 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSolving the swing-up and balance task for the Acrobot and Pendubot with SAC
Dec 18, 2023



We present a solution of the swing-up and balance task for the pendubot and acrobot for the participation in the AI Olympics competition at IJCAI 2023. Our solution is based on the Soft Actor Crtic (SAC) reinforcement learning (RL) algorithm for training a policy for the swing-up and entering the region of attraction of a linear quadratic regulator(LQR) controller for stabilizing the double pendulum at the top position. Our controller achieves competitive scores in performance and robustness for both, pendubot and acrobot, problem scenarios.
A systems design approach for the co-design of a humanoid robot arm
Dec 29, 2022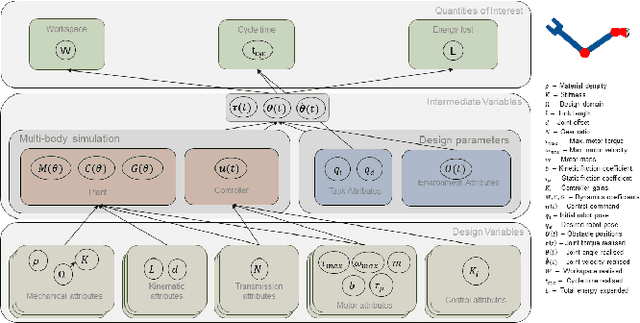


Classically, the development of humanoid robots has been sequential and iterative. Such bottom-up design procedures rely heavily on intuition and are often biased by the designer's experience. Exploiting the non-linear coupled design space of robots is non-trivial and requires a systematic procedure for exploration. We adopt the top-down design strategy, the V-model, used in automotive and aerospace industries. Our co-design approach identifies non-intuitive designs from within the design space and obtains the maximum permissible range of the design variables as a solution space, to physically realise the obtained design. We show that by constructing the solution space, one can (1) decompose higher-level requirements onto sub-system-level requirements with tolerance, alleviating the "chicken-or-egg" problem during the design process, (2) decouple the robot's morphology from its controller, enabling greater design flexibility, (3) obtain independent sub-system level requirements, reducing the development time by parallelising the development process.
MaMiC: Macro and Micro Curriculum for Robotic Reinforcement Learning
May 17, 2019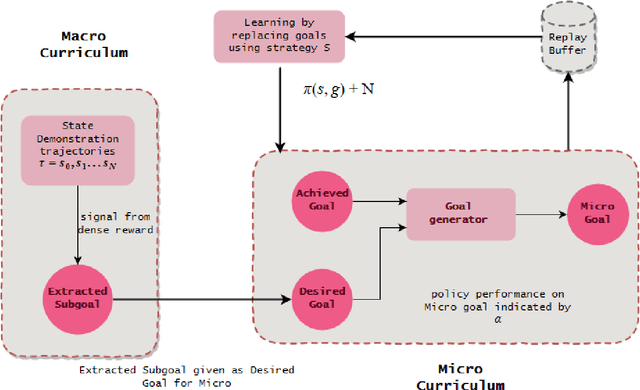

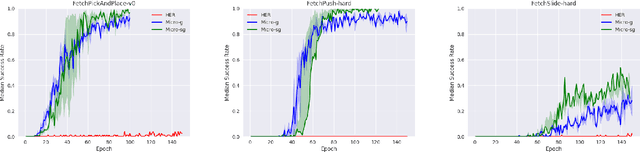
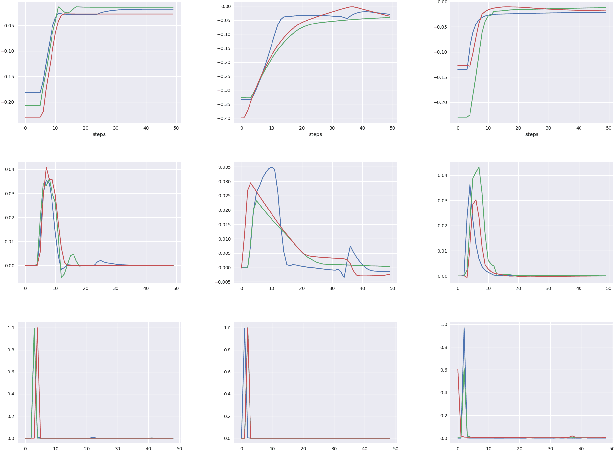
Shaping in humans and animals has been shown to be a powerful tool for learning complex tasks as compared to learning in a randomized fashion. This makes the problem less complex and enables one to solve the easier sub task at hand first. Generating a curriculum for such guided learning involves subjecting the agent to easier goals first, and then gradually increasing their difficulty. This paper takes a similar direction and proposes a dual curriculum scheme for solving robotic manipulation tasks with sparse rewards, called MaMiC. It includes a macro curriculum scheme which divides the task into multiple sub-tasks followed by a micro curriculum scheme which enables the agent to learn between such discovered sub-tasks. We show how combining macro and micro curriculum strategies help in overcoming major exploratory constraints considered in robot manipulation tasks without having to engineer any complex rewards. We also illustrate the meaning of the individual curricula and how they can be used independently based on the task. The performance of such a dual curriculum scheme is analyzed on the Fetch environments.