 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Discriminative Framework for Anomaly Detection in Large Videos
Paper and Code
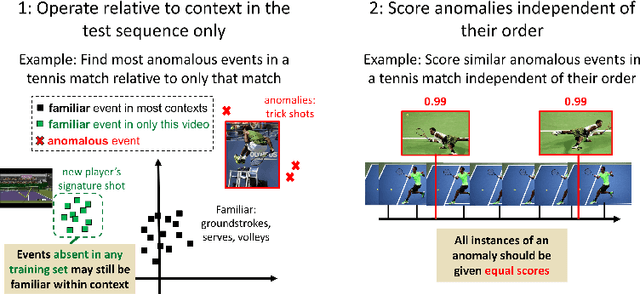
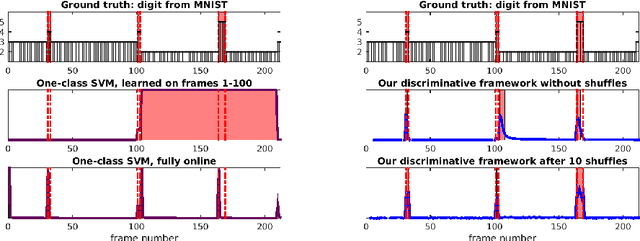
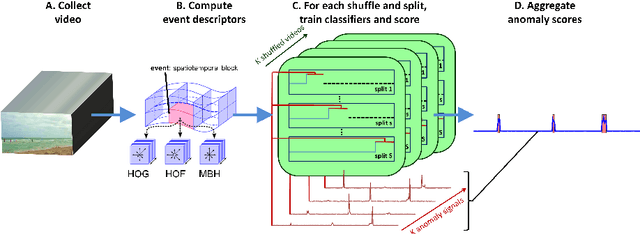
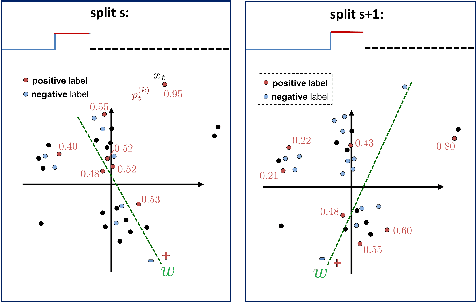
We address an anomaly detection setting in which training sequences are unavailable and anomalies are scored independently of temporal ordering. Current algorithms in anomaly detection are based on the classical density estimation approach of learning high-dimensional models and finding low-probability events. These algorithms are sensitive to the order in which anomalies appear and require either training data or early context assumptions that do not hold for longer, more complex videos. By defining anomalies as examples that can be distinguished from other examples in the same video, our definition inspires a shift in approaches from classical density estimation to simple discriminative learning. Our contributions include a novel framework for anomaly detection that is (1) independent of temporal ordering of anomalies, and (2) unsupervised, requiring no separate training sequences. We show that our algorithm can achieve state-of-the-art results even when we adjust the setting by removing training sequences from standard datasets.