 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMusic Genre Classification using Large Language Models
Oct 10, 2024


This paper exploits the zero-shot capabilities of pre-trained large language models (LLMs) for music genre classification. The proposed approach splits audio signals into 20 ms chunks and processes them through convolutional feature encoders, a transformer encoder, and additional layers for coding audio units and generating feature vectors. The extracted feature vectors are used to train a classification head. During inference, predictions on individual chunks are aggregated for a final genre classification. We conducted a comprehensive comparison of LLMs, including WavLM, HuBERT, and wav2vec 2.0, with traditional deep learning architectures like 1D and 2D convolutional neural networks (CNNs) and the audio spectrogram transformer (AST). Our findings demonstrate the superior performance of the AST model, achieving an overall accuracy of 85.5%, surpassing all other models evaluated. These results highlight the potential of LLMs and transformer-based architectures for advancing music information retrieval tasks, even in zero-shot scenarios.
Alleviating Catastrophic Forgetting in Facial Expression Recognition with Emotion-Centered Models
Apr 18, 2024Facial expression recognition is a pivotal component in machine learning, facilitating various applications. However, convolutional neural networks (CNNs) are often plagued by catastrophic forgetting, impeding their adaptability. The proposed method, emotion-centered generative replay (ECgr), tackles this challenge by integrating synthetic images from generative adversarial networks. Moreover, ECgr incorporates a quality assurance algorithm to ensure the fidelity of generated images. This dual approach enables CNNs to retain past knowledge while learning new tasks, enhancing their performance in emotion recognition. The experimental results on four diverse facial expression datasets demonstrate that incorporating images generated by our pseudo-rehearsal method enhances training on the targeted dataset and the source dataset while making the CNN retain previously learned knowledge.
Concept Drift Adaptation in Text Stream Mining Settings: A Comprehensive Review
Dec 05, 2023Due to the advent and increase in the popularity of the Internet, people have been producing and disseminating textual data in several ways, such as reviews, social media posts, and news articles. As a result, numerous researchers have been working on discovering patterns in textual data, especially because social media posts function as social sensors, indicating peoples' opinions, interests, etc. However, most tasks regarding natural language processing are addressed using traditional machine learning methods and static datasets. This setting can lead to several problems, such as an outdated dataset, which may not correspond to reality, and an outdated model, which has its performance degrading over time. Concept drift is another aspect that emphasizes these issues, which corresponds to data distribution and pattern changes. In a text stream scenario, it is even more challenging due to its characteristics, such as the high speed and data arriving sequentially. In addition, models for this type of scenario must adhere to the constraints mentioned above while learning from the stream by storing texts for a limited time and consuming low memory. In this study, we performed a systematic literature review regarding concept drift adaptation in text stream scenarios. Considering well-defined criteria, we selected 40 papers to unravel aspects such as text drift categories, types of text drift detection, model update mechanism, the addressed stream mining tasks, types of text representations, and text representation update mechanism. In addition, we discussed drift visualization and simulation and listed real-world datasets used in the selected papers. Therefore, this paper comprehensively reviews the concept drift adaptation in text stream mining scenarios.
Machine Learning Methods for Histopathological Image Analysis: A Review
Feb 07, 2021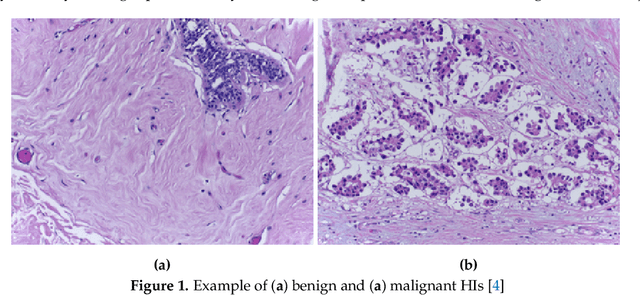
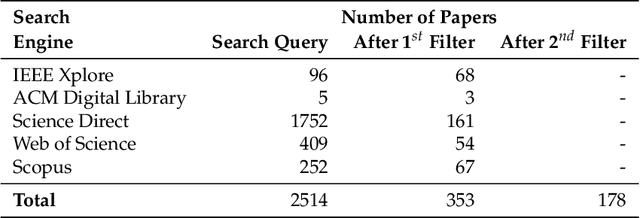
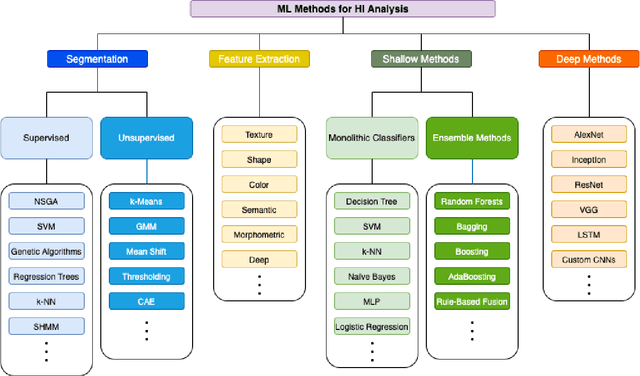
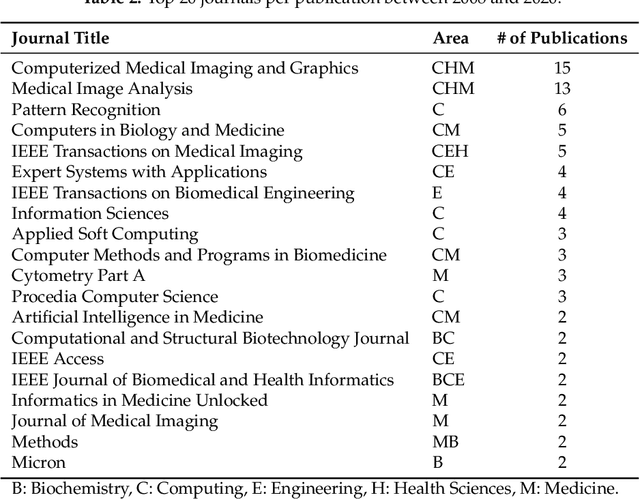
Histopathological images (HIs) are the gold standard for evaluating some types of tumors for cancer diagnosis. The analysis of such images is not only time and resource consuming, but also very challenging even for experienced pathologists, resulting in inter- and intra-observer disagreements. One of the ways of accelerating such an analysis is to use computer-aided diagnosis (CAD) systems. In this paper, we present a review on machine learning methods for histopathological image analysis, including shallow and deep learning methods. We also cover the most common tasks in HI analysis, such as segmentation and feature extraction. In addition, we present a list of publicly available and private datasets that have been used in HI research.
A Novel Orthogonal Direction Mesh Adaptive Direct Search Approach for SVM Hyperparameter Tuning
Apr 26, 2019
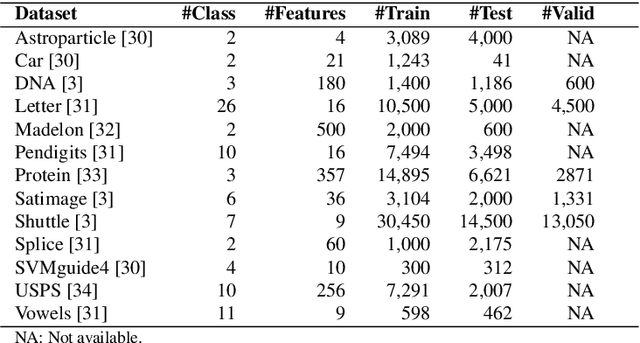
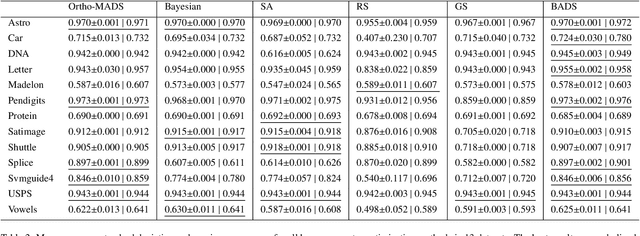
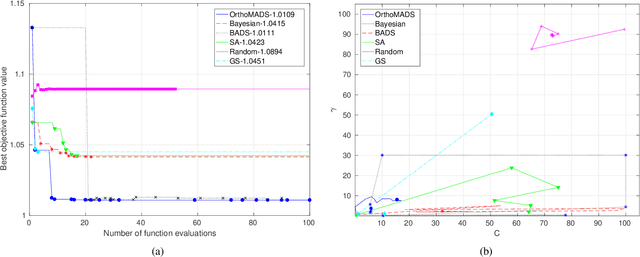
In this paper, we propose the use of a black-box optimization method called deterministic Mesh Adaptive Direct Search (MADS) algorithm with orthogonal directions (Ortho-MADS) for the selection of hyperparameters of Support Vector Machines with a Gaussian kernel. Different from most of the methods in the literature that exploit the properties of the data or attempt to minimize the accuracy of a validation dataset over the first quadrant of (C, gamma), the Ortho-MADS provides convergence proof. We present the MADS, followed by the Ortho-MADS, the dynamic stopping criterion defined by the MADS mesh size and two different search strategies (Nelder-Mead and Variable Neighborhood Search) that contribute to a competitive convergence rate as well as a mechanism to escape from undesired local minima. We have investigated the practical selection of hyperparameters for the Support Vector Machine with a Gaussian kernel, i.e., properly choose the hyperparameters gamma (bandwidth) and C (trade-off) on several benchmark datasets. The experimental results have shown that the proposed approach for hyperparameter tuning consistently finds comparable or better solutions, when using a common configuration, than other methods. We have also evaluated the accuracy and the number of function evaluations of the Ortho-MADS with the Nelder-Mead search strategy and the Variable Neighborhood Search strategy using the mesh size as a stopping criterion, and we have achieved accuracy that no other method for hyperparameters optimization could reach.
Histopathologic Image Processing: A Review
Apr 16, 2019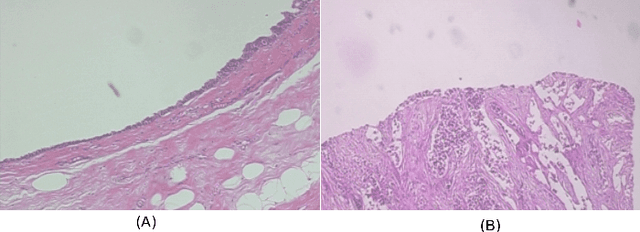
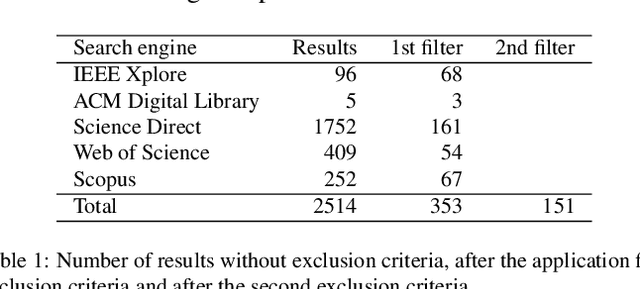
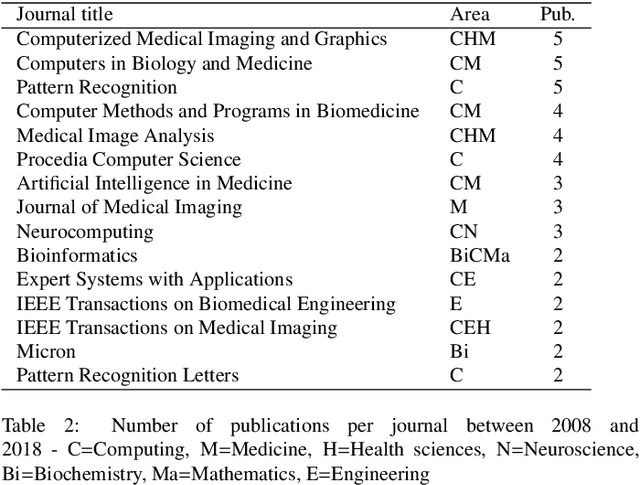
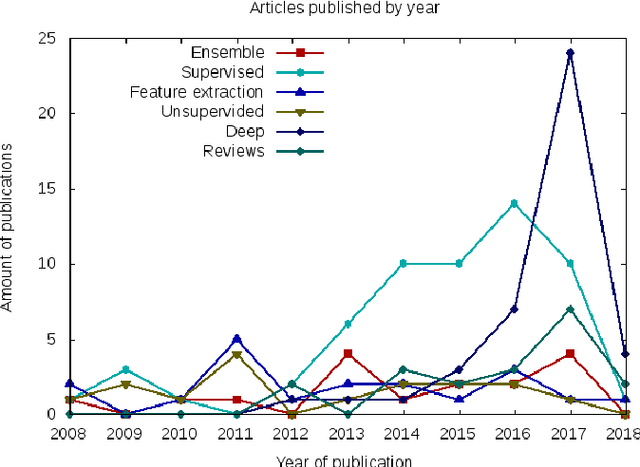
Histopathologic Images (HI) are the gold standard for evaluation of some tumors. However, the analysis of such images is challenging even for experienced pathologists, resulting in problems of inter and intra observer. Besides that, the analysis is time and resource consuming. One of the ways to accelerate such an analysis is by using Computer Aided Diagnosis systems. In this work we present a literature review about the computing techniques to process HI, including shallow and deep methods. We cover the most common tasks for processing HI such as segmentation, feature extraction, unsupervised learning and supervised learning. A dataset section show some datasets found during the literature review. We also bring a study case of breast cancer classification using a mix of deep and shallow machine learning methods. The proposed method obtained an accuracy of 91% in the best case, outperforming the compared baseline of the dataset.