 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEstimating the Influence of Sequentially Correlated Literary Properties in Textual Classification: A Data-Centric Hypothesis-Testing Approach
Nov 07, 2024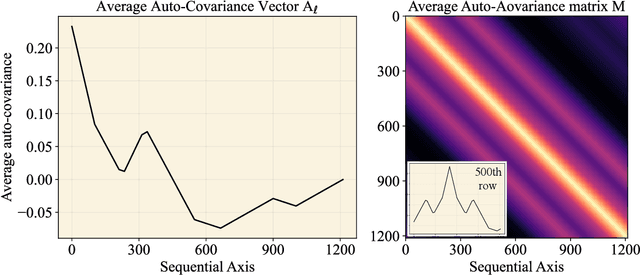



Stylometry aims to distinguish authors by analyzing literary traits assumed to reflect semi-conscious choices distinct from elements like genre or theme. However, these components often overlap, complicating text classification based solely on feature distributions. While some literary properties, such as thematic content, are likely to manifest as correlations between adjacent text units, others, like authorial style, may be independent thereof. We introduce a hypothesis-testing approach to evaluate the influence of sequentially correlated literary properties on text classification, aiming to determine when these correlations drive classification. Using a multivariate binary distribution, our method models sequential correlations between text units as a stochastic process, assessing the likelihood of clustering across varying adjacency scales. This enables us to examine whether classification is dominated by sequentially correlated properties or remains independent. In experiments on a diverse English prose corpus, our analysis integrates traditional and neural embeddings within supervised and unsupervised frameworks. Results demonstrate that our approach effectively identifies when textual classification is not primarily influenced by sequentially correlated literary properties, particularly in cases where texts differ in authorial style or genre rather than by a single author within a similar genre.
A Statistical Exploration of Text Partition Into Constituents: The Case of the Priestly Source in the Books of Genesis and Exodus
May 04, 2023We present a pipeline for a statistical textual exploration, offering a stylometry-based explanation and statistical validation of a hypothesized partition of a text. Given a parameterization of the text, our pipeline: (1) detects literary features yielding the optimal overlap between the hypothesized and unsupervised partitions, (2) performs a hypothesis-testing analysis to quantify the statistical significance of the optimal overlap, while conserving implicit correlations between units of text that are more likely to be grouped, and (3) extracts and quantifies the importance of features most responsible for the classification, estimates their statistical stability and cluster-wise abundance. We apply our pipeline to the first two books in the Bible, where one stylistic component stands out in the eyes of biblical scholars, namely, the Priestly component. We identify and explore statistically significant stylistic differences between the Priestly and non-Priestly components.