 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhyEduVideo: A Benchmark for Evaluating Text-to-Video Models for Physics Education
Jan 02, 2026Generative AI models, particularly Text-to-Video (T2V) systems, offer a promising avenue for transforming science education by automating the creation of engaging and intuitive visual explanations. In this work, we take a first step toward evaluating their potential in physics education by introducing a dedicated benchmark for explanatory video generation. The benchmark is designed to assess how well T2V models can convey core physics concepts through visual illustrations. Each physics concept in our benchmark is decomposed into granular teaching points, with each point accompanied by a carefully crafted prompt intended for visual explanation of the teaching point. T2V models are evaluated on their ability to generate accurate videos in response to these prompts. Our aim is to systematically explore the feasibility of using T2V models to generate high-quality, curriculum-aligned educational content-paving the way toward scalable, accessible, and personalized learning experiences powered by AI. Our evaluation reveals that current models produce visually coherent videos with smooth motion and minimal flickering, yet their conceptual accuracy is less reliable. Performance in areas such as mechanics, fluids, and optics is encouraging, but models struggle with electromagnetism and thermodynamics, where abstract interactions are harder to depict. These findings underscore the gap between visual quality and conceptual correctness in educational video generation. We hope this benchmark helps the community close that gap and move toward T2V systems that can deliver accurate, curriculum-aligned physics content at scale. The benchmark and accompanying codebase are publicly available at https://github.com/meghamariamkm/PhyEduVideo.
DOLOS: Tricking the Wi-Fi APs with Incorrect User Locations
Jul 23, 2024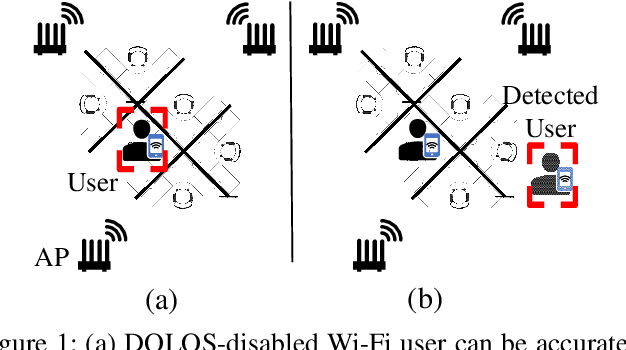
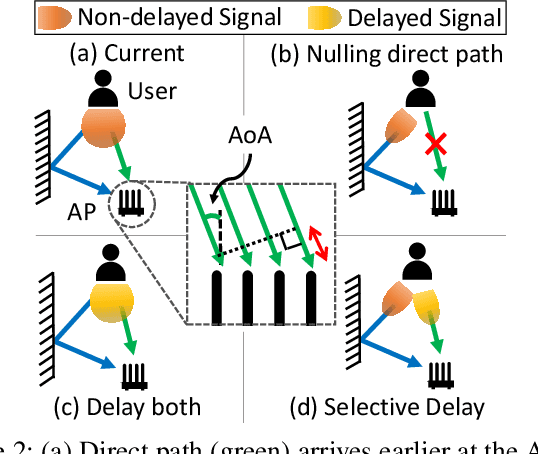
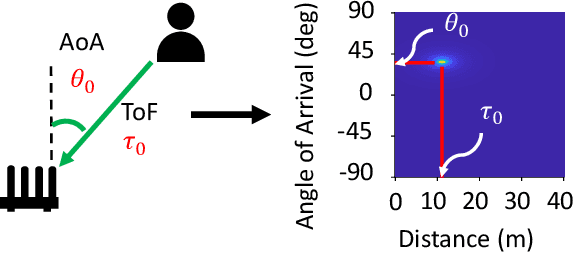
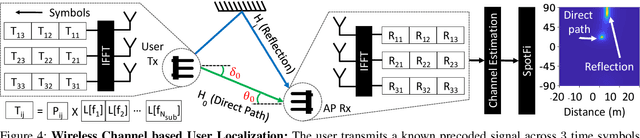
Wi-Fi-based indoor localization has been extensively studied for context-aware services. As a result, the accurate Wi-Fi-based indoor localization introduces a great location privacy threat. However, the existing solutions for location privacy protection are hard to implement on current devices. They require extra hardware deployment in the environment or hardware modifications at the transmitter or receiver side. To this end, we propose DOLOS, a system that can protect the location privacy of the Wi-Fi user with a novel signal obfuscation approach. DOLOSis a software-only solution that can be deployed on existing protocol-compliant Wi-Fi user devices. We provide this obfuscation by invalidating a simple assumption made by most localization systems -- "direct path signal arrives earlier than all the reflections to distinguish this direct path prior to estimating the location". However, DOLOS creates a novel software fix that allows the user to transmit the signal wherein this direct path arrives later, creating ambiguity in the location estimates. Our experimental results demonstrate DOLOS can degrade the localization accuracy of state-of-art systems by 6x for a single AP and 2.5x for multiple AP scenarios, thereby protecting the Wi-Fi user's location privacy without compromising the Wi-Fi communication performance.
XRLoc: Accurate UWB Localization for XR Systems
Jul 24, 2023Understanding the location of ultra-wideband (UWB) tag-attached objects and people in the real world is vital to enabling a smooth cyber-physical transition. However, most UWB localization systems today require multiple anchors in the environment, which can be very cumbersome to set up. In this work, we develop XRLoc, providing an accuracy of a few centimeters in many real-world scenarios. This paper will delineate the key ideas which allow us to overcome the fundamental restrictions that plague a single anchor point from localization of a device to within an error of a few centimeters. We deploy a VR chess game using everyday objects as a demo and find that our system achieves $2.4$ cm median accuracy and $5.3$ cm $90^\mathrm{th}$ percentile accuracy in dynamic scenarios, performing at least $8\times$ better than state-of-art localization systems. Additionally, we implement a MAC protocol to furnish these locations for over $10$ tags at update rates of $100$ Hz, with a localization latency of $\sim 1$ ms.
WiROS: WiFi sensing toolbox for robotics
May 22, 2023Many recent works have explored using WiFi-based sensing to improve SLAM, robot manipulation, or exploration. Moreover, widespread availability makes WiFi the most advantageous RF signal to leverage. But WiFi sensors lack an accurate, tractable, and versatile toolbox, which hinders their widespread adoption with robot's sensor stacks. We develop WiROS to address this immediate need, furnishing many WiFi-related measurements as easy-to-consume ROS topics. Specifically, WiROS is a plug-and-play WiFi sensing toolbox providing access to coarse-grained WiFi signal strength (RSSI), fine-grained WiFi channel state information (CSI), and other MAC-layer information (device address, packet id's or frequency-channel information). Additionally, WiROS open-sources state-of-art algorithms to calibrate and process WiFi measurements to furnish accurate bearing information for received WiFi signals. The open-sourced repository is: https://github.com/ucsdwcsng/WiROS
Users are Closer than they Appear: Protecting User Location from WiFi APs
Nov 18, 2022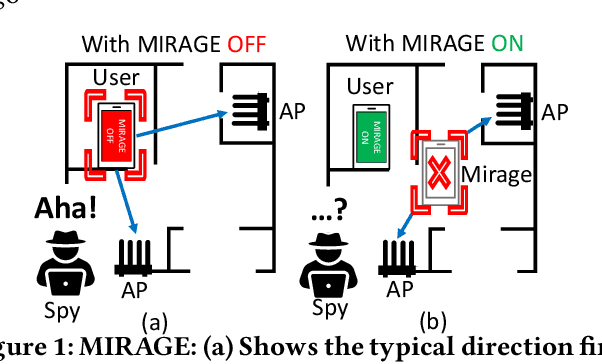
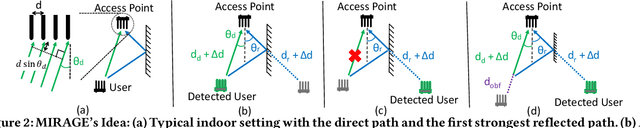
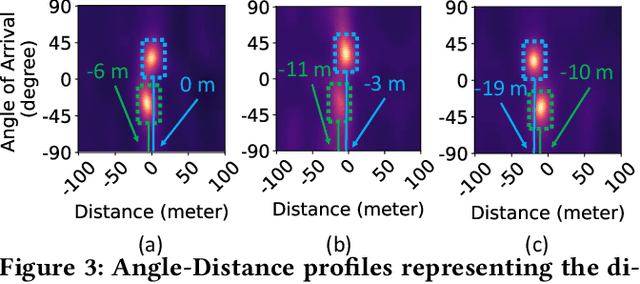

WiFi-based indoor localization has now matured for over a decade. Most of the current localization algorithms rely on the WiFi access points (APs) in the enterprise network to localize the WiFi user accurately. Thus, the WiFi user's location information could be easily snooped by an attacker listening through a compromised WiFi AP. With indoor localization and navigation being the next step towards automation, it is important to give users the capability to defend against such attacks. In this paper, we present MIRAGE, a system that can utilize the downlink physical layer information to create a defense against an attacker snooping on a WiFi user's location information. MIRAGE achieves this by utilizing the beamforming capability of the transmitter that is already part of the WiFi protocols. With this initial idea, we have demonstrated that the user can obfuscate his/her location from the WiFi AP always with no compromise to the throughput of the existing WiFi communication system and reduce the user location accuracy of the attacker from 2.3m to more than 10m.
ViWiD: Leveraging WiFi for Robust and Resource-Efficient SLAM
Sep 16, 2022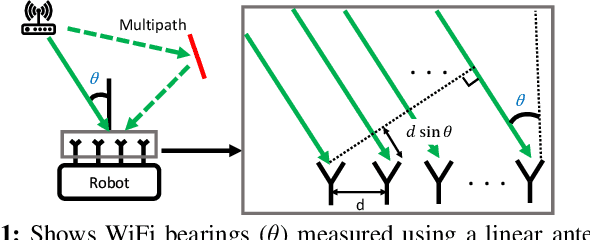
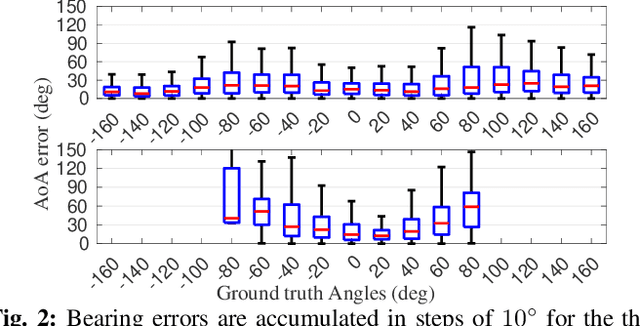
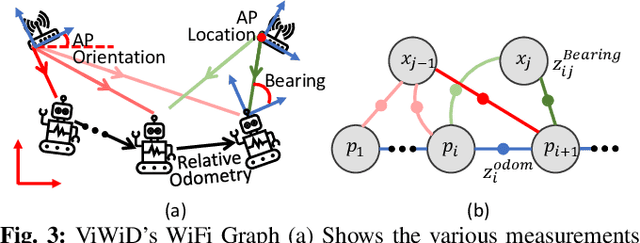

Recent interest towards autonomous navigation and exploration robots for indoor applications has spurred research into indoor Simultaneous Localization and Mapping (SLAM) robot systems. While most of these SLAM systems use Visual and LiDAR sensors in tandem with an odometry sensor, these odometry sensors drift over time. To combat this drift, Visual SLAM systems deploy compute and memory intensive search algorithms to detect `Loop Closures', which make the trajectory estimate globally consistent. To circumvent these resource (compute and memory) intensive algorithms, we present ViWiD, which integrates WiFi and Visual sensors in a dual-layered system. This dual-layered approach separates the tasks of local and global trajectory estimation making ViWiD resource efficient while achieving on-par or better performance to state-of-the-art Visual SLAM. We demonstrate ViWiD's performance on four datasets, covering over 1500 m of traversed path and show 4.3x and 4x reduction in compute and memory consumption respectively compared to state-of-the-art Visual and Lidar SLAM systems with on par SLAM performance.
Weakly Supervised Instance Segmentation by Learning Annotation Consistent Instances
Jul 18, 2020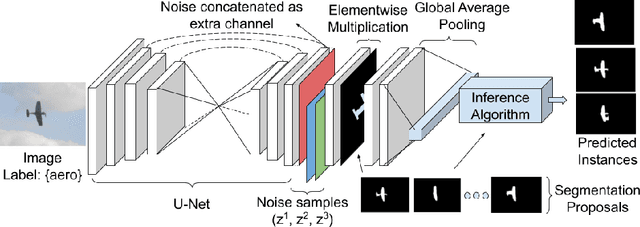
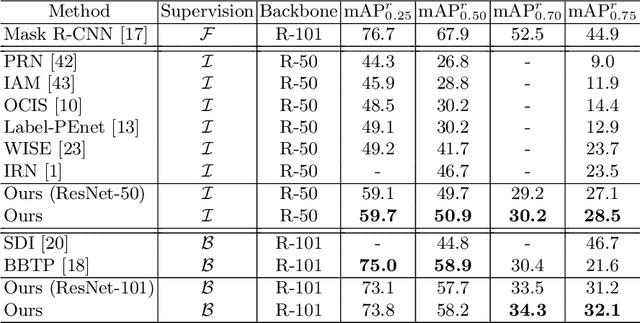


Recent approaches for weakly supervised instance segmentations depend on two components: (i) a pseudo label generation model that provides instances which are consistent with a given annotation; and (ii) an instance segmentation model, which is trained in a supervised manner using the pseudo labels as ground-truth. Unlike previous approaches, we explicitly model the uncertainty in the pseudo label generation process using a conditional distribution. The samples drawn from our conditional distribution provide accurate pseudo labels due to the use of semantic class aware unary terms, boundary aware pairwise smoothness terms, and annotation aware higher order terms. Furthermore, we represent the instance segmentation model as an annotation agnostic prediction distribution. In contrast to previous methods, our representation allows us to define a joint probabilistic learning objective that minimizes the dissimilarity between the two distributions. Our approach achieves state of the art results on the PASCAL VOC 2012 data set, outperforming the best baseline by 4.2% mAP@0.5 and 4.8% mAP@0.75.
Dissimilarity Coefficient based Weakly Supervised Object Detection
Nov 25, 2018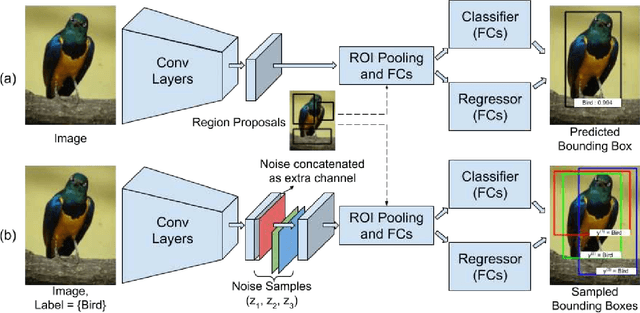
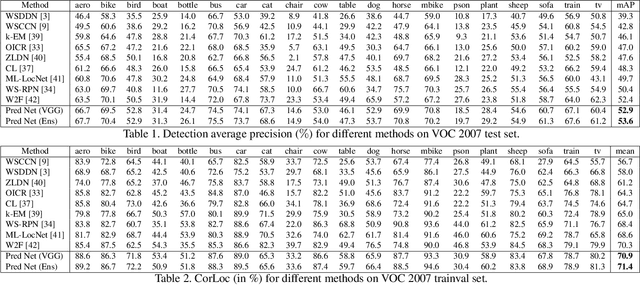

We consider the problem of weakly supervised object detection, where the training samples are annotated using only image-level labels that indicate the presence or absence of an object category. In order to model the uncertainty in the location of the objects, we employ a dissimilarity coefficient based probabilistic learning objective. The learning objective minimizes the difference between an annotation agnostic prediction distribution and an annotation aware conditional distribution. The main computational challenge is the complex nature of the conditional distribution, which consists of terms over hundreds or thousands of variables. The complexity of the conditional distribution rules out the possibility of explicitly modeling it. Instead, we exploit the fact that deep learning frameworks rely on stochastic optimization. This allows us to use a state of the art discrete generative model that can provide annotation consistent samples from the conditional distribution. Extensive experiments on PASCAL VOC 2007 and 2012 data sets demonstrate the efficacy of our proposed approach.
Learning Human Poses from Actions
Jul 24, 2018
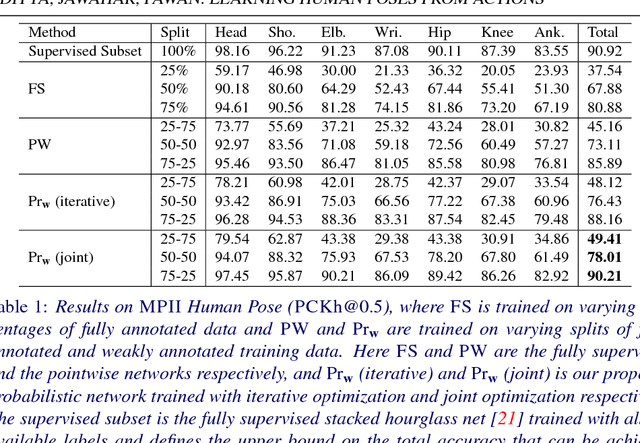
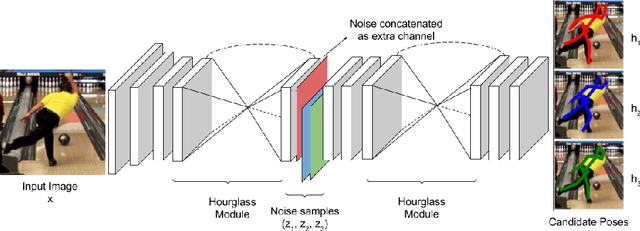
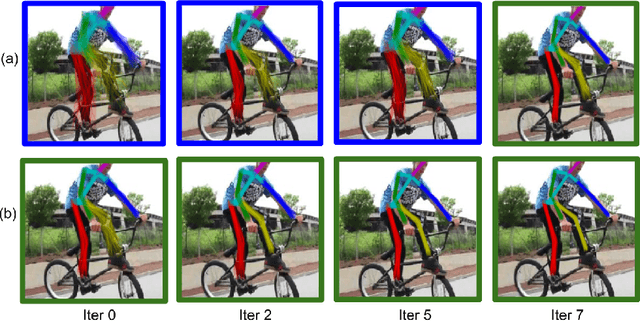
We consider the task of learning to estimate human pose in still images. In order to avoid the high cost of full supervision, we propose to use a diverse data set, which consists of two types of annotations: (i) a small number of images are labeled using the expensive ground-truth pose; and (ii) other images are labeled using the inexpensive action label. As action information helps narrow down the pose of a human, we argue that this approach can help reduce the cost of training without significantly affecting the accuracy. To demonstrate this we design a probabilistic framework that employs two distributions: (i) a conditional distribution to model the uncertainty over the human pose given the image and the action; and (ii) a prediction distribution, which provides the pose of an image without using any action information. We jointly estimate the parameters of the two aforementioned distributions by minimizing their dissimilarity coefficient, as measured by a task-specific loss function. During both training and testing, we only require an efficient sampling strategy for both the aforementioned distributions. This allows us to use deep probabilistic networks that are capable of providing accurate pose estimates for previously unseen images. Using the MPII data set, we show that our approach outperforms baseline methods that either do not use the diverse annotations or rely on pointwise estimates of the pose.