 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUbiQVision: Quantifying Uncertainty in XAI for Image Recognition
Dec 23, 2025Recent advances in deep learning have led to its widespread adoption across diverse domains, including medical imaging. This progress is driven by increasingly sophisticated model architectures, such as ResNets, Vision Transformers, and Hybrid Convolutional Neural Networks, that offer enhanced performance at the cost of greater complexity. This complexity often compromises model explainability and interpretability. SHAP has emerged as a prominent method for providing interpretable visualizations that aid domain experts in understanding model predictions. However, SHAP explanations can be unstable and unreliable in the presence of epistemic and aleatoric uncertainty. In this study, we address this challenge by using Dirichlet posterior sampling and Dempster-Shafer theory to quantify the uncertainty that arises from these unstable explanations in medical imaging applications. The framework uses a belief, plausible, and fusion map approach alongside statistical quantitative analysis to produce quantification of uncertainty in SHAP. Furthermore, we evaluated our framework on three medical imaging datasets with varying class distributions, image qualities, and modality types which introduces noise due to varying image resolutions and modality-specific aspect covering the examples from pathology, ophthalmology, and radiology, introducing significant epistemic uncertainty.
PepTriX: A Framework for Explainable Peptide Analysis through Protein Language Models
Nov 13, 2025Peptide classification tasks, such as predicting toxicity and HIV inhibition, are fundamental to bioinformatics and drug discovery. Traditional approaches rely heavily on handcrafted encodings of one-dimensional (1D) peptide sequences, which can limit generalizability across tasks and datasets. Recently, protein language models (PLMs), such as ESM-2 and ESMFold, have demonstrated strong predictive performance. However, they face two critical challenges. First, fine-tuning is computationally costly. Second, their complex latent representations hinder interpretability for domain experts. Additionally, many frameworks have been developed for specific types of peptide classification, lacking generalization. These limitations restrict the ability to connect model predictions to biologically relevant motifs and structural properties. To address these limitations, we present PepTriX, a novel framework that integrates one dimensional (1D) sequence embeddings and three-dimensional (3D) structural features via a graph attention network enhanced with contrastive training and cross-modal co-attention. PepTriX automatically adapts to diverse datasets, producing task-specific peptide vectors while retaining biological plausibility. After evaluation by domain experts, we found that PepTriX performs remarkably well across multiple peptide classification tasks and provides interpretable insights into the structural and biophysical motifs that drive predictions. Thus, PepTriX offers both predictive robustness and interpretable validation, bridging the gap between performance-driven peptide-level models (PLMs) and domain-level understanding in peptide research.
PHAX: A Structured Argumentation Framework for User-Centered Explainable AI in Public Health and Biomedical Sciences
Jul 29, 2025Ensuring transparency and trust in AI-driven public health and biomedical sciences systems requires more than accurate predictions-it demands explanations that are clear, contextual, and socially accountable. While explainable AI (XAI) has advanced in areas like feature attribution and model interpretability, most methods still lack the structure and adaptability needed for diverse health stakeholders, including clinicians, policymakers, and the general public. We introduce PHAX-a Public Health Argumentation and eXplainability framework-that leverages structured argumentation to generate human-centered explanations for AI outputs. PHAX is a multi-layer architecture combining defeasible reasoning, adaptive natural language techniques, and user modeling to produce context-aware, audience-specific justifications. More specifically, we show how argumentation enhances explainability by supporting AI-driven decision-making, justifying recommendations, and enabling interactive dialogues across user types. We demonstrate the applicability of PHAX through use cases such as medical term simplification, patient-clinician communication, and policy justification. In particular, we show how simplification decisions can be modeled as argument chains and personalized based on user expertise-enhancing both interpretability and trust. By aligning formal reasoning methods with communicative demands, PHAX contributes to a broader vision of transparent, human-centered AI in public health.
AI Readiness in Healthcare through Storytelling XAI
Oct 24, 2024
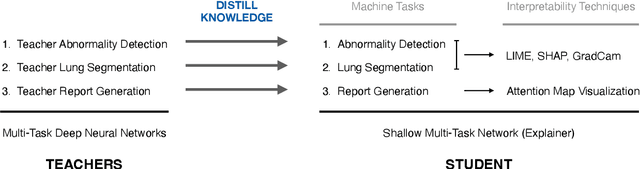
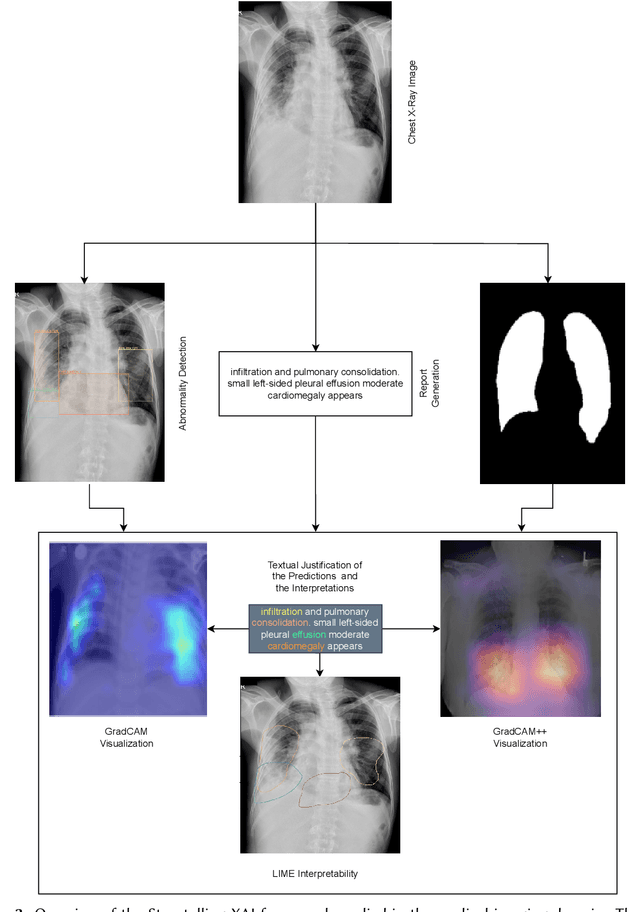
Artificial Intelligence is rapidly advancing and radically impacting everyday life, driven by the increasing availability of computing power. Despite this trend, the adoption of AI in real-world healthcare is still limited. One of the main reasons is the trustworthiness of AI models and the potential hesitation of domain experts with model predictions. Explainable Artificial Intelligence (XAI) techniques aim to address these issues. However, explainability can mean different things to people with different backgrounds, expertise, and goals. To address the target audience with diverse needs, we develop storytelling XAI. In this research, we have developed an approach that combines multi-task distillation with interpretability techniques to enable audience-centric explainability. Using multi-task distillation allows the model to exploit the relationships between tasks, potentially improving interpretability as each task supports the other leading to an enhanced interpretability from the perspective of a domain expert. The distillation process allows us to extend this research to large deep models that are highly complex. We focus on both model-agnostic and model-specific methods of interpretability, supported by textual justification of the results in healthcare through our use case. Our methods increase the trust of both the domain experts and the machine learning experts to enable a responsible AI.
Whom to Trust? Elective Learning for Distributed Gaussian Process Regression
Feb 05, 2024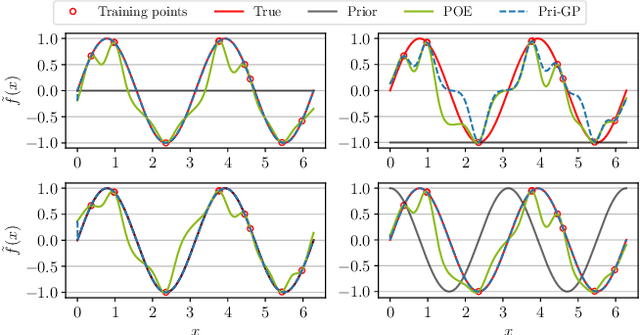
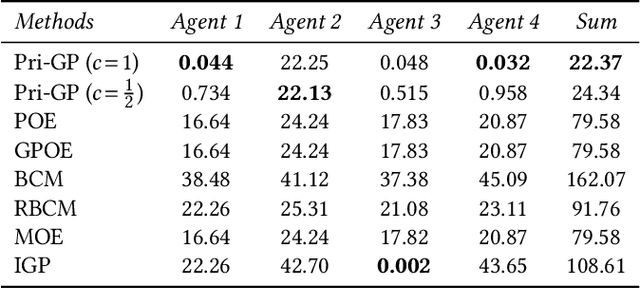
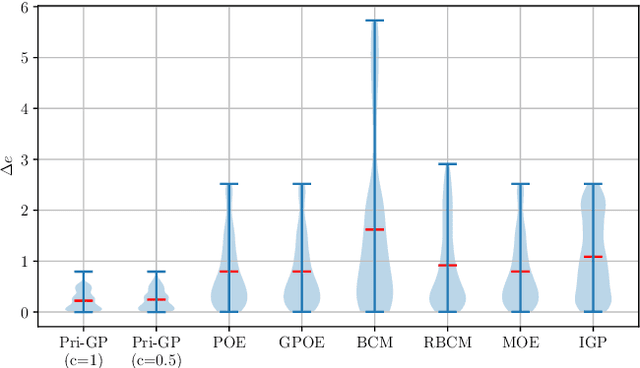
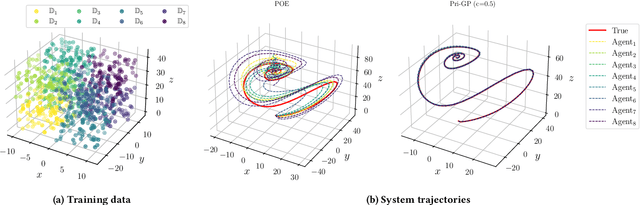
This paper introduces an innovative approach to enhance distributed cooperative learning using Gaussian process (GP) regression in multi-agent systems (MASs). The key contribution of this work is the development of an elective learning algorithm, namely prior-aware elective distributed GP (Pri-GP), which empowers agents with the capability to selectively request predictions from neighboring agents based on their trustworthiness. The proposed Pri-GP effectively improves individual prediction accuracy, especially in cases where the prior knowledge of an agent is incorrect. Moreover, it eliminates the need for computationally intensive variance calculations for determining aggregation weights in distributed GP. Furthermore, we establish a prediction error bound within the Pri-GP framework, ensuring the reliability of predictions, which is regarded as a crucial property in safety-critical MAS applications.
Synergy: A HW/SW Framework for High Throughput CNNs on Embedded Heterogeneous SoC
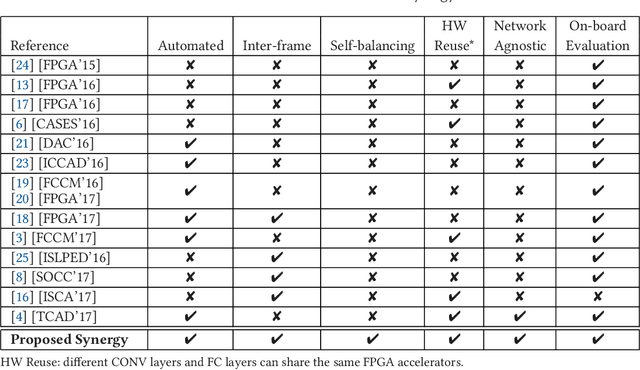
Mar 28, 2018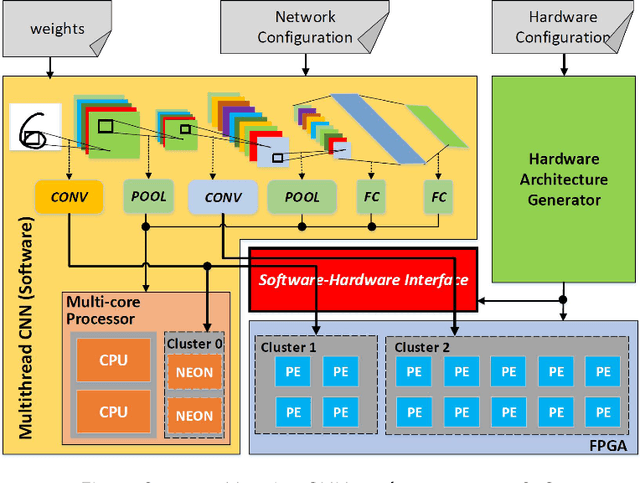
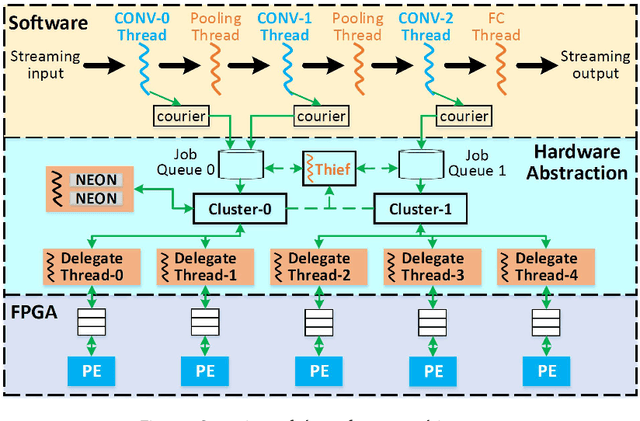
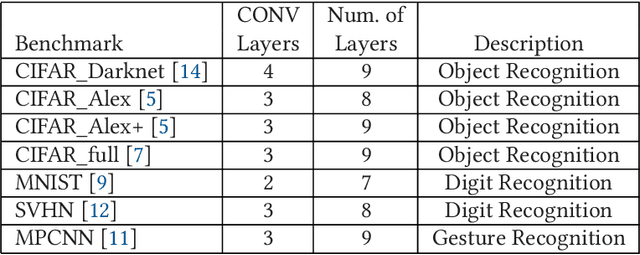
Convolutional Neural Networks (CNN) have been widely deployed in diverse application domains. There has been significant progress in accelerating both their training and inference using high-performance GPUs, FPGAs, and custom ASICs for datacenter-scale environments. The recent proliferation of mobile and IoT devices have necessitated real-time, energy-efficient deep neural network inference on embedded-class, resource-constrained platforms. In this context, we present {\em Synergy}, an automated, hardware-software co-designed, pipelined, high-throughput CNN inference framework on embedded heterogeneous system-on-chip (SoC) architectures (Xilinx Zynq). {\em Synergy} leverages, through multi-threading, all the available on-chip resources, which includes the dual-core ARM processor along with the FPGA and the NEON SIMD engines as accelerators. Moreover, {\em Synergy} provides a unified abstraction of the heterogeneous accelerators (FPGA and NEON) and can adapt to different network configurations at runtime without changing the underlying hardware accelerator architecture by balancing workload across accelerators through work-stealing. {\em Synergy} achieves 7.3X speedup, averaged across seven CNN models, over a well-optimized software-only solution. {\em Synergy} demonstrates substantially better throughput and energy-efficiency compared to the contemporary CNN implementations on the same SoC architecture.