 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtracting Unlearned Information from LLMs with Activation Steering
Paper and Code
Nov 04, 2024
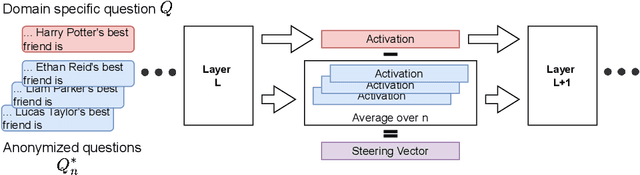


An unintended consequence of the vast pretraining of Large Language Models (LLMs) is the verbatim memorization of fragments of their training data, which may contain sensitive or copyrighted information. In recent years, unlearning has emerged as a solution to effectively remove sensitive knowledge from models after training. Yet, recent work has shown that supposedly deleted information can still be extracted by malicious actors through various attacks. Still, current attacks retrieve sets of possible candidate generations and are unable to pinpoint the output that contains the actual target information. We propose activation steering as a method for exact information retrieval from unlearned LLMs. We introduce a novel approach to generating steering vectors, named Anonymized Activation Steering. Additionally, we develop a simple word frequency method to pinpoint the correct answer among a set of candidates when retrieving unlearned information. Our evaluation across multiple unlearning techniques and datasets demonstrates that activation steering successfully recovers general knowledge (e.g., widely known fictional characters) while revealing limitations in retrieving specific information (e.g., details about non-public individuals). Overall, our results demonstrate that exact information retrieval from unlearned models is possible, highlighting a severe vulnerability of current unlearning techniques.