 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Post-Processing of Audio Event Detectors Using Reinforcement Learning
Aug 19, 2022



We apply post-processing to the class probability distribution outputs of audio event classification models and employ reinforcement learning to jointly discover the optimal parameters for various stages of a post-processing stack, such as the classification thresholds and the kernel sizes of median filtering algorithms used to smooth out model predictions. To achieve this we define a reinforcement learning environment where: 1) a state is the class probability distribution provided by the model for a given audio sample, 2) an action is the choice of a candidate optimal value for each parameter of the post-processing stack, 3) the reward is based on the classification accuracy metric we aim to optimize, which is the audio event-based macro F1-score in our case. We apply our post-processing to the class probability distribution outputs of two audio event classification models submitted to the DCASE Task4 2020 challenge. We find that by using reinforcement learning to discover the optimal per-class parameters for the post-processing stack that is applied to the outputs of audio event classification models, we can improve the audio event-based macro F1-score (the main metric used in the DCASE challenge to compare audio event classification accuracy) by 4-5% compared to using the same post-processing stack with manually tuned parameters.
A Deep Reinforcement Learning Approach for Audio-based Navigation and Audio Source Localization in Multi-speaker Environments
Nov 08, 2021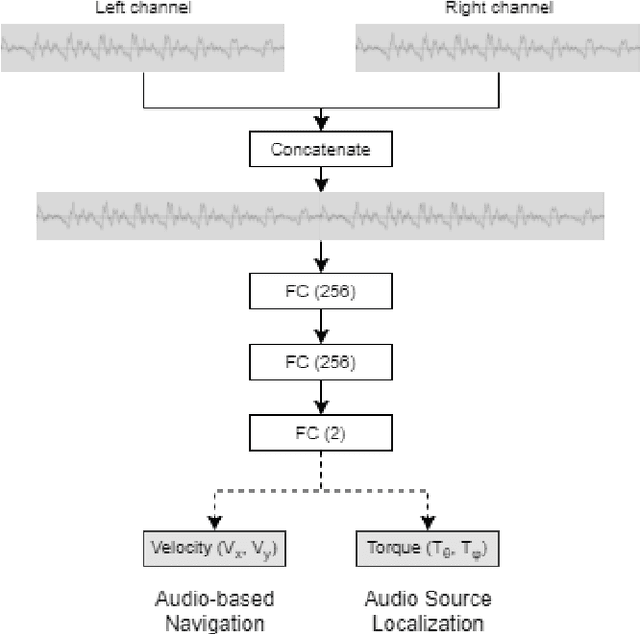
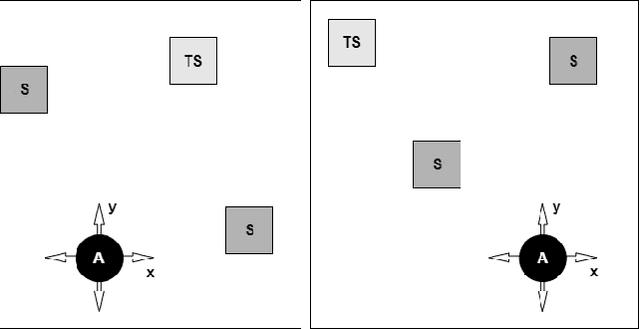
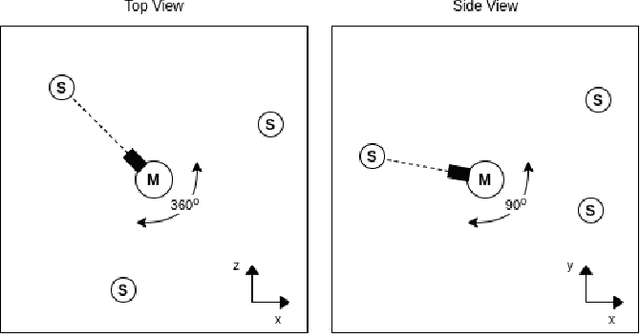
In this work we apply deep reinforcement learning to the problems of navigating a three-dimensional environment and inferring the locations of human speaker audio sources within, in the case where the only available information is the raw sound from the environment, as a simulated human listener placed in the environment would hear it. For this purpose we create two virtual environments using the Unity game engine, one presenting an audio-based navigation problem and one presenting an audio source localization problem. We also create an autonomous agent based on PPO online reinforcement learning algorithm and attempt to train it to solve these environments. Our experiments show that our agent achieves adequate performance and generalization ability in both environments, measured by quantitative metrics, even when a limited amount of training data are available or the environment parameters shift in ways not encountered during training. We also show that a degree of agent knowledge transfer is possible between the environments.
A Deep Reinforcement Learning Approach to Audio-Based Navigation in a Multi-Speaker Environment
May 10, 2021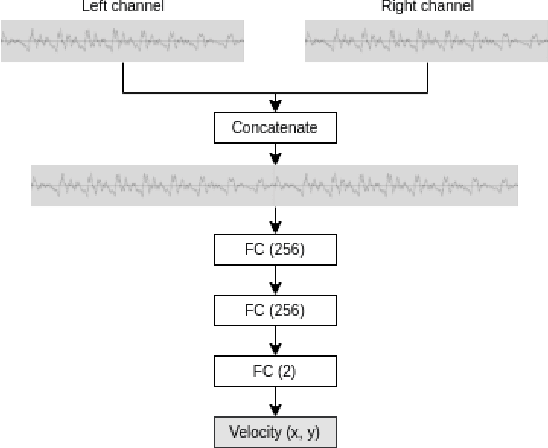
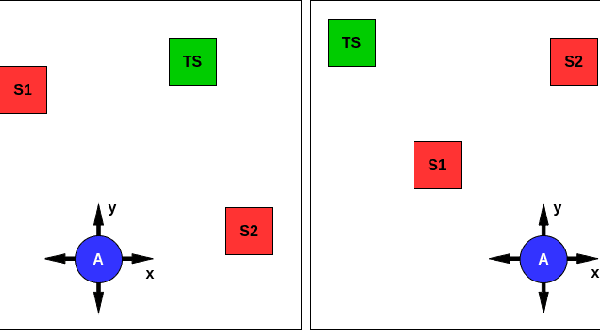
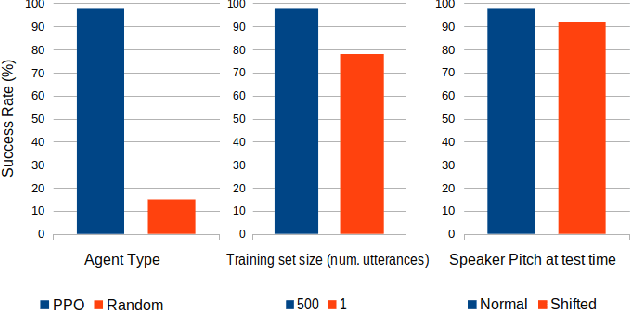
In this work we use deep reinforcement learning to create an autonomous agent that can navigate in a two-dimensional space using only raw auditory sensory information from the environment, a problem that has received very little attention in the reinforcement learning literature. Our experiments show that the agent can successfully identify a particular target speaker among a set of $N$ predefined speakers in a room and move itself towards that speaker, while avoiding collision with other speakers or going outside the room boundaries. The agent is shown to be robust to speaker pitch shifting and it can learn to navigate the environment, even when a limited number of training utterances are available for each speaker.
A Deep Q-Learning Agent for the L-Game with Variable Batch Training
Feb 17, 2018


We employ the Deep Q-Learning algorithm with Experience Replay to train an agent capable of achieving a high-level of play in the L-Game while self-learning from low-dimensional states. We also employ variable batch size for training in order to mitigate the loss of the rare reward signal and significantly accelerate training. Despite the large action space due to the number of possible moves, the low-dimensional state space and the rarity of rewards, which only come at the end of a game, DQL is successful in training an agent capable of strong play without the use of any search methods or domain knowledge.