Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Correlation between Labels to improve Multi-Label Classification
Nov 25, 2015
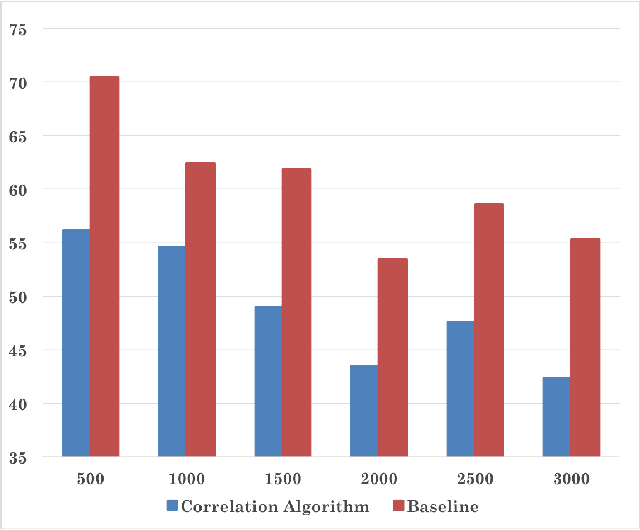
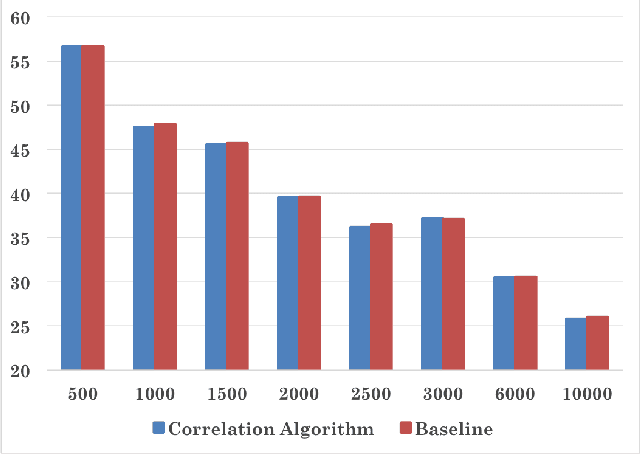
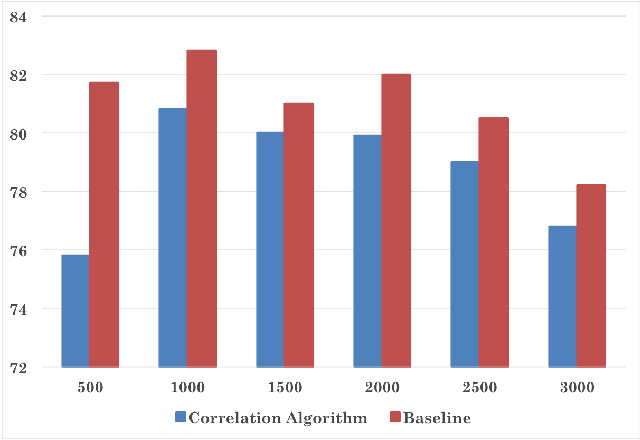
This paper attempts multi-label classification by extending the idea of independent binary classification models for each output label, and exploring how the inherent correlation between output labels can be used to improve predictions. Logistic Regression, Naive Bayes, Random Forest, and SVM models were constructed, with SVM giving the best results: an improvement of 12.9\% over binary models was achieved for hold out cross validation by augmenting with pairwise correlation probabilities of the labels.
Via