 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLog-DenseNet: How to Sparsify a DenseNet
Oct 30, 2017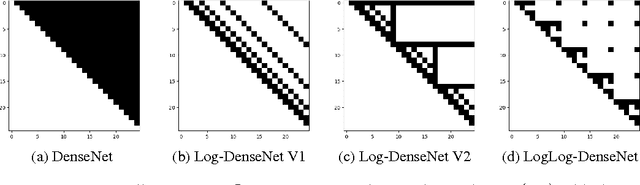
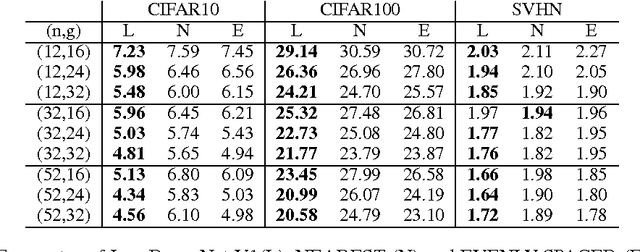
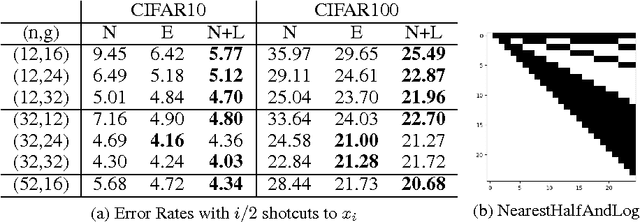
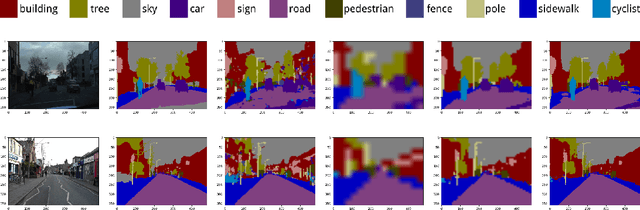
Skip connections are increasingly utilized by deep neural networks to improve accuracy and cost-efficiency. In particular, the recent DenseNet is efficient in computation and parameters, and achieves state-of-the-art predictions by directly connecting each feature layer to all previous ones. However, DenseNet's extreme connectivity pattern may hinder its scalability to high depths, and in applications like fully convolutional networks, full DenseNet connections are prohibitively expensive. This work first experimentally shows that one key advantage of skip connections is to have short distances among feature layers during backpropagation. Specifically, using a fixed number of skip connections, the connection patterns with shorter backpropagation distance among layers have more accurate predictions. Following this insight, we propose a connection template, Log-DenseNet, which, in comparison to DenseNet, only slightly increases the backpropagation distances among layers from 1 to ($1 + \log_2 L$), but uses only $L\log_2 L$ total connections instead of $O(L^2)$. Hence, Log-DenseNets are easier than DenseNets to implement and to scale. We demonstrate the effectiveness of our design principle by showing better performance than DenseNets on tabula rasa semantic segmentation, and competitive results on visual recognition.
Ignoring Distractors in the Absence of Labels: Optimal Linear Projection to Remove False Positives During Anomaly Detection
Sep 13, 2017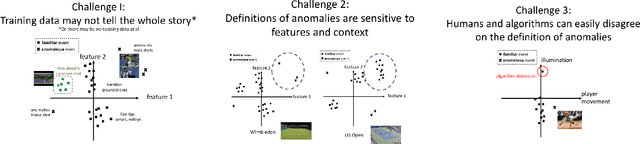
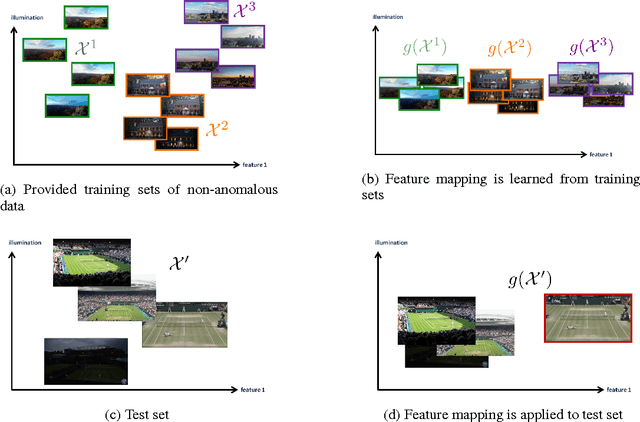
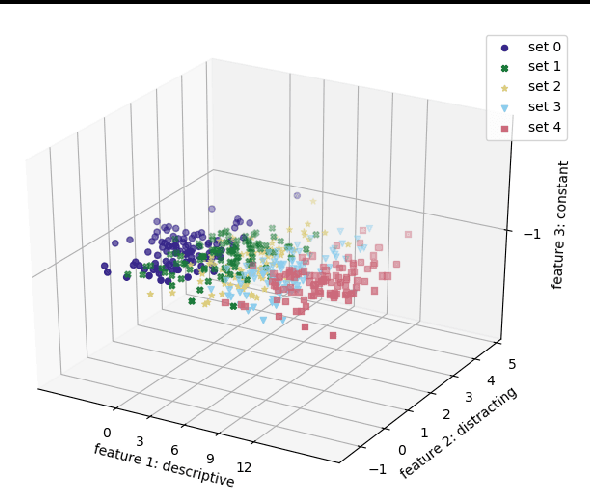

In the anomaly detection setting, the native feature embedding can be a crucial source of bias. We present a technique, Feature Omission using Context in Unsupervised Settings (FOCUS) to learn a feature mapping that is invariant to changes exemplified in training sets while retaining as much descriptive power as possible. While this method could apply to many unsupervised settings, we focus on applications in anomaly detection, where little task-labeled data is available. Our algorithm requires only non-anomalous sets of data, and does not require that the contexts in the training sets match the context of the test set. By maximizing within-set variance and minimizing between-set variance, we are able to identify and remove distracting features while retaining fidelity to the descriptiveness needed at test time. In the linear case, our formulation reduces to a generalized eigenvalue problem that can be solved quickly and applied to test sets outside the context of the training sets. This technique allows us to align technical definitions of anomaly detection with human definitions through appropriate mappings of the feature space. We demonstrate that this method is able to remove uninformative parts of the feature space for the anomaly detection setting.
A Discriminative Framework for Anomaly Detection in Large Videos
Sep 28, 2016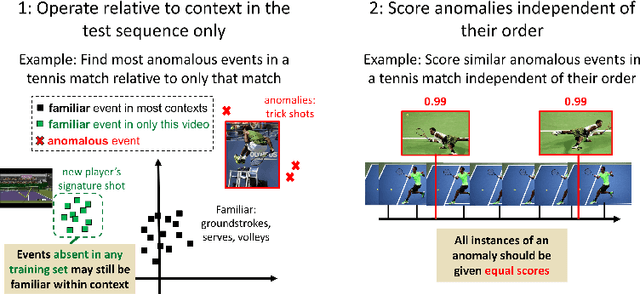
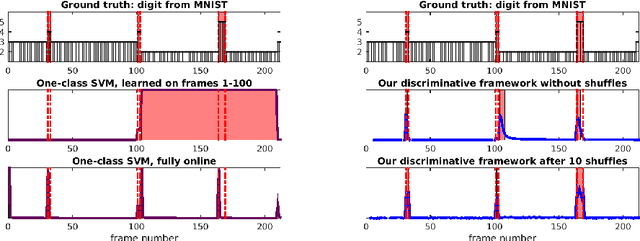
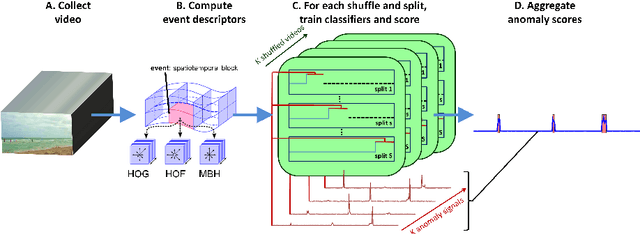
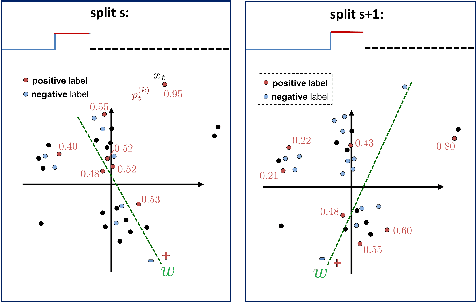
We address an anomaly detection setting in which training sequences are unavailable and anomalies are scored independently of temporal ordering. Current algorithms in anomaly detection are based on the classical density estimation approach of learning high-dimensional models and finding low-probability events. These algorithms are sensitive to the order in which anomalies appear and require either training data or early context assumptions that do not hold for longer, more complex videos. By defining anomalies as examples that can be distinguished from other examples in the same video, our definition inspires a shift in approaches from classical density estimation to simple discriminative learning. Our contributions include a novel framework for anomaly detection that is (1) independent of temporal ordering of anomalies, and (2) unsupervised, requiring no separate training sequences. We show that our algorithm can achieve state-of-the-art results even when we adjust the setting by removing training sequences from standard datasets.