 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynergy: A HW/SW Framework for High Throughput CNNs on Embedded Heterogeneous SoC
Paper and Code
Mar 28, 2018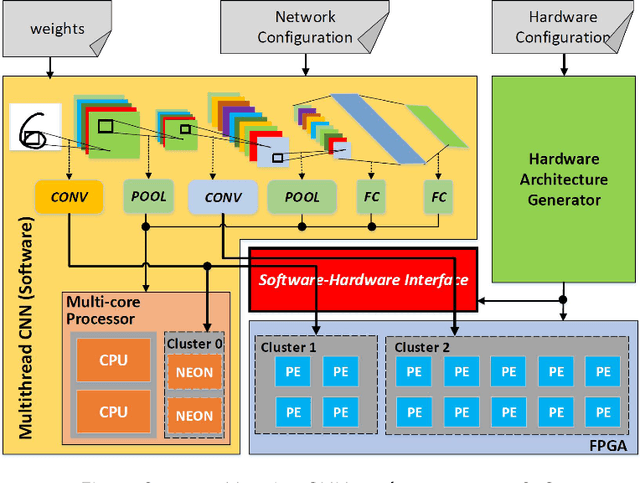
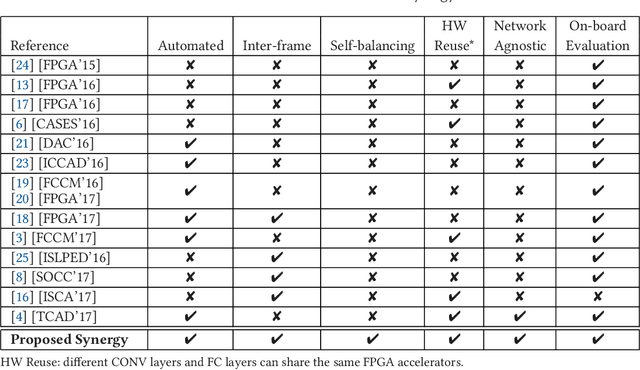
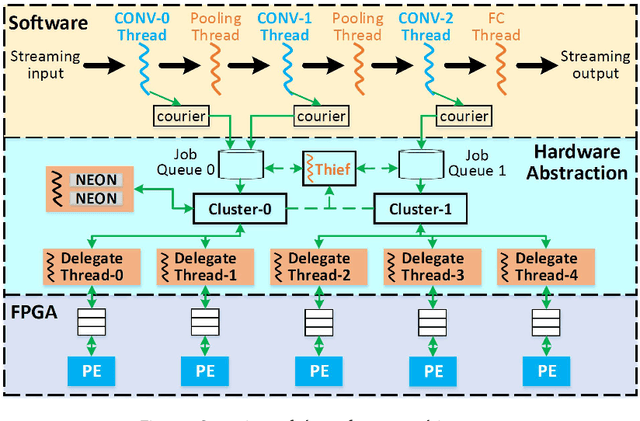
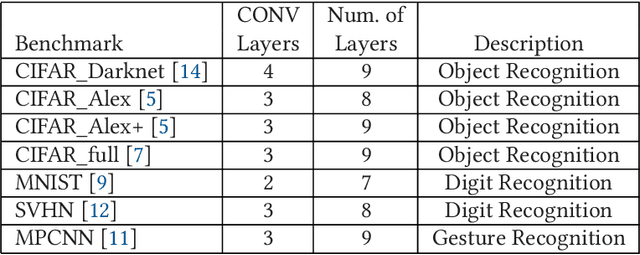
Convolutional Neural Networks (CNN) have been widely deployed in diverse application domains. There has been significant progress in accelerating both their training and inference using high-performance GPUs, FPGAs, and custom ASICs for datacenter-scale environments. The recent proliferation of mobile and IoT devices have necessitated real-time, energy-efficient deep neural network inference on embedded-class, resource-constrained platforms. In this context, we present {\em Synergy}, an automated, hardware-software co-designed, pipelined, high-throughput CNN inference framework on embedded heterogeneous system-on-chip (SoC) architectures (Xilinx Zynq). {\em Synergy} leverages, through multi-threading, all the available on-chip resources, which includes the dual-core ARM processor along with the FPGA and the NEON SIMD engines as accelerators. Moreover, {\em Synergy} provides a unified abstraction of the heterogeneous accelerators (FPGA and NEON) and can adapt to different network configurations at runtime without changing the underlying hardware accelerator architecture by balancing workload across accelerators through work-stealing. {\em Synergy} achieves 7.3X speedup, averaged across seven CNN models, over a well-optimized software-only solution. {\em Synergy} demonstrates substantially better throughput and energy-efficiency compared to the contemporary CNN implementations on the same SoC architecture.