 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring the efficacy of molecular fragments of different complexity in computational SAR modeling
Paper and Code
Jan 13, 2015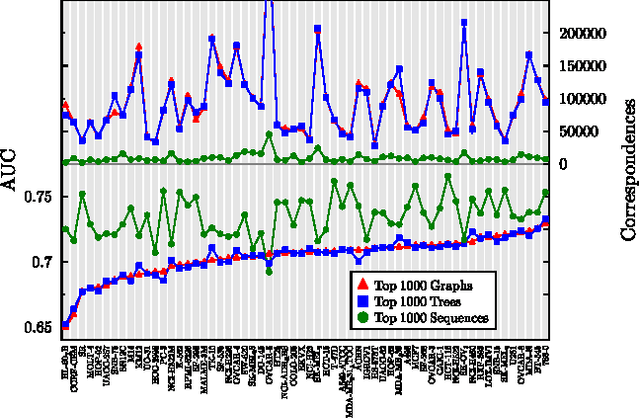
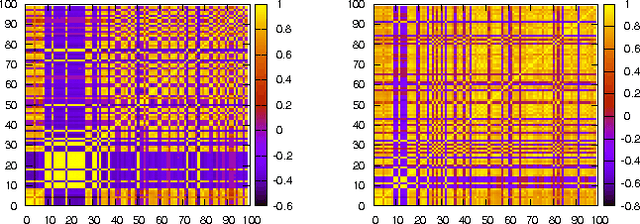
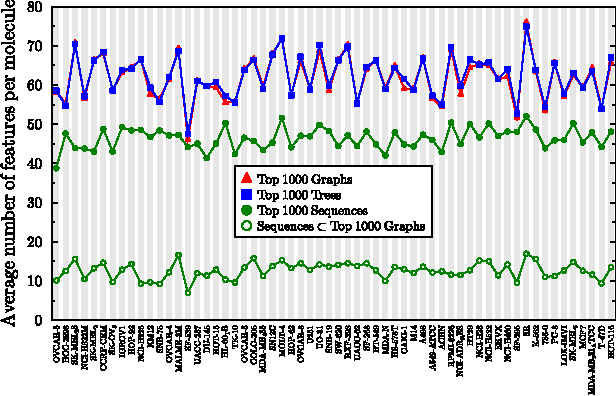
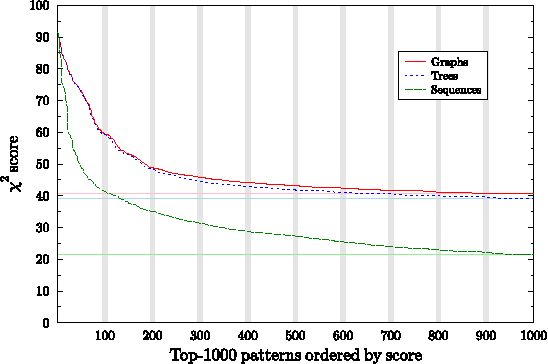
An important first step in computational SAR modeling is to transform the compounds into a representation that can be processed by predictive modeling techniques. This is typically a feature vector where each feature indicates the presence or absence of a molecular fragment. While the traditional approach to SAR modeling employed size restricted fingerprints derived from path fragments, much research in recent years focussed on mining more complex graph based fragments. Today, there seems to be a growing consensus in the data mining community that these more expressive fragments should be more useful. We question this consensus and show experimentally that fragments of low complexity, i.e. sequences, perform better than equally large sets of more complex ones, an effect we explain by pairwise correlation among fragments and the ability of a fragment set to encode compounds from different classes distinctly. The size restriction on these sets is based on ordering the fragments by class-correlation scores. In addition, we also evaluate the effects of using a significance value instead of a length restriction for path fragments and find a significant reduction in the number of features with little loss in performance.