 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical classification of e-commerce related social media
Nov 26, 2015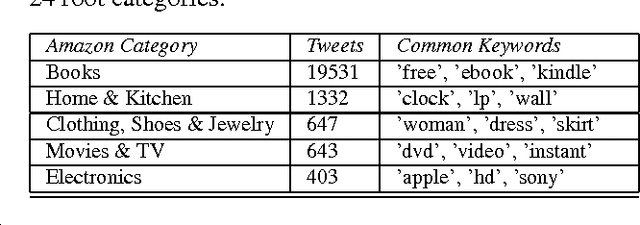
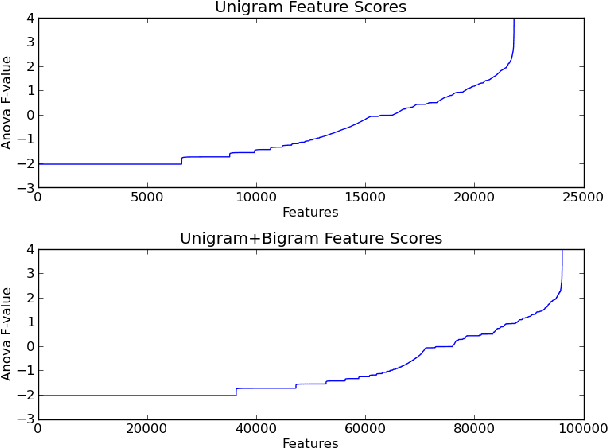
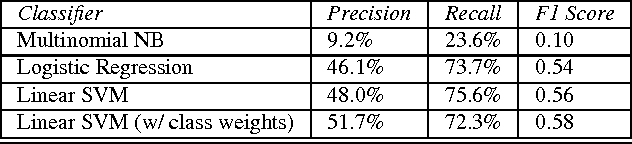
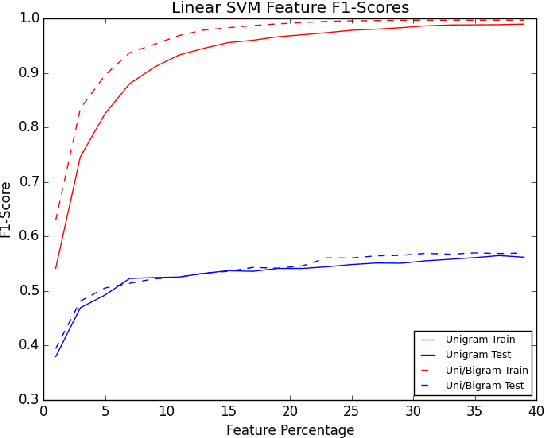
In this paper, we attempt to classify tweets into root categories of the Amazon browse node hierarchy using a set of tweets with browse node ID labels, a much larger set of tweets without labels, and a set of Amazon reviews. Examining twitter data presents unique challenges in that the samples are short (under 140 characters) and often contain misspellings or abbreviations that are trivial for a human to decipher but difficult for a computer to parse. A variety of query and document expansion techniques are implemented in an effort to improve information retrieval to modest success.
Exploring Correlation between Labels to improve Multi-Label Classification
Nov 25, 2015
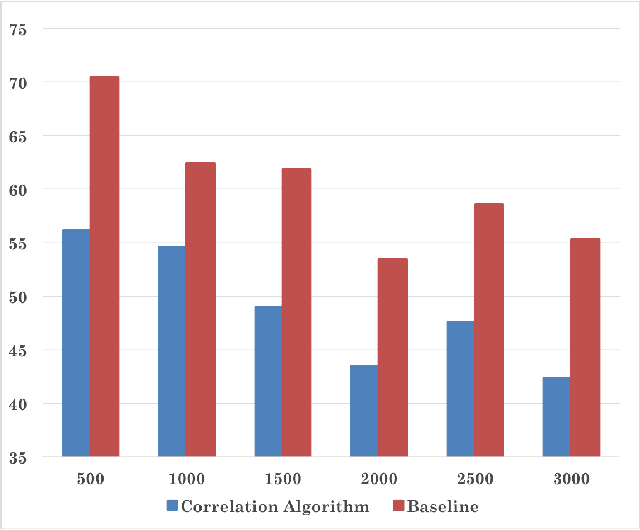
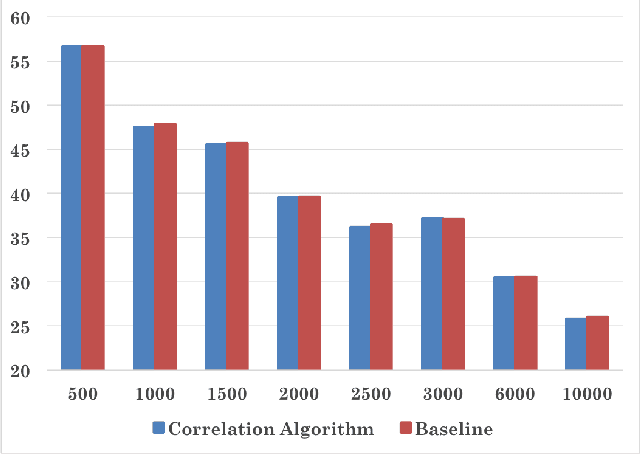
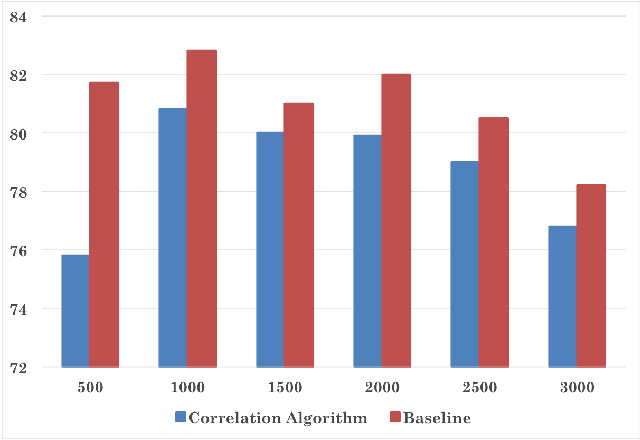
This paper attempts multi-label classification by extending the idea of independent binary classification models for each output label, and exploring how the inherent correlation between output labels can be used to improve predictions. Logistic Regression, Naive Bayes, Random Forest, and SVM models were constructed, with SVM giving the best results: an improvement of 12.9\% over binary models was achieved for hold out cross validation by augmenting with pairwise correlation probabilities of the labels.
RoboBrain: Large-Scale Knowledge Engine for Robots
Apr 12, 2015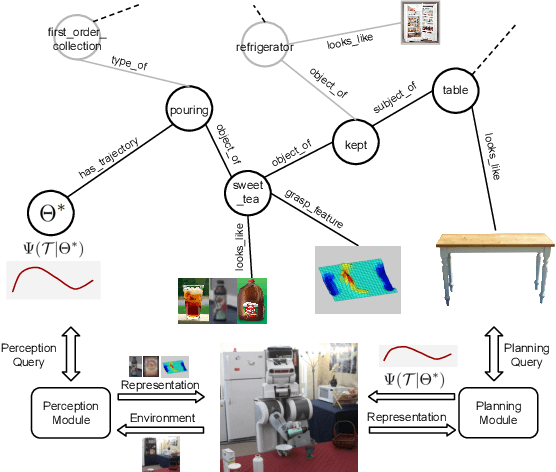
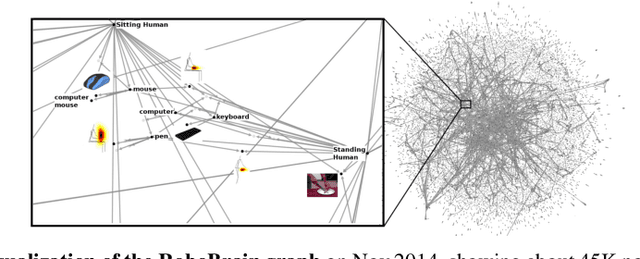
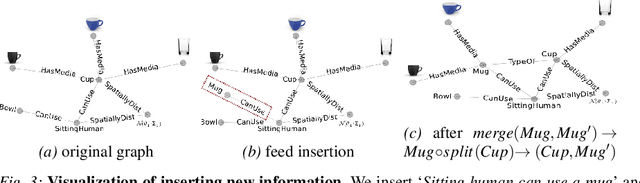
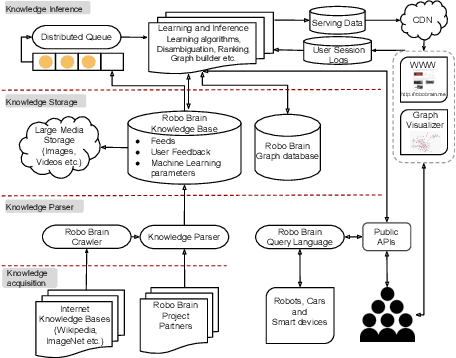
In this paper we introduce a knowledge engine, which learns and shares knowledge representations, for robots to carry out a variety of tasks. Building such an engine brings with it the challenge of dealing with multiple data modalities including symbols, natural language, haptic senses, robot trajectories, visual features and many others. The \textit{knowledge} stored in the engine comes from multiple sources including physical interactions that robots have while performing tasks (perception, planning and control), knowledge bases from the Internet and learned representations from several robotics research groups. We discuss various technical aspects and associated challenges such as modeling the correctness of knowledge, inferring latent information and formulating different robotic tasks as queries to the knowledge engine. We describe the system architecture and how it supports different mechanisms for users and robots to interact with the engine. Finally, we demonstrate its use in three important research areas: grounding natural language, perception, and planning, which are the key building blocks for many robotic tasks. This knowledge engine is a collaborative effort and we call it RoboBrain.