 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Paradigm Discovery Problem
May 04, 2020
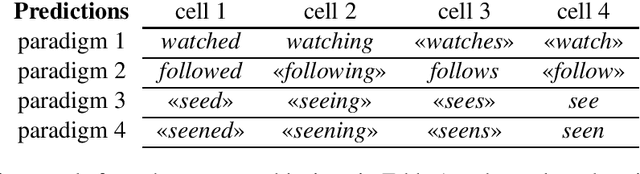
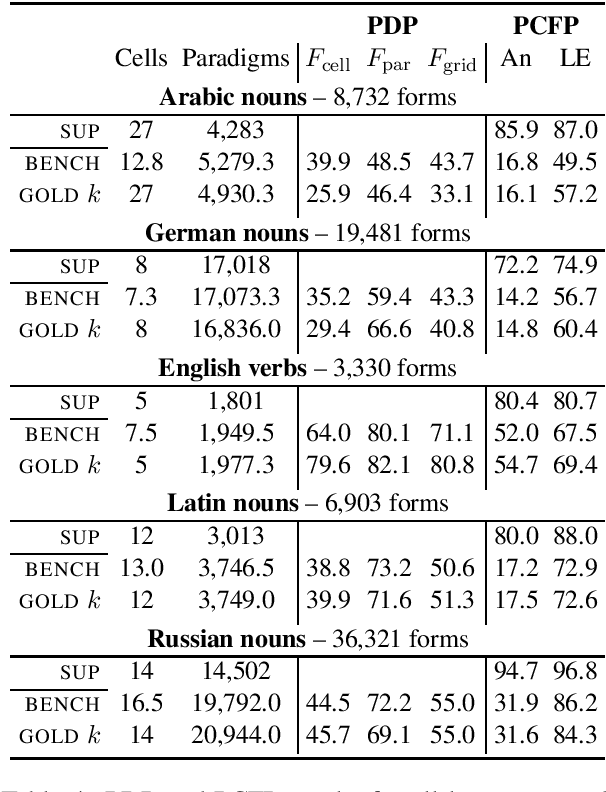
This work treats the paradigm discovery problem (PDP), the task of learning an inflectional morphological system from unannotated sentences. We formalize the PDP and develop evaluation metrics for judging systems. Using currently available resources, we construct datasets for the task. We also devise a heuristic benchmark for the PDP and report empirical results on five diverse languages. Our benchmark system first makes use of word embeddings and string similarity to cluster forms by cell and by paradigm. Then, we bootstrap a neural transducer on top of the clustered data to predict words to realize the empty paradigm slots. An error analysis of our system suggests clustering by cell across different inflection classes is the most pressing challenge for future work. Our code and data are available for public use.
Low Resourced Machine Translation via Morpho-syntactic Modeling: The Case of Dialectal Arabic
Dec 18, 2017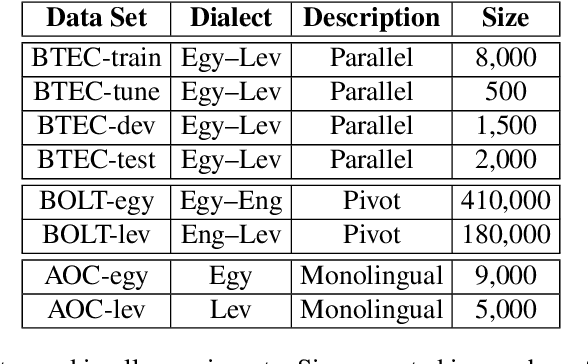
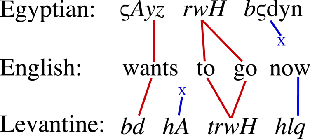
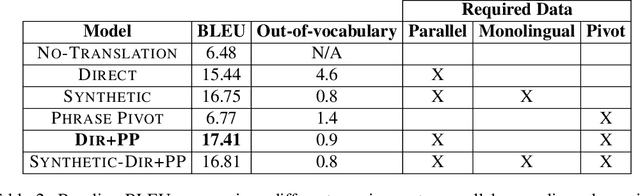

We present the second ever evaluated Arabic dialect-to-dialect machine translation effort, and the first to leverage external resources beyond a small parallel corpus. The subject has not previously received serious attention due to lack of naturally occurring parallel data; yet its importance is evidenced by dialectal Arabic's wide usage and breadth of inter-dialect variation, comparable to that of Romance languages. Our results suggest that modeling morphology and syntax significantly improves dialect-to-dialect translation, though optimizing such data-sparse models requires consideration of the linguistic differences between dialects and the nature of available data and resources. On a single-reference blind test set where untranslated input scores 6.5 BLEU and a model trained only on parallel data reaches 14.6, pivot techniques and morphosyntactic modeling significantly improve performance to 17.5.