 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploiting complex pattern features for interactive pattern mining
Apr 08, 2022

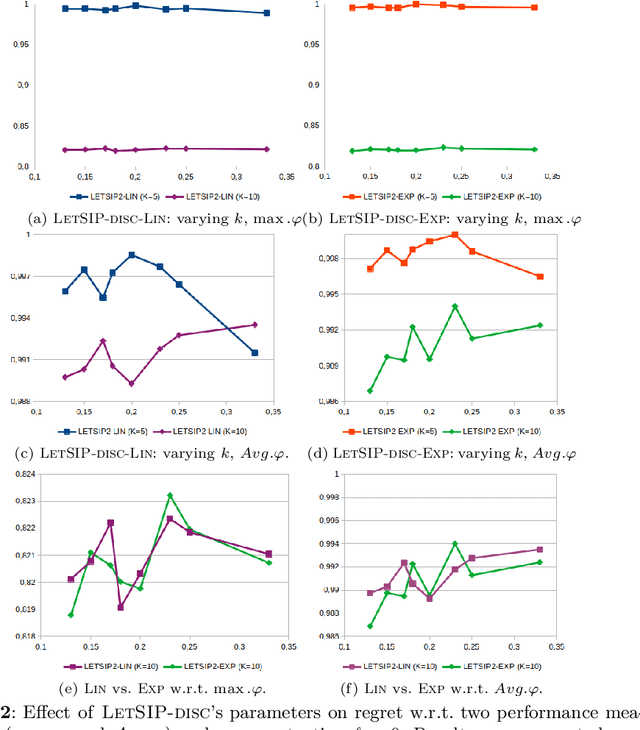
Recent years have seen a shift from a pattern mining process that has users define constraints before-hand, and sift through the results afterwards, to an interactive one. This new framework depends on exploiting user feedback to learn a quality function for patterns. Existing approaches have a weakness in that they use static pre-defined low-level features, and attempt to learn independent weights representing their importance to the user. As an alternative, we propose to work with more complex features that are derived directly from the pattern ranking imposed by the user. Learned weights are then aggregated onto lower-level features and help to drive the quality function in the right direction. We explore the effect of different parameter choices experimentally and find that using higher-complexity features leads to the selection of patterns that are better aligned with a hidden quality function while not adding significantly to the run times of the method. Getting good user feedback requires to quickly present diverse patterns, something that we achieve but pushing an existing diversity constraint into the sampling component of the interactive mining system LetSip. Resulting patterns allow in most cases to converge to a good solution more quickly. Combining the two improvements, finally, leads to an algorithm showing clear advantages over the existing state-of-the-art.
Wages of wins: could an amateur make money from match outcome predictions?
Feb 17, 2017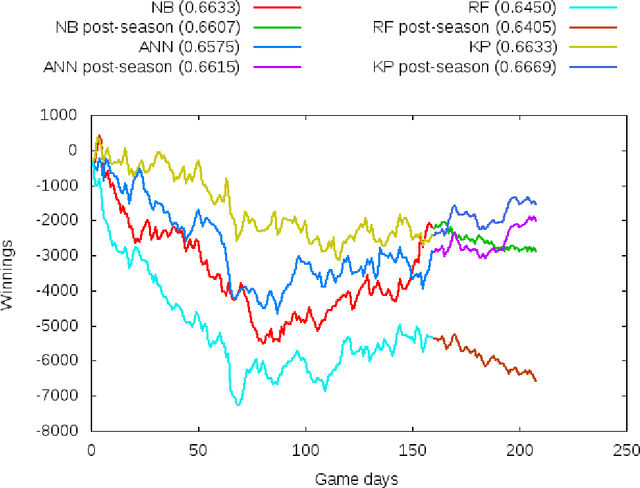


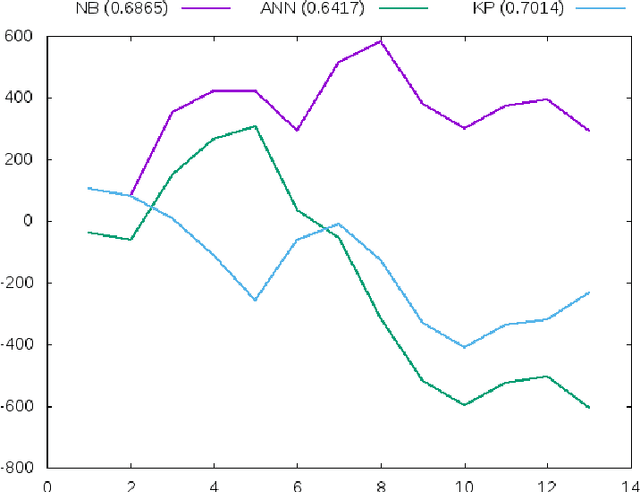
Evaluating the accuracies of models for match outcome predictions is nice and well but in the end the real proof is in the money to be made by betting. To evaluate the question whether the models developed by us could be used easily to make money via sports betting, we evaluate three cases: NCAAB post-season, NBA season, and NFL season, and find that it is possible yet not without its pitfalls. In particular, we illustrate that high accuracy does not automatically equal high pay-out, by looking at the type of match-ups that are predicted correctly by different models.
Exploring the efficacy of molecular fragments of different complexity in computational SAR modeling
Jan 13, 2015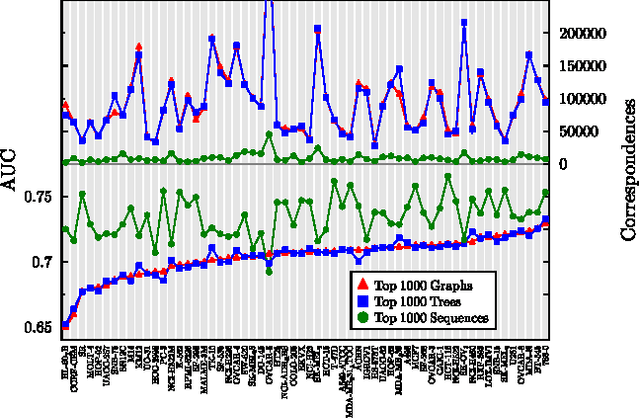
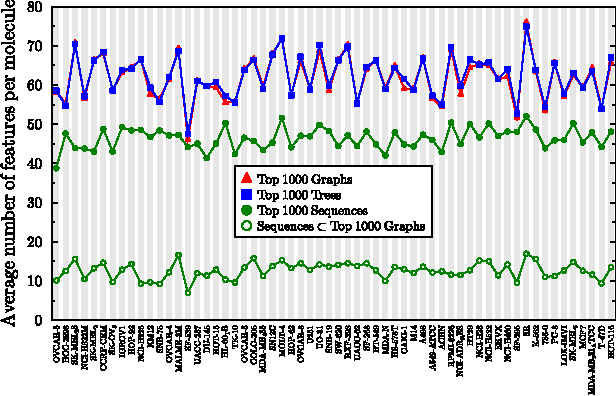
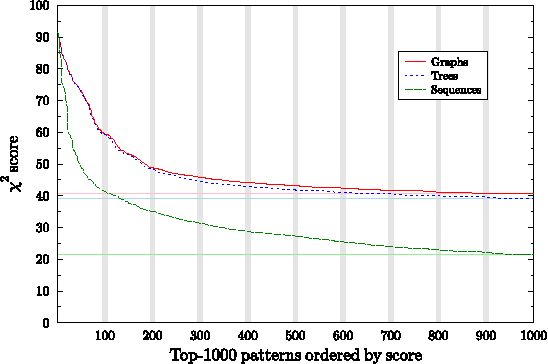
An important first step in computational SAR modeling is to transform the compounds into a representation that can be processed by predictive modeling techniques. This is typically a feature vector where each feature indicates the presence or absence of a molecular fragment. While the traditional approach to SAR modeling employed size restricted fingerprints derived from path fragments, much research in recent years focussed on mining more complex graph based fragments. Today, there seems to be a growing consensus in the data mining community that these more expressive fragments should be more useful. We question this consensus and show experimentally that fragments of low complexity, i.e. sequences, perform better than equally large sets of more complex ones, an effect we explain by pairwise correlation among fragments and the ability of a fragment set to encode compounds from different classes distinctly. The size restriction on these sets is based on ordering the fragments by class-correlation scores. In addition, we also evaluate the effects of using a significance value instead of a length restriction for path fragments and find a significant reduction in the number of features with little loss in performance.
A feature construction framework based on outlier detection and discriminative pattern mining
Jul 17, 2014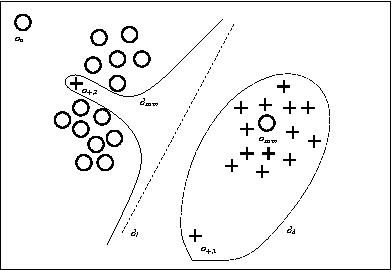
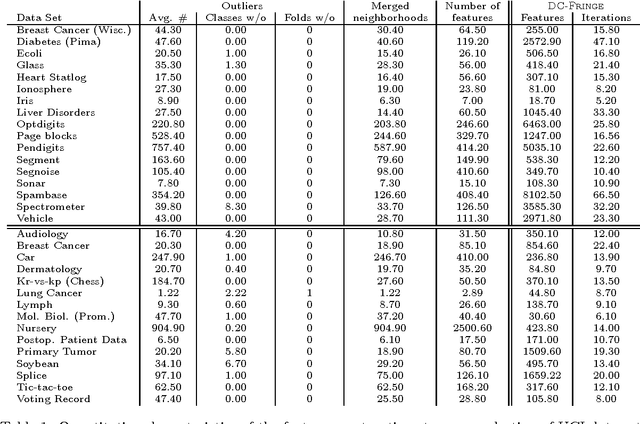
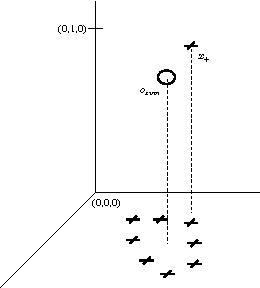
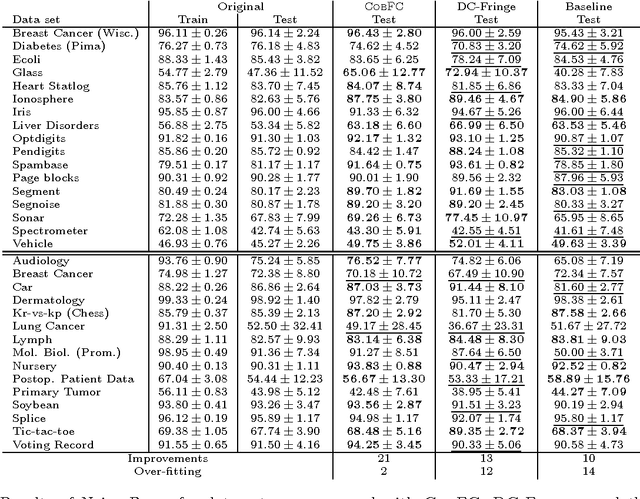
No matter the expressive power and sophistication of supervised learning algorithms, their effectiveness is restricted by the features describing the data. This is not a new insight in ML and many methods for feature selection, transformation, and construction have been developed. But while this is on-going for general techniques for feature selection and transformation, i.e. dimensionality reduction, work on feature construction, i.e. enriching the data, is by now mainly the domain of image, particularly character, recognition, and NLP. In this work, we propose a new general framework for feature construction. The need for feature construction in a data set is indicated by class outliers and discriminative pattern mining used to derive features on their k-neighborhoods. We instantiate the framework with LOF and C4.5-Rules, and evaluate the usefulness of the derived features on a diverse collection of UCI data sets. The derived features are more often useful than ones derived by DC-Fringe, and our approach is much less likely to overfit. But while a weak learner, Naive Bayes, benefits strongly from the feature construction, the effect is less pronounced for C4.5, and almost vanishes for an SVM leaner. Keywords: feature construction, classification, outlier detection
Predicting college basketball match outcomes using machine learning techniques: some results and lessons learned
Oct 14, 2013
Most existing work on predicting NCAAB matches has been developed in a statistical context. Trusting the capabilities of ML techniques, particularly classification learners, to uncover the importance of features and learn their relationships, we evaluated a number of different paradigms on this task. In this paper, we summarize our work, pointing out that attributes seem to be more important than models, and that there seems to be an upper limit to predictive quality.
Pattern-Based Classification: A Unifying Perspective
Nov 26, 2011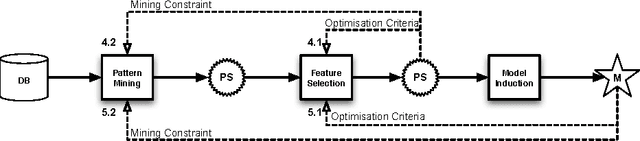
The use of patterns in predictive models is a topic that has received a lot of attention in recent years. Pattern mining can help to obtain models for structured domains, such as graphs and sequences, and has been proposed as a means to obtain more accurate and more interpretable models. Despite the large amount of publications devoted to this topic, we believe however that an overview of what has been accomplished in this area is missing. This paper presents our perspective on this evolving area. We identify the principles of pattern mining that are important when mining patterns for models and provide an overview of pattern-based classification methods. We categorize these methods along the following dimensions: (1) whether they post-process a pre-computed set of patterns or iteratively execute pattern mining algorithms; (2) whether they select patterns model-independently or whether the pattern selection is guided by a model. We summarize the results that have been obtained for each of these methods.