 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTOKEN is a MASK: Few-shot Named Entity Recognition with Pre-trained Language Models
Jun 15, 2022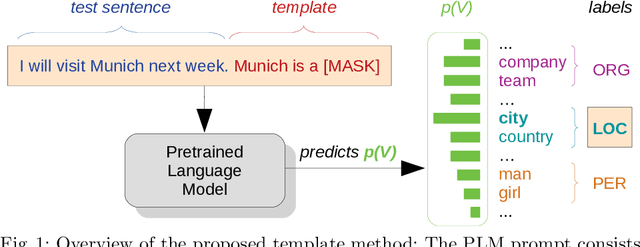



Transferring knowledge from one domain to another is of practical importance for many tasks in natural language processing, especially when the amount of available data in the target domain is limited. In this work, we propose a novel few-shot approach to domain adaptation in the context of Named Entity Recognition (NER). We propose a two-step approach consisting of a variable base module and a template module that leverages the knowledge captured in pre-trained language models with the help of simple descriptive patterns. Our approach is simple yet versatile and can be applied in few-shot and zero-shot settings. Evaluating our lightweight approach across a number of different datasets shows that it can boost the performance of state-of-the-art baselines by 2-5% F1-score.
Preventing Author Profiling through Zero-Shot Multilingual Back-Translation
Sep 19, 2021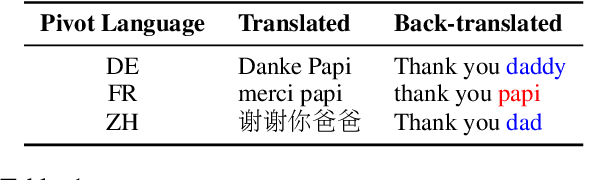

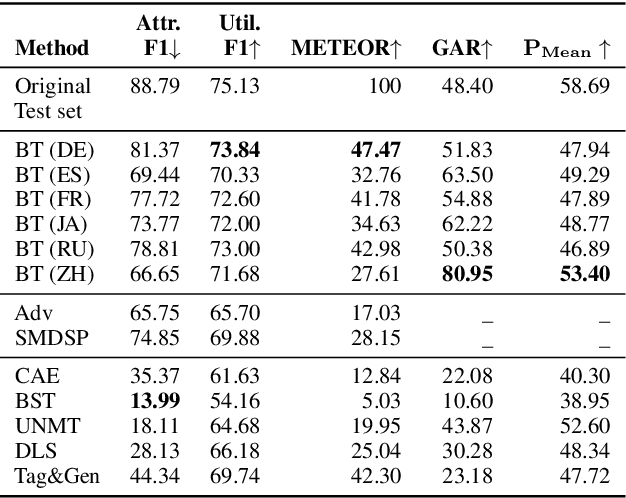
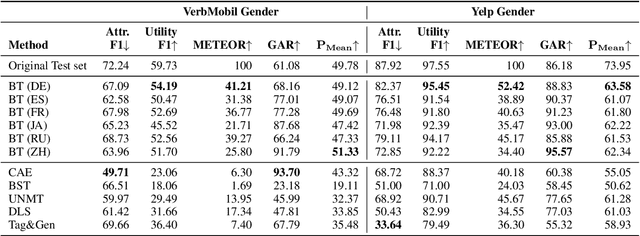
Documents as short as a single sentence may inadvertently reveal sensitive information about their authors, including e.g. their gender or ethnicity. Style transfer is an effective way of transforming texts in order to remove any information that enables author profiling. However, for a number of current state-of-the-art approaches the improved privacy is accompanied by an undesirable drop in the down-stream utility of the transformed data. In this paper, we propose a simple, zero-shot way to effectively lower the risk of author profiling through multilingual back-translation using off-the-shelf translation models. We compare our models with five representative text style transfer models on three datasets across different domains. Results from both an automatic and a human evaluation show that our approach achieves the best overall performance while requiring no training data. We are able to lower the adversarial prediction of gender and race by up to $22\%$ while retaining $95\%$ of the original utility on downstream tasks.
SuperCoder: Program Learning Under Noisy Conditions From Superposition of States
Dec 07, 2020
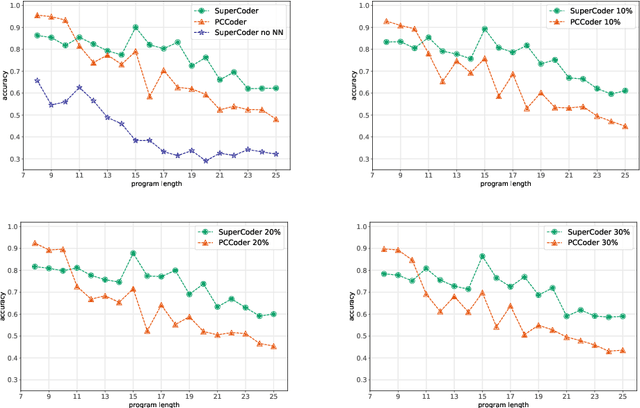
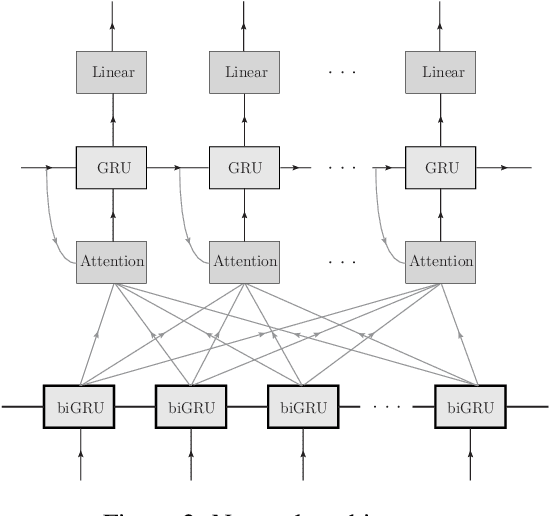
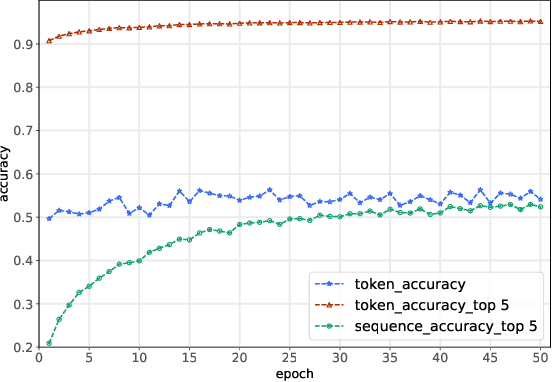
We propose a new method of program learning in a Domain Specific Language (DSL) which is based on gradient descent with no direct search. The first component of our method is a probabilistic representation of the DSL variables. At each timestep in the program sequence, different DSL functions are applied on the DSL variables with a certain probability, leading to different possible outcomes. Rather than handling all these outputs separately, whose number grows exponentially with each timestep, we collect them into a superposition of variables which captures the information in a single, but fuzzy, state. This state is to be contrasted at the final timestep with the ground-truth output, through a loss function. The second component of our method is an attention-based recurrent neural network, which provides an appropriate initialization point for the gradient descent that optimizes the probabilistic representation. The method we have developed surpasses the state-of-the-art for synthesising long programs and is able to learn programs under noise.
Privacy Guarantees for De-identifying Text Transformations
Aug 07, 2020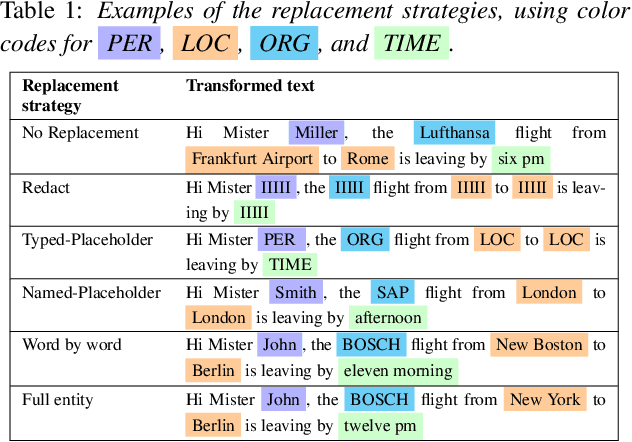



Machine Learning approaches to Natural Language Processing tasks benefit from a comprehensive collection of real-life user data. At the same time, there is a clear need for protecting the privacy of the users whose data is collected and processed. For text collections, such as, e.g., transcripts of voice interactions or patient records, replacing sensitive parts with benign alternatives can provide de-identification. However, how much privacy is actually guaranteed by such text transformations, and are the resulting texts still useful for machine learning? In this paper, we derive formal privacy guarantees for general text transformation-based de-identification methods on the basis of Differential Privacy. We also measure the effect that different ways of masking private information in dialog transcripts have on a subsequent machine learning task. To this end, we formulate different masking strategies and compare their privacy-utility trade-offs. In particular, we compare a simple redact approach with more sophisticated word-by-word replacement using deep learning models on multiple natural language understanding tasks like named entity recognition, intent detection, and dialog act classification. We find that only word-by-word replacement is robust against performance drops in various tasks.
Robust Differentially Private Training of Deep Neural Networks
Jun 19, 2020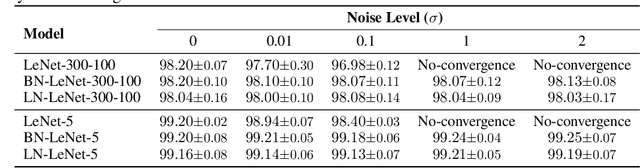
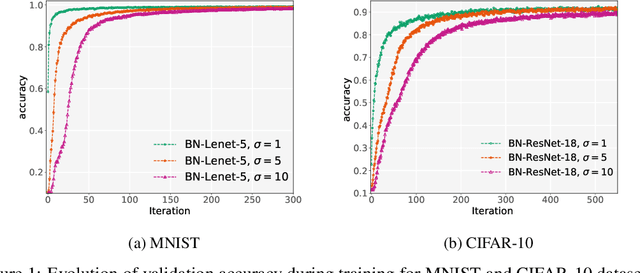
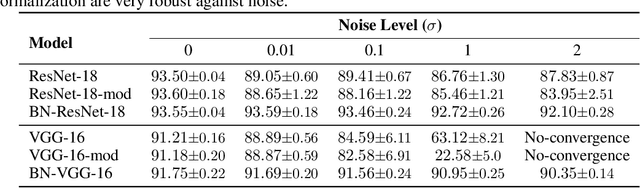
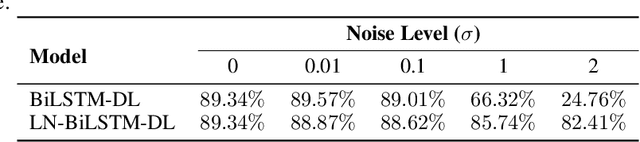
Differentially private stochastic gradient descent (DPSGD) is a variation of stochastic gradient descent based on the Differential Privacy (DP) paradigm which can mitigate privacy threats arising from the presence of sensitive information in training data. One major drawback of training deep neural networks with DPSGD is a reduction in the model's accuracy. In this paper, we propose an alternative method for preserving data privacy based on introducing noise through learnable probability distributions, which leads to a significant improvement in the utility of the resulting private models. We also demonstrate that normalization layers have a large beneficial impact on the performance of deep neural networks with noisy parameters. In particular, we show that contrary to general belief, a large amount of random noise can be added to the weights of neural networks without harming the performance, once the networks are augmented with normalization layers. We hypothesize that this robustness is a consequence of the scale invariance property of normalization operators. Building on these observations, we propose a new algorithmic technique for training deep neural networks under very low privacy budgets by sampling weights from Gaussian distributions and utilizing batch or layer normalization techniques to prevent performance degradation. Our method outperforms previous approaches, including DPSGD, by a substantial margin on a comprehensive set of experiments on Computer Vision and Natural Language Processing tasks. In particular, we obtain a 20 percent accuracy improvement over DPSGD on the MNIST and CIFAR10 datasets with DP-privacy budgets of $\varepsilon = 0.05$ and $\varepsilon = 2.0$, respectively. Our code is available online: https://github.com/uds-lsv/SIDP.