts. In this study, we address the question of authorship of biblical texts by employing statistical analysis to the frequency of words using a method that is particularly sensitive to deviations in frequencies associated with a few words out of potentially many. We aim to differentiate between three distinct authors across numerous chapters spanning the first nine books of the Bible. In particular, we examine 50 chapters labeled according to biblical exegesis considerations into three corpora (D, DtrH, and P). Without prior assumptions about author identity, our approach leverages subtle differences in word frequencies to distinguish among the three corpora and identify author-dependent linguistic properties. Our analysis indicates that the first two authors (D and DtrH) are much more closely related compared to P, a fact that aligns with expert assessments. Additionally, we attain high accuracy in attributing authorship by evaluating the similarity of each chapter with the reference corpora. This study sheds new light on the authorship of biblical texts by providing interpretable, statistically significant evidence that there are different linguistic characteristics of biblical authors and that these differences can be identified.
A Statistical Exploration of Text Partition Into Constituents: The Case of the Priestly Source in the Books of Genesis and Exodus
May 04, 2023We present a pipeline for a statistical textual exploration, offering a stylometry-based explanation and statistical validation of a hypothesized partition of a text. Given a parameterization of the text, our pipeline: (1) detects literary features yielding the optimal overlap between the hypothesized and unsupervised partitions, (2) performs a hypothesis-testing analysis to quantify the statistical significance of the optimal overlap, while conserving implicit correlations between units of text that are more likely to be grouped, and (3) extracts and quantifies the importance of features most responsible for the classification, estimates their statistical stability and cluster-wise abundance. We apply our pipeline to the first two books in the Bible, where one stylistic component stands out in the eyes of biblical scholars, namely, the Priestly component. We identify and explore statistically significant stylistic differences between the Priestly and non-Priestly components.