 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Human Poses from Actions
Paper and Code
Jul 24, 2018
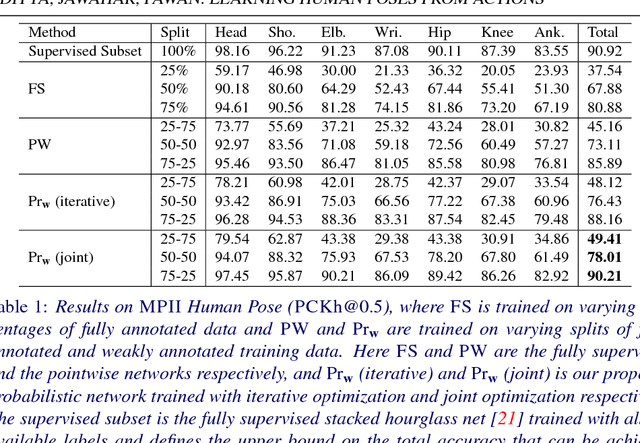
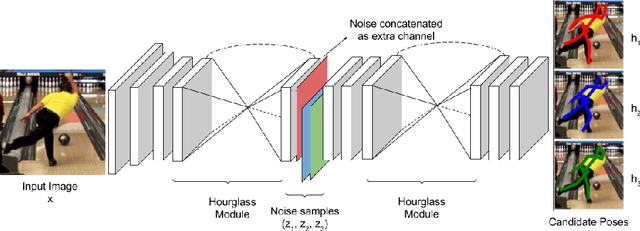
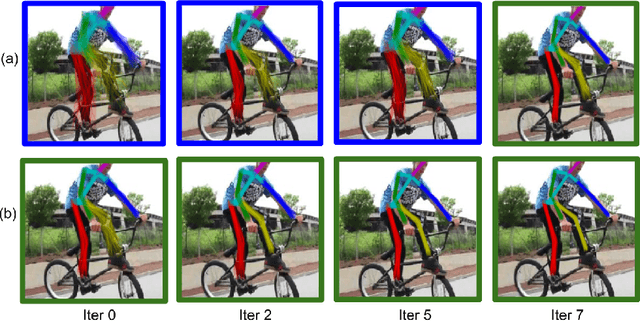
We consider the task of learning to estimate human pose in still images. In order to avoid the high cost of full supervision, we propose to use a diverse data set, which consists of two types of annotations: (i) a small number of images are labeled using the expensive ground-truth pose; and (ii) other images are labeled using the inexpensive action label. As action information helps narrow down the pose of a human, we argue that this approach can help reduce the cost of training without significantly affecting the accuracy. To demonstrate this we design a probabilistic framework that employs two distributions: (i) a conditional distribution to model the uncertainty over the human pose given the image and the action; and (ii) a prediction distribution, which provides the pose of an image without using any action information. We jointly estimate the parameters of the two aforementioned distributions by minimizing their dissimilarity coefficient, as measured by a task-specific loss function. During both training and testing, we only require an efficient sampling strategy for both the aforementioned distributions. This allows us to use deep probabilistic networks that are capable of providing accurate pose estimates for previously unseen images. Using the MPII data set, we show that our approach outperforms baseline methods that either do not use the diverse annotations or rely on pointwise estimates of the pose.