 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeC3PO: Learning to Achieve Arbitrary Goals via Massively Entropic Pretraining
Nov 07, 2022



Given a particular embodiment, we propose a novel method (C3PO) that learns policies able to achieve any arbitrary position and pose. Such a policy would allow for easier control, and would be re-useable as a key building block for downstream tasks. The method is two-fold: First, we introduce a novel exploration algorithm that optimizes for uniform coverage, is able to discover a set of achievable states, and investigates its abilities in attaining both high coverage, and hard-to-discover states; Second, we leverage this set of achievable states as training data for a universal goal-achievement policy, a goal-based SAC variant. We demonstrate the trained policy's performance in achieving a large number of novel states. Finally, we showcase the influence of massive unsupervised training of a goal-achievement policy with state-of-the-art pose-based control of the Hopper, Walker, Halfcheetah, Humanoid and Ant embodiments.
Lazy-MDPs: Towards Interpretable Reinforcement Learning by Learning When to Act
Mar 16, 2022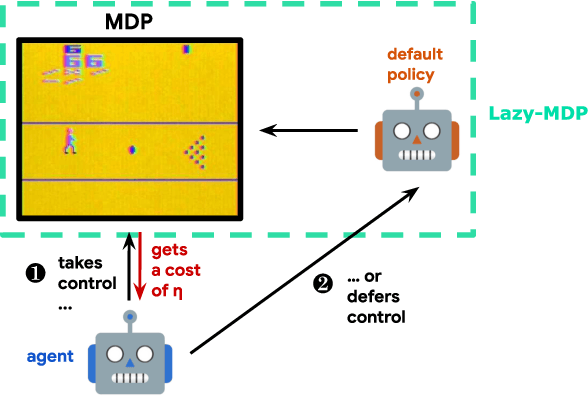
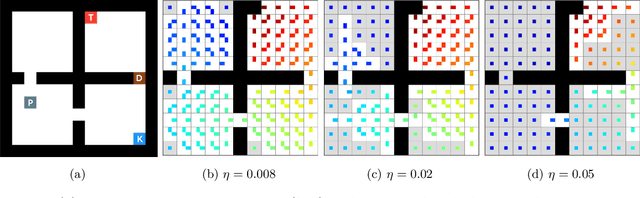
Traditionally, Reinforcement Learning (RL) aims at deciding how to act optimally for an artificial agent. We argue that deciding when to act is equally important. As humans, we drift from default, instinctive or memorized behaviors to focused, thought-out behaviors when required by the situation. To enhance RL agents with this aptitude, we propose to augment the standard Markov Decision Process and make a new mode of action available: being lazy, which defers decision-making to a default policy. In addition, we penalize non-lazy actions in order to encourage minimal effort and have agents focus on critical decisions only. We name the resulting formalism lazy-MDPs. We study the theoretical properties of lazy-MDPs, expressing value functions and characterizing optimal solutions. Then we empirically demonstrate that policies learned in lazy-MDPs generally come with a form of interpretability: by construction, they show us the states where the agent takes control over the default policy. We deem those states and corresponding actions important since they explain the difference in performance between the default and the new, lazy policy. With suboptimal policies as default (pretrained or random), we observe that agents are able to get competitive performance in Atari games while only taking control in a limited subset of states.
* AAMAS 2022 (14 pages extended version, added Sec. 7.4 and appendix K)
Foolproof Cooperative Learning
Jun 24, 2019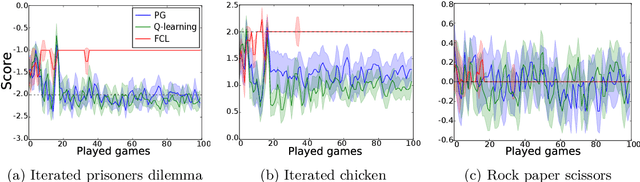
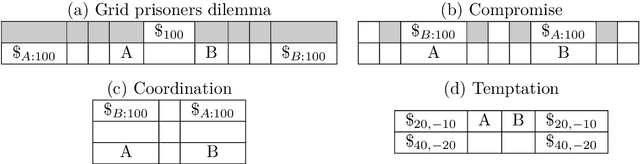
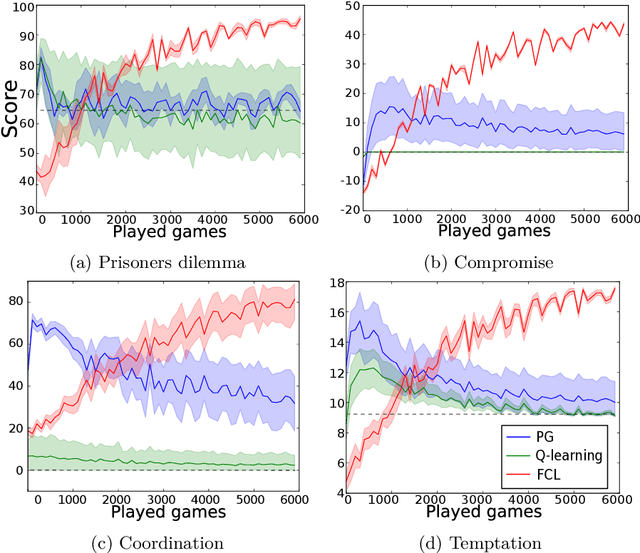
This paper extends the notion of equilibrium in game theory to learning algorithms in repeated stochastic games. We define a learning equilibrium as an algorithm used by a population of players, such that no player can individually use an alternative algorithm and increase its asymptotic score. We introduce Foolproof Cooperative Learning (FCL), an algorithm that converges to a Tit-for-Tat behavior. It allows cooperative strategies when played against itself while being not exploitable by selfish players. We prove that in repeated symmetric games, this algorithm is a learning equilibrium. We illustrate the behavior of FCL on symmetric matrix and grid games, and its robustness to selfish learners.
Cognitive Architecture for Mutual Modelling
Feb 22, 2016
In social robotics, robots needs to be able to be understood by humans. Especially in collaborative tasks where they have to share mutual knowledge. For instance, in an educative scenario, learners share their knowledge and they must adapt their behaviour in order to make sure they are understood by others. Learners display behaviours in order to show their understanding and teachers adapt in order to make sure that the learners' knowledge is the required one. This ability requires a model of their own mental states perceived by others: \textit{"has the human understood that I(robot) need this object for the task or should I explain it once again ?"} In this paper, we discuss the importance of a cognitive architecture enabling second-order Mutual Modelling for Human-Robot Interaction in educative contexts.