 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHCM: Hardware-Aware Complexity Metric for Neural Network Architectures
Apr 26, 2020

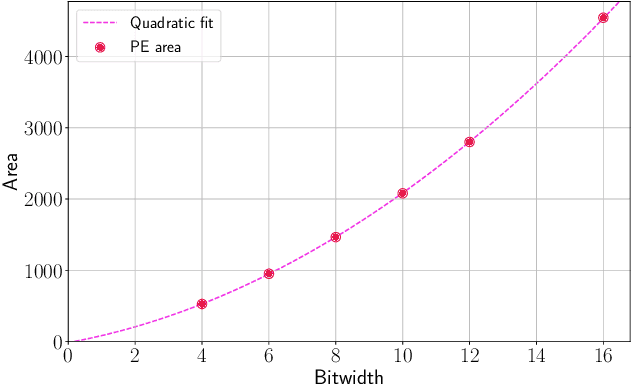
Convolutional Neural Networks (CNNs) have become common in many fields including computer vision, speech recognition, and natural language processing. Although CNN hardware accelerators are already included as part of many SoC architectures, the task of achieving high accuracy on resource-restricted devices is still considered challenging, mainly due to the vast number of design parameters that need to be balanced to achieve an efficient solution. Quantization techniques, when applied to the network parameters, lead to a reduction of power and area and may also change the ratio between communication and computation. As a result, some algorithmic solutions may suffer from lack of memory bandwidth or computational resources and fail to achieve the expected performance due to hardware constraints. Thus, the system designer and the micro-architect need to understand at early development stages the impact of their high-level decisions (e.g., the architecture of the CNN and the amount of bits used to represent its parameters) on the final product (e.g., the expected power saving, area, and accuracy). Unfortunately, existing tools fall short of supporting such decisions. This paper introduces a hardware-aware complexity metric that aims to assist the system designer of the neural network architectures, through the entire project lifetime (especially at its early stages) by predicting the impact of architectural and micro-architectural decisions on the final product. We demonstrate how the proposed metric can help evaluate different design alternatives of neural network models on resource-restricted devices such as real-time embedded systems, and to avoid making design mistakes at early stages.
Feature Map Transform Coding for Energy-Efficient CNN Inference
May 26, 2019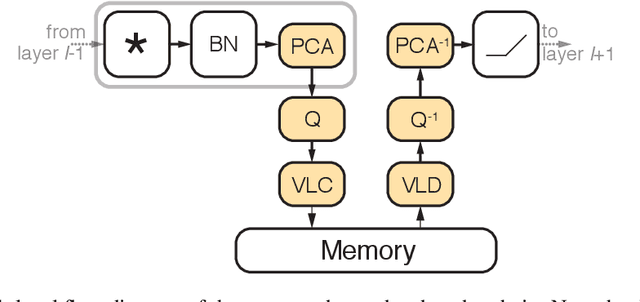

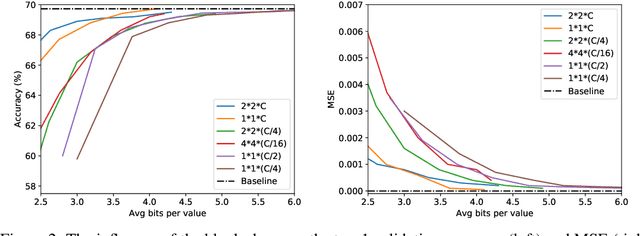
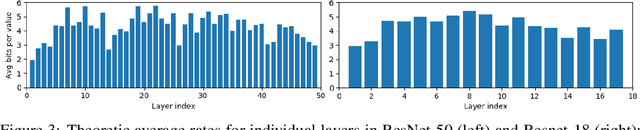
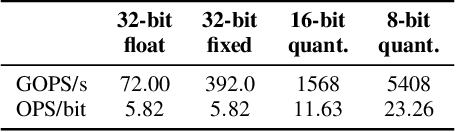
Convolutional neural networks (CNNs) achieve state-of-the-art accuracy in a variety of tasks in computer vision and beyond. One of the major obstacles hindering the ubiquitous use of CNNs for inference on low-power edge devices is their relatively high computational complexity and memory bandwidth requirements. The latter often dominates the energy footprint on modern hardware. In this paper, we introduce a lossy transform coding approach, inspired by image and video compression, designed to reduce the memory bandwidth due to the storage of intermediate activation calculation results. Our method exploits the high correlations between feature maps and adjacent pixels and allows to halve the data transfer volumes to the main memory without re-training. We analyze the performance of our approach on a variety of CNN architectures and demonstrated FPGA implementation of ResNet18 with our approach results in reduction of around 40% in the memory energy footprint compared to quantized network with negligible impact on accuracy. A reference implementation is available at https://github.com/CompressTeam/TransformCodingInference