 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Training Music Taggers on Synthetic Data
Jul 02, 2024



Most contemporary music tagging systems rely on large volumes of annotated data. As an alternative, we investigate the extent to which synthetically generated music excerpts can improve tagging systems when only small annotated collections are available. To this end, we release GTZAN-synth, a synthetic dataset that follows the taxonomy of the well-known GTZAN dataset while being ten times larger in data volume. We first observe that simply adding this synthetic dataset to the training split of GTZAN does not result into performance improvements. We then proceed to investigating domain adaptation, transfer learning and fine-tuning strategies for the task at hand and draw the conclusion that the last two options yield an increase in accuracy. Overall, the proposed approach can be considered as a first guide in a promising field for future research.
Can MusicGen Create Training Data for MIR Tasks?
Nov 15, 2023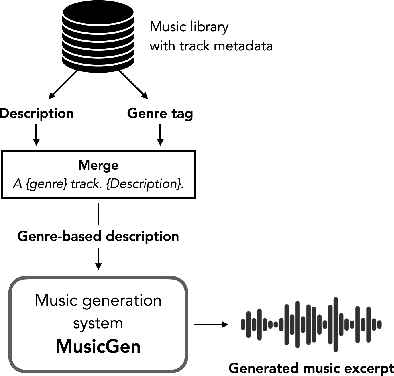

We are investigating the broader concept of using AI-based generative music systems to generate training data for Music Information Retrieval (MIR) tasks. To kick off this line of work, we ran an initial experiment in which we trained a genre classifier on a fully artificial music dataset created with MusicGen. We constructed over 50 000 genre- conditioned textual descriptions and generated a collection of music excerpts that covers five musical genres. Our preliminary results show that the proposed model can learn genre-specific characteristics from artificial music tracks that generalise well to real-world music recordings.
Improving Post-Processing of Audio Event Detectors Using Reinforcement Learning
Aug 19, 2022



We apply post-processing to the class probability distribution outputs of audio event classification models and employ reinforcement learning to jointly discover the optimal parameters for various stages of a post-processing stack, such as the classification thresholds and the kernel sizes of median filtering algorithms used to smooth out model predictions. To achieve this we define a reinforcement learning environment where: 1) a state is the class probability distribution provided by the model for a given audio sample, 2) an action is the choice of a candidate optimal value for each parameter of the post-processing stack, 3) the reward is based on the classification accuracy metric we aim to optimize, which is the audio event-based macro F1-score in our case. We apply our post-processing to the class probability distribution outputs of two audio event classification models submitted to the DCASE Task4 2020 challenge. We find that by using reinforcement learning to discover the optimal per-class parameters for the post-processing stack that is applied to the outputs of audio event classification models, we can improve the audio event-based macro F1-score (the main metric used in the DCASE challenge to compare audio event classification accuracy) by 4-5% compared to using the same post-processing stack with manually tuned parameters.
A Deep Reinforcement Learning Approach for Audio-based Navigation and Audio Source Localization in Multi-speaker Environments
Nov 08, 2021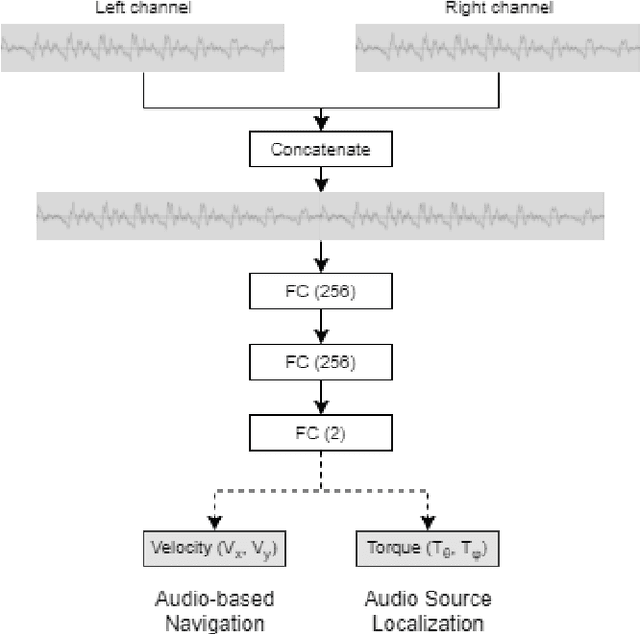
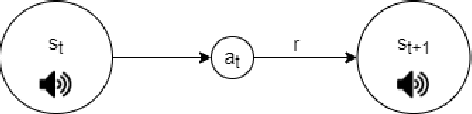
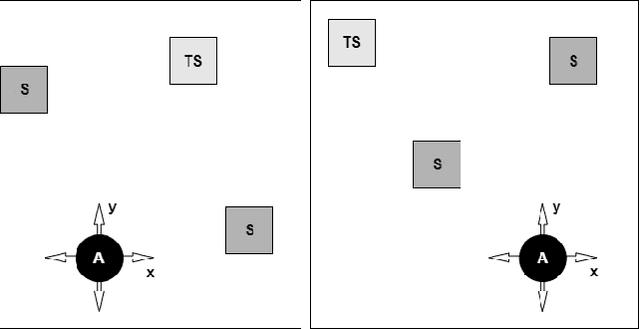
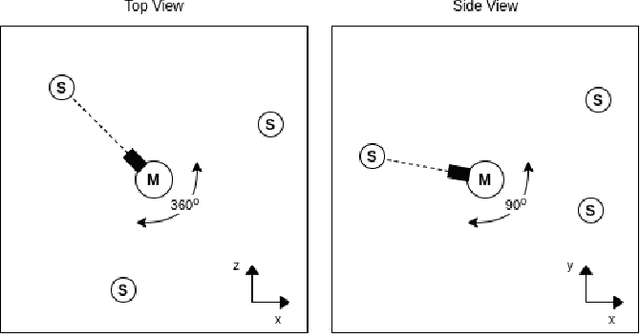
In this work we apply deep reinforcement learning to the problems of navigating a three-dimensional environment and inferring the locations of human speaker audio sources within, in the case where the only available information is the raw sound from the environment, as a simulated human listener placed in the environment would hear it. For this purpose we create two virtual environments using the Unity game engine, one presenting an audio-based navigation problem and one presenting an audio source localization problem. We also create an autonomous agent based on PPO online reinforcement learning algorithm and attempt to train it to solve these environments. Our experiments show that our agent achieves adequate performance and generalization ability in both environments, measured by quantitative metrics, even when a limited amount of training data are available or the environment parameters shift in ways not encountered during training. We also show that a degree of agent knowledge transfer is possible between the environments.
A Deep Reinforcement Learning Approach to Audio-Based Navigation in a Multi-Speaker Environment
May 10, 2021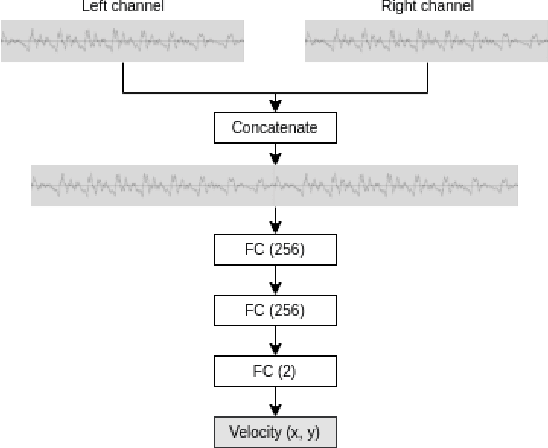
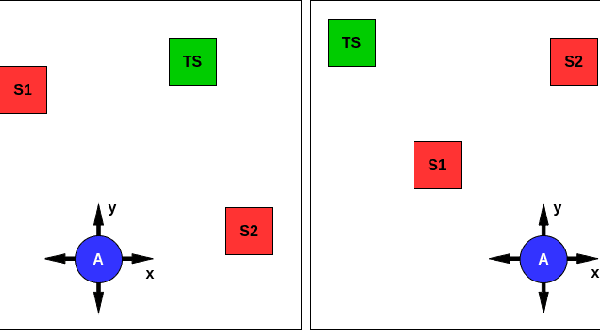
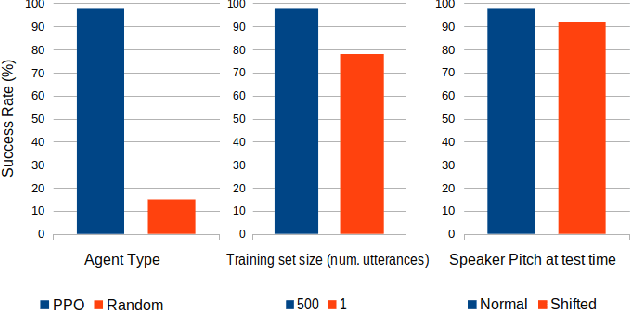
In this work we use deep reinforcement learning to create an autonomous agent that can navigate in a two-dimensional space using only raw auditory sensory information from the environment, a problem that has received very little attention in the reinforcement learning literature. Our experiments show that the agent can successfully identify a particular target speaker among a set of $N$ predefined speakers in a room and move itself towards that speaker, while avoiding collision with other speakers or going outside the room boundaries. The agent is shown to be robust to speaker pitch shifting and it can learn to navigate the environment, even when a limited number of training utterances are available for each speaker.
Online Co-movement Pattern Prediction in Mobility Data
Feb 17, 2021



Predictive analytics over mobility data are of great importance since they can assist an analyst to predict events, such as collisions, encounters, traffic jams, etc. A typical example of such analytics is future location prediction, where the goal is to predict the future location of a moving object,given a look-ahead time. What is even more challenging is being able to accurately predict collective behavioural patterns of movement, such as co-movement patterns. In this paper, we provide an accurate solution to the problem of Online Prediction of Co-movement Patterns. In more detail, we split the original problem into two sub-problems, namely Future Location Prediction and Evolving Cluster Detection. Furthermore, in order to be able to calculate the accuracy of our solution, we propose a co-movement pattern similarity measure, which facilitates us to match the predicted clusters with the actual ones. Finally, the accuracy of our solution is demonstrated experimentally over a real dataset from the maritime domain.