 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSuperCoder: Program Learning Under Noisy Conditions From Superposition of States
Paper and Code

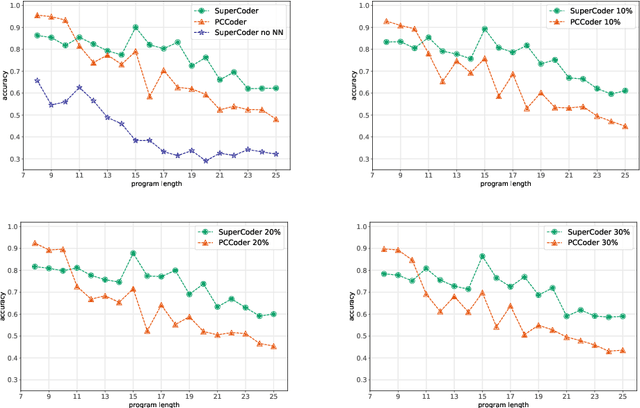
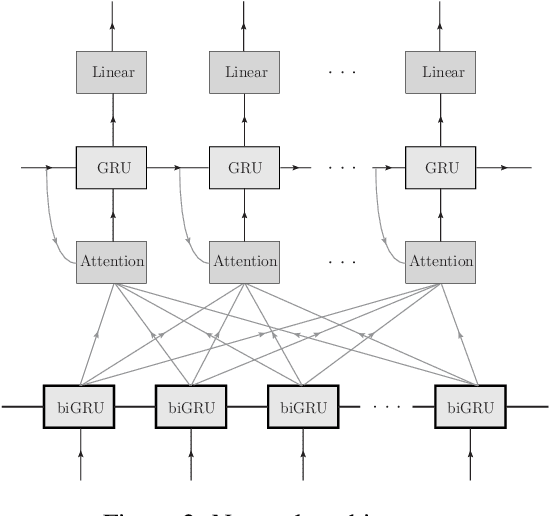
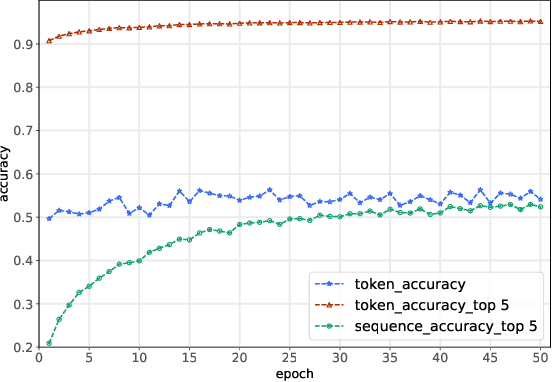
We propose a new method of program learning in a Domain Specific Language (DSL) which is based on gradient descent with no direct search. The first component of our method is a probabilistic representation of the DSL variables. At each timestep in the program sequence, different DSL functions are applied on the DSL variables with a certain probability, leading to different possible outcomes. Rather than handling all these outputs separately, whose number grows exponentially with each timestep, we collect them into a superposition of variables which captures the information in a single, but fuzzy, state. This state is to be contrasted at the final timestep with the ground-truth output, through a loss function. The second component of our method is an attention-based recurrent neural network, which provides an appropriate initialization point for the gradient descent that optimizes the probabilistic representation. The method we have developed surpasses the state-of-the-art for synthesising long programs and is able to learn programs under noise.