 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Learning for Surgical Vision in Appendicitis Classification: Results of the FedSurg EndoVis 2024 Challenge
Oct 06, 2025Purpose: The FedSurg challenge was designed to benchmark the state of the art in federated learning for surgical video classification. Its goal was to assess how well current methods generalize to unseen clinical centers and adapt through local fine-tuning while enabling collaborative model development without sharing patient data. Methods: Participants developed strategies to classify inflammation stages in appendicitis using a preliminary version of the multi-center Appendix300 video dataset. The challenge evaluated two tasks: generalization to an unseen center and center-specific adaptation after fine-tuning. Submitted approaches included foundation models with linear probing, metric learning with triplet loss, and various FL aggregation schemes (FedAvg, FedMedian, FedSAM). Performance was assessed using F1-score and Expected Cost, with ranking robustness evaluated via bootstrapping and statistical testing. Results: In the generalization task, performance across centers was limited. In the adaptation task, all teams improved after fine-tuning, though ranking stability was low. The ViViT-based submission achieved the strongest overall performance. The challenge highlighted limitations in generalization, sensitivity to class imbalance, and difficulties in hyperparameter tuning in decentralized training, while spatiotemporal modeling and context-aware preprocessing emerged as promising strategies. Conclusion: The FedSurg Challenge establishes the first benchmark for evaluating FL strategies in surgical video classification. Findings highlight the trade-off between local personalization and global robustness, and underscore the importance of architecture choice, preprocessing, and loss design. This benchmarking offers a reference point for future development of imbalance-aware, adaptive, and robust FL methods in clinical surgical AI.
Federated EndoViT: Pretraining Vision Transformers via Federated Learning on Endoscopic Image Collections
Apr 23, 2025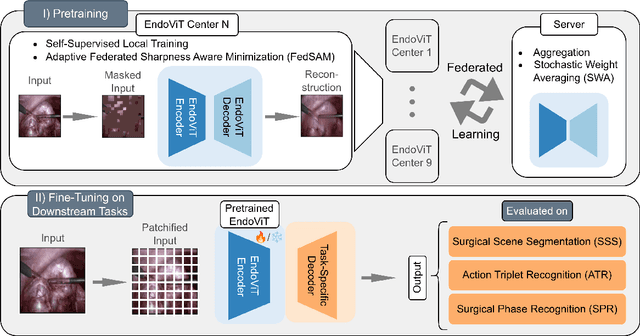
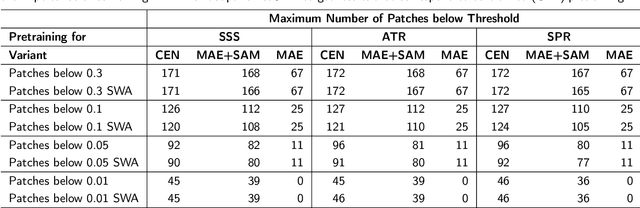
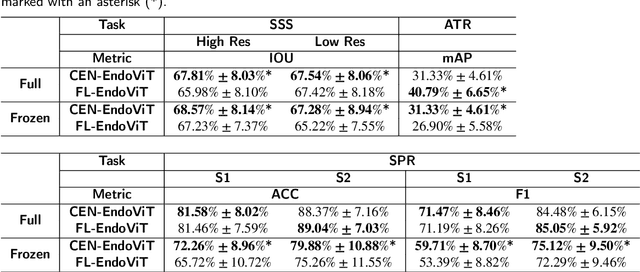
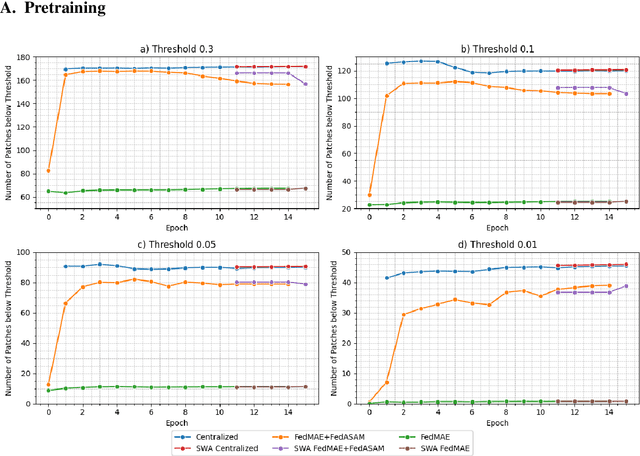
Purpose: In this study, we investigate the training of foundation models using federated learning to address data-sharing limitations and enable collaborative model training without data transfer for minimally invasive surgery. Methods: Inspired by the EndoViT study, we adapt the Masked Autoencoder for federated learning, enhancing it with adaptive Sharpness-Aware Minimization (FedSAM) and Stochastic Weight Averaging (SWA). Our model is pretrained on the Endo700k dataset collection and later fine-tuned and evaluated for tasks such as Semantic Segmentation, Action Triplet Recognition, and Surgical Phase Recognition. Results: Our findings demonstrate that integrating adaptive FedSAM into the federated MAE approach improves pretraining, leading to a reduction in reconstruction loss per patch. The application of FL-EndoViT in surgical downstream tasks results in performance comparable to CEN-EndoViT. Furthermore, FL-EndoViT exhibits advantages over CEN-EndoViT in surgical scene segmentation when data is limited and in action triplet recognition when large datasets are used. Conclusion: These findings highlight the potential of federated learning for privacy-preserving training of surgical foundation models, offering a robust and generalizable solution for surgical data science. Effective collaboration requires adapting federated learning methods, such as the integration of FedSAM, which can accommodate the inherent data heterogeneity across institutions. In future, exploring FL in video-based models may enhance these capabilities by incorporating spatiotemporal dynamics crucial for real-world surgical environments.
One model to use them all: Training a segmentation model with complementary datasets
Feb 29, 2024Understanding a surgical scene is crucial for computer-assisted surgery systems to provide any intelligent assistance functionality. One way of achieving this scene understanding is via scene segmentation, where every pixel of a frame is classified and therefore identifies the visible structures and tissues. Progress on fully segmenting surgical scenes has been made using machine learning. However, such models require large amounts of annotated training data, containing examples of all relevant object classes. Such fully annotated datasets are hard to create, as every pixel in a frame needs to be annotated by medical experts and, therefore, are rarely available. In this work, we propose a method to combine multiple partially annotated datasets, which provide complementary annotations, into one model, enabling better scene segmentation and the use of multiple readily available datasets. Our method aims to combine available data with complementary labels by leveraging mutual exclusive properties to maximize information. Specifically, we propose to use positive annotations of other classes as negative samples and to exclude background pixels of binary annotations, as we cannot tell if they contain a class not annotated but predicted by the model. We evaluate our method by training a DeepLabV3 on the publicly available Dresden Surgical Anatomy Dataset, which provides multiple subsets of binary segmented anatomical structures. Our approach successfully combines 6 classes into one model, increasing the overall Dice Score by 4.4% compared to an ensemble of models trained on the classes individually. By including information on multiple classes, we were able to reduce confusion between stomach and colon by 24%. Our results demonstrate the feasibility of training a model on multiple datasets. This paves the way for future work further alleviating the need for one large, fully segmented datasets.