 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Convolutional Deep Markov Model for Unsupervised Speech Representation Learning
Jun 03, 2020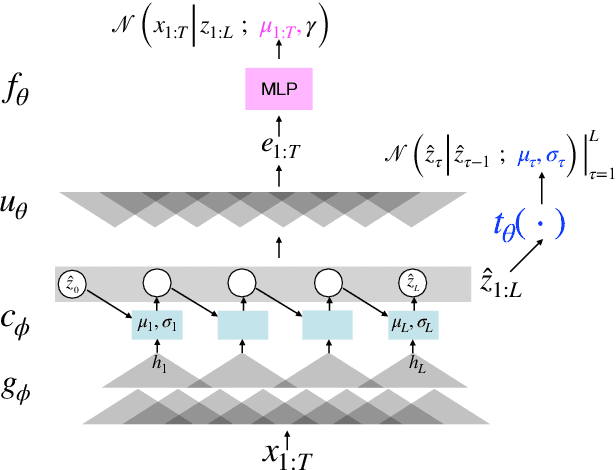

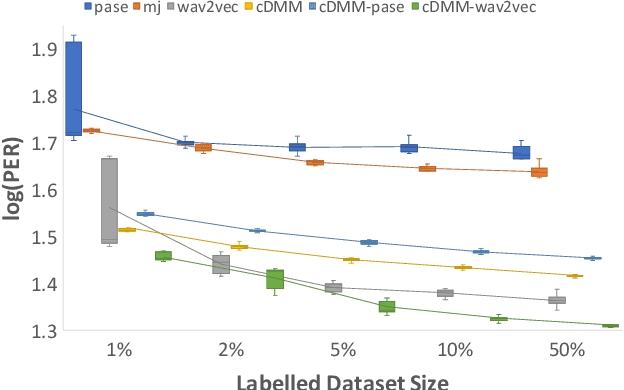
Probabilistic Latent Variable Models (LVMs) provide an alternative to self-supervised learning approaches for linguistic representation learning from speech. LVMs admit an intuitive probabilistic interpretation where the latent structure shapes the information extracted from the signal. Even though LVMs have recently seen a renewed interest due to the introduction of Variational Autoencoders (VAEs), their use for speech representation learning remains largely unexplored. In this work, we propose Convolutional Deep Markov Model (ConvDMM), a Gaussian state-space model with non-linear emission and transition functions modelled by deep neural networks. This unsupervised model is trained using black box variational inference. A deep convolutional neural network is used as an inference network for structured variational approximation. When trained on a large scale speech dataset (LibriSpeech), ConvDMM produces features that significantly outperform multiple self-supervised feature extracting methods on linear phone classification and recognition on the Wall Street Journal dataset. Furthermore, we found that ConvDMM complements self-supervised methods like Wav2Vec and PASE, improving on the results achieved with any of the methods alone. Lastly, we find that ConvDMM features enable learning better phone recognizers than any other features in an extreme low-resource regime with few labeled training examples.
Towards Using Context-Dependent Symbols in CTC Without State-Tying Decision Trees
Jan 14, 2019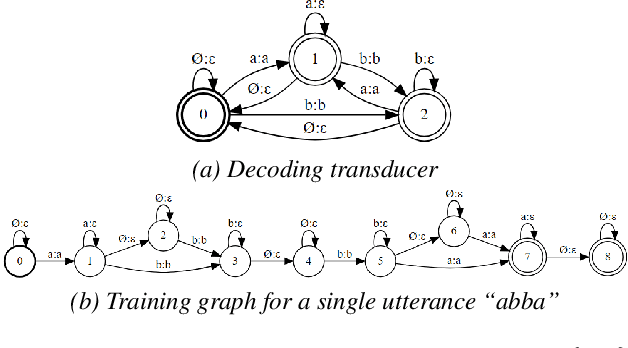
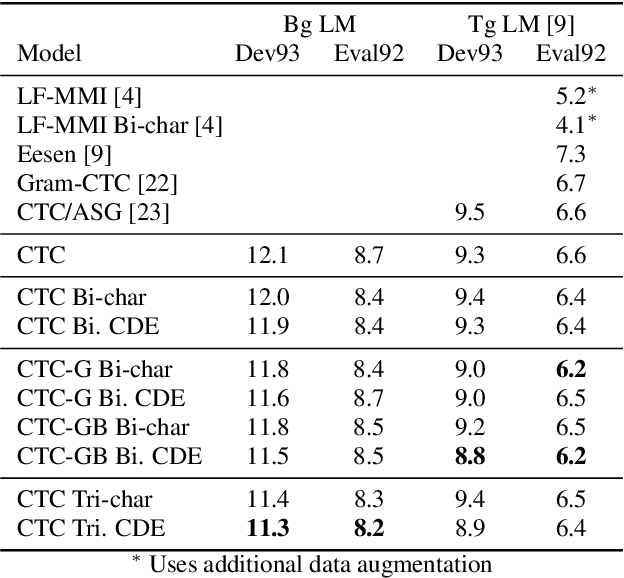

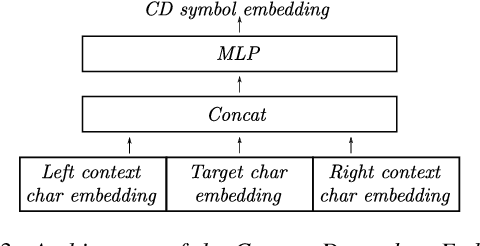
Deep neural acoustic models benefit from context dependent modeling of output symbols. However, their usage requires state-tying decision trees that are typically transferred from classical GMM-HMM systems. In this work we consider direct training of CTC networks with context dependent outputs. A state-tying decision tree is replaced with a neural network that predicts the weights of the final SoftMax classifier in a context-dependent way. This network is trained together with the rest of the acoustic model and lifts one of the last cases in which neural systems have to be bootstrapped from GMM-HMM ones. We describe changes to the CTC cost function that are needed to accommodate context-dependent symbols and validate this idea on bigram context dependent system built for character-based WSJ.
Efficient Purely Convolutional Text Encoding
Aug 03, 2018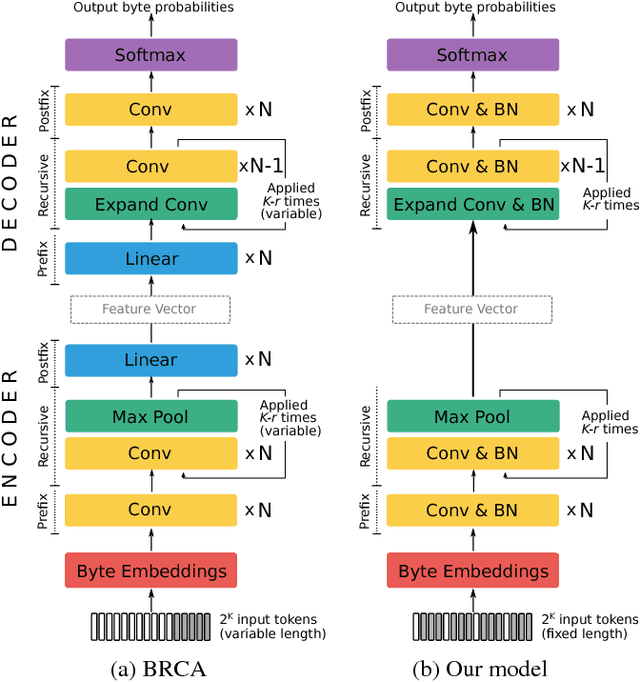
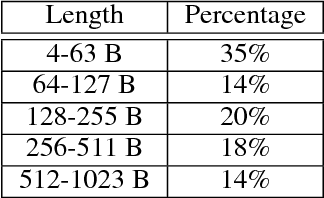
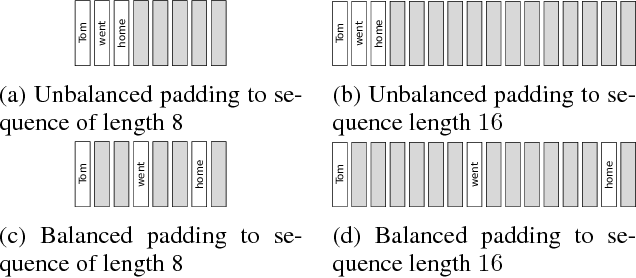
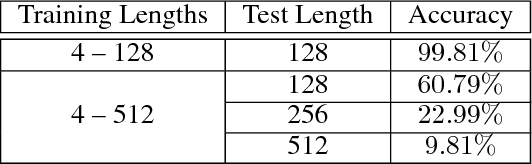
In this work, we focus on a lightweight convolutional architecture that creates fixed-size vector embeddings of sentences. Such representations are useful for building NLP systems, including conversational agents. Our work derives from a recently proposed recursive convolutional architecture for auto-encoding text paragraphs at byte level. We propose alternations that significantly reduce training time, the number of parameters, and improve auto-encoding accuracy. Finally, we evaluate the representations created by our model on tasks from SentEval benchmark suite, and show that it can serve as a better, yet fairly low-resource alternative to popular bag-of-words embeddings.