 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigating the Robustness of Retrieval-Augmented Generation at the Query Level
Jul 09, 2025Large language models (LLMs) are very costly and inefficient to update with new information. To address this limitation, retrieval-augmented generation (RAG) has been proposed as a solution that dynamically incorporates external knowledge during inference, improving factual consistency and reducing hallucinations. Despite its promise, RAG systems face practical challenges-most notably, a strong dependence on the quality of the input query for accurate retrieval. In this paper, we investigate the sensitivity of different components in the RAG pipeline to various types of query perturbations. Our analysis reveals that the performance of commonly used retrievers can degrade significantly even under minor query variations. We study each module in isolation as well as their combined effect in an end-to-end question answering setting, using both general-domain and domain-specific datasets. Additionally, we propose an evaluation framework to systematically assess the query-level robustness of RAG pipelines and offer actionable recommendations for practitioners based on the results of more than 1092 experiments we performed.
Extracting Unlearned Information from LLMs with Activation Steering
Nov 04, 2024
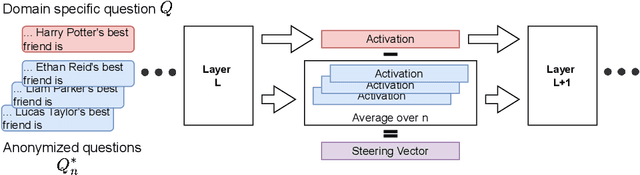


An unintended consequence of the vast pretraining of Large Language Models (LLMs) is the verbatim memorization of fragments of their training data, which may contain sensitive or copyrighted information. In recent years, unlearning has emerged as a solution to effectively remove sensitive knowledge from models after training. Yet, recent work has shown that supposedly deleted information can still be extracted by malicious actors through various attacks. Still, current attacks retrieve sets of possible candidate generations and are unable to pinpoint the output that contains the actual target information. We propose activation steering as a method for exact information retrieval from unlearned LLMs. We introduce a novel approach to generating steering vectors, named Anonymized Activation Steering. Additionally, we develop a simple word frequency method to pinpoint the correct answer among a set of candidates when retrieving unlearned information. Our evaluation across multiple unlearning techniques and datasets demonstrates that activation steering successfully recovers general knowledge (e.g., widely known fictional characters) while revealing limitations in retrieving specific information (e.g., details about non-public individuals). Overall, our results demonstrate that exact information retrieval from unlearned models is possible, highlighting a severe vulnerability of current unlearning techniques.
Intriguing Properties of Input-dependent Randomized Smoothing
Oct 11, 2021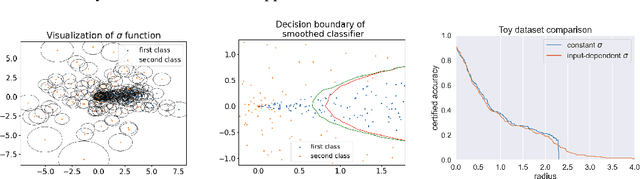
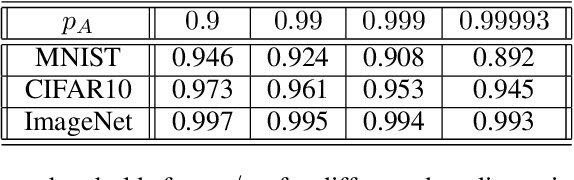
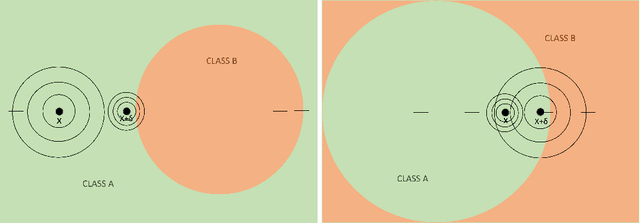

Randomized smoothing is currently considered the state-of-the-art method to obtain certifiably robust classifiers. Despite its remarkable performance, the method is associated with various serious problems such as ``certified accuracy waterfalls'', certification vs. accuracy trade-off, or even fairness issues. Input-dependent smoothing approaches have been proposed to overcome these flaws. However, we demonstrate that these methods lack formal guarantees and so the resulting certificates are not justified. We show that the input-dependent smoothing, in general, suffers from the curse of dimensionality, forcing the variance function to have low semi-elasticity. On the other hand, we provide a theoretical and practical framework that enables the usage of input-dependent smoothing even in the presence of the curse of dimensionality, under strict restrictions. We present one concrete design of the smoothing variance and test it on CIFAR10 and MNIST. Our design solves some of the problems of classical smoothing and is formally underlined, yet further improvement of the design is still necessary.